NVIDIA's 1.4 Billion Transistor GPU: GT200 Arrives as the GeForce GTX 280 & 260
by Anand Lal Shimpi & Derek Wilson on June 16, 2008 9:00 AM EST- Posted in
- GPUs
Tweaks and Enahancements in GT200
NVIDIA provided us with a list, other than the obvious addition of units and major enhancements in features and technology, of adjustments made from G80 to GT200. These less obvious changes are part of what makes this second generation Tesla architecture a well evolved G80. First up, here's a quick look at percent increases from G80 to GT200.
| NVIDIA Architecture Comparison | 8800 GTX | GTX 280 | % Increase |
| Cores | 128 | 240 | 87.5% |
| Texture | 64t/clk | 80t/clk | 25% |
| ROP Blend | 12p / clk | 32p / clk | 167% |
| Max Precision | fp32 | fp64 | |
| GFLOPs | 518 | 933 | 80% |
| FB Bandwidth | 86 GB/s | 142 GB/s | 65% |
| Texture Fill Rate | 37 GT/s | 48 GT/s | 29.7% |
| ROP Blend Rate | 7 GBL/s | 19 GBLs | 171% |
| PCI Express Bandwidth | 6.4 GB/s | 12.8GB/s | 100% |
| Video Decode | VP1 | VP2 |
Communication between the driver and the front-end hardware has been enhanced through changes to the communications protocol. These changes were designed to help facilitate more efficient data movement between the driver and the hardware. On G80/G92, the front-end could end up in contention with the "data assembler" (input assembler) when performing indexed primitive fetches and forced the hardware to run at less than full speed. This has been fixed with GT200 through some optimizations to the memory crossbar between the assembler and the frame buffer.
The post-transform cache size has been increased. This cache is used to hold transformed vertex and geometry data that is ready for the viewport clip/cull stage, and increasing the size of it has resulted in faster communication and fewer pipeline stalls. Apparently setup rates are similar to G80 at up to one primative per clock, but feeding the setup engine is more efficient with a larger cache.
Z-Cull performance has been improved, while Early-Z rejection rates have increased due to the addition of more ROPs. Per ROP, GT200 can eliminate 32 pixles (or up to 256 samples with 8xAA) per clock.
The most vague improvement we have on the list is this one: "significant micro-architectural improvements in register allocation, instruction scheduling, and instruction issue." These are apparently the improvements that have enabled better "dual-issue" on GT200, but that's still rather vague as to what is actually different. It is mentioned that scheduling between the texture units and SMs within a TPC has also been improved. Again, more detail would be appreciated, but it is at least worth noting that some work went into that area.
Register Files? Double Em!
Each of those itty-bitty SPs is a single-core microprocessor, and as such it has its own register file. As you may remember from our CPU architecture articles, registers are storage areas used to directly feed execution units in a CPU core. A processor's register file is its collection of registers and although we don't know the exact number that were in G80's SPs, we do know that the number has been doubled for GT200.
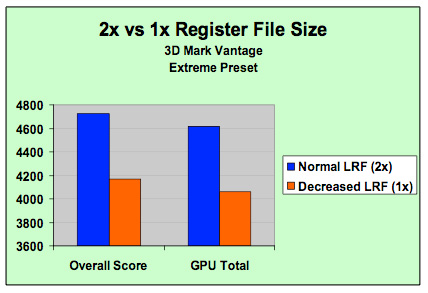
NVIDIA's own data shows a greater than 10% increase in performance due to the larger register file size (source: NVIDIA)
If NVIDIA is betting that games are going to continue to get more compute intensive, then register file usage should increase as well. More computations means more registers in use, which in turn means that there's a greater likelihood of running out of registers. If a processor runs out of registers, it needs to start swapping data out to much slower memory and performance suffers tremendously.
If you haven't gotten the impression that NVIDIA's GT200 is a compute workhorse, doubling the size of the register file per SP (multiply that by 240 SPs in the chip) should help drive the idea home.
Double the Precision, 1/8th the Performance
Another major feature of the GT200 GPU and cards based on it is support for hardware double precision floating point operations. Double precision FP operations are 64-bits wide vs. 32-bit for single precision FP operations.
Now the 240 SPs in GT200 are single-precision only, they simply can't accept 64-bit operations at all. In order to add hardware level double precision NVIDIA actually includes one double precision unit per shading multiprocessor, for a total of 30 double precision units across the entire chip.
The ratio of double precision to single precision hardware in GT200 is ridiculously low, to the point that it's mostly useless for graphics rasterization. It is however, useful for scientific computing and other GPGPU applications.
It's unlikely that 3D games will make use of double precision FP extensively, especially given that 8-bit integer and 16-bit floating point are still used in many shader programs today. If anything, we'll see the use of DP FP operations in geometry and vertex operations first, before we ever need that sort of precision for color - much like how the transition to single precision FP started first in vertex shaders before eventually gaining support throughout the 3D pipeline.
Geometry Wars
ATI's R600 is alright at geometry shading. So is RV670. G80 didn't really keep up in this area. Of course, games haven't really made extensive use of geometry shaders because neither AMD nor NVIDIA offered compelling performance and other techniques made more efficient use of the hardware. This has worked out well for NVIDIA so far, but they couldn't ignore the issue forever.
GT200 has enhanced geometry shading support over G80 and is now on par with what we wish we had seen last year. We can't fault NVIDIA too much as with such divergent new features they had to try and predict the usage models that developers might be interested in years in advance. Now that we are here and can see what developers want to do with geometry shading, it makes sense to enhance the hardware in ways that support these efforts.
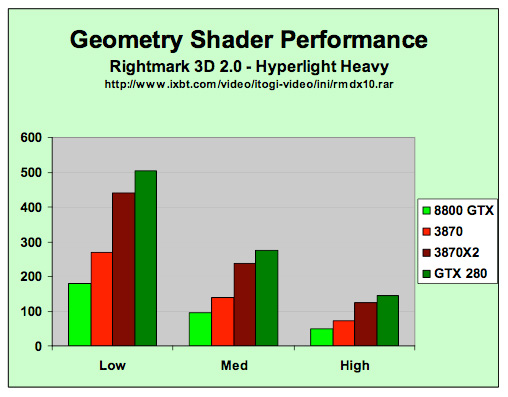
GT200 has significantly improved geometry shader performance compared to G80 (source: NVIDIA)
Generation of vertex data is a particularly weak part of NVIDIA's G80, so GT200 is capable of streaming out 6x the data of G80. Of course there are the scheduling enhancements that affect everything, but it is unclear as to whether NVIDIA did anything beyond increasing the size of their internal output buffers by 6x in order to enhance their geometry shading capability. Certainly this was lacking previously, but hopefully this will make heavy use of the geometry shader something developers are both interested in and can take advantage of.








108 Comments
View All Comments
junkmonk - Monday, June 16, 2008 - link
I can has vertex data? LMFAO, hahha that was a good laugh.PrinceGaz - Monday, June 16, 2008 - link
When I looked at that, I assumed it must be a non-native English speaker who put that in the block. I'm still not entirely sure what it was trying to convey other than that the core will need to be fed with lots of vertices to keep it busy.Spoelie - Tuesday, June 17, 2008 - link
http://icanhascheezburger.com/">http://icanhascheezburger.com/http://icanhascheezburger.com/tag/cheezburger/">http://icanhascheezburger.com/tag/cheezburger/
chizow - Monday, June 16, 2008 - link
Its going to take some time to digest it all, but you two have done it again with a massive but highly readable write-up of a new complex microchip. You guys are still the best at what you do, but a few points I wanted to make:1) THANK YOU for the clock-for-clock comparo with G80. I haven't fully digested the results, but I disagree with your high-low increase thresholds being dependent on solely TMU and SP. You don't mention GT200 has 33% more ROP as well which I think was the most important addition to GT200.
2) The SP pipeline discussion was very interesting, I read through 3/4 of it and glanced over the last few paragraphs and it didn't seem like you really concluded the discussion by drawing on the relevance of NV's pipeline design. Is that why NV's SPs are so much better than ATI's, and why they perform so well compared to deep piped traditional CPUs? What I gathered was that NV's pipeline isn't nearly as rigid or static as traditional pipelines, meaning they're more efficient and less dependent on other data in the pipe.
3) I could've lived without the DX10.1 discussion and more hints at some DX10.1 AC/TWIMTBP conspiracy. You hinted at the main reason NV wouldn't include DX10.1 on this generation (ROI) then discount it in the same breath and make the leap to conspiracy theory. There's no doubt NV is throwing around market share/marketing muscle to make 10.1 irrelevant but does that come as any surprise if their best interest is maximizing ROI and their current gen parts already outperform the competition without DX10.1?
4) CPU bottlenecking seems to be a major issue in this high-end of GPUs with the X2/SLI solutions and now GT200 single-GPUs. I noticed this in a few of the other reviews where FPS results were flattening out at even 16x12 and 19x12 resolutions with 4GHz C2D/Qs. You'll even see it in a few of your benches at those higher (16/19x12) resolutions in QW:ET and even COD4 and those were with 4x AA. I'm sure the results would be very close to flat without AA.
That's all I can think of for now, but again another great job. I'll be reading/referencing it for the next few days I'm sure. Thanks again!
OccamsAftershave - Monday, June 16, 2008 - link
"If NVIDIA put the time in (or enlisted help) to make CUDA an ANSI or ISO standard extention to a programming language, we would could really start to get excited."Open standards are coming. For example, see Apple's OpenCL, coming in their next OS release.
http://news.yahoo.com/s/nf/20080612/bs_nf/60250">http://news.yahoo.com/s/nf/20080612/bs_nf/60250
ltcommanderdata - Monday, June 16, 2008 - link
At least AMD seems to be moving toward standardizing their GPGPU support.http://www.amd.com/us-en/Corporate/VirtualPressRoo...">http://www.amd.com/us-en/Corporate/VirtualPressRoo...
AMD has officially joined Apple's OpenCL initiative under the Khronos Compute Working Group.
Truthfully, with nVidia's statements about working with Apple on CUDA in the days leading up to WWDC, nVidia is probably on board with OpenCL too. It's just that their marketing people probably want to stick with their own CUDA branding for now, especially for the GT200 launch.
Oh, and with AMD's launch of the FireStream 9250, I don't suppose we could see benchmarks of it against the new Tesla?
paydirt - Monday, June 16, 2008 - link
tons of people reading this article and thinking "well, performance per cost, it's underwhelming (as a gaming graphics card)." What people are missing is that GPUs are quickly becoming the new supercomputers.ScythedBlade - Monday, June 16, 2008 - link
Lol ... anyone else catch that?Griswold - Monday, June 16, 2008 - link
Too expensive, too power hungry and according to other reviews, too loud for too little gain.The GT200 could become Nvidias R600.
Bring it on AMD, this is your big chance!
mczak - Monday, June 16, 2008 - link
G92 does not have 6 rop partitions - only 4 (this is also wrong in the diagram). Only G80 had 6.And please correct that history rewriting - that the FX failed against radeon 9700 had NOTHING to do with the "powerful compute core" vs. the high bandwidth (ok the high bandwidth did help), in fact quite the opposite - it was slow because the "powerful compute core" was wimpy compared to the r300 core. It definitely had a lot more flexibility but the compute throughput simply was more or less nonexistent, unless you used it with pre-ps20 shaders (where it could use its fx12 texture combiners).