SUN’s UltraSparc T1 - the Next Generation Server CPUs
by Johan De Gelas on December 29, 2005 10:03 AM EST- Posted in
- CPUs
Introduction
SUN's Ultrasparc T1, formerly known as Niagara, is much more than just a new UltraSparc. It is the harbinger of a new generation of CPUs, which focus almost solely on Thread Level Parallelism. No less than 32 independent parts of a different program (threads) can be "in flight" on the chip. It is SUN's first implementation of their Throughput computing philosophy, and compared to what we are used to in the AMD/Intel world, it is a pretty extreme architecture that focuses on network and server performance.
Stubborn Server applications
The basic idea behind the UltraSparc T1 is that most modern superscalar Out-Of-Order CPUs may be excellent for games, digital content creation and scientific calculations, but they are not a good match for commercial server loads.
These complex CPUs can decode up to 3 (Opteron) to 8 (Power 5) instructions in parallel, put in a buffer and try to issue them across 9 or more units. In theory, these CPUs can decode, issue, execute and retire up to 3 (Opteron) to 5 (IBM Power) instructions per clock cycle. They have huge buffers (up to 200 instructions) to keep many instructions in flight.
Server workloads, however, cannot make good use of all this parallelism for several reasons. The main reason is that commercial server loads move a lot of data around and perform relatively little calculation on that data. Moving a lot of data around means that you may need a lot of accesses to the memory, which results in many cycles wasted while the CPU has to wait for the data to arrive. As many different users query different parts of the database, caching cannot be as efficient (low locality of reference). In the past years, memory latency has become worse as memory speed increased a lot slower than the speed of the CPU. Memory latency is even worse on MP (Multi-Processor) systems, and has risen from a few tens of CPU cycles to 200-400 clock cycles. The second reason is that many of the calculations performed on that data involve data dependent (read: hard to predict) branches, which makes it even harder to do a lot in parallel.
You might counter these two problems by eliminating the branches through predication and incorporate very large caches. That is what the Itanium family does, but even the mighty Itanium is not capable of running those server loads at high speeds despite predication and gigantic caches. Below, you can see Intel's own numbers for CPU utilization on the 3 different workloads.
The applications that can be found inside Spec Integer benchmark are still rather compute-intensive compared to server applications. Compression, FPGA Circuit Placement and Routing, Compiling and interpreting, and computer visualization are representatives of very CPU intensive integer loads. On average, the best desktop CPUs such as the Athlon 64 or Intel Dothan are capable of sustaining 0.8 to 1 instructions per clock cycle in this benchmark, while the Pentium 4 is around 0.5-0.7 IPC. Itanium is capable of a 1.3-1.5 IPC. That may sound like very low numbers, but let us compare SpecInt with typical server loads. In the table below, you find how the 4-way superscalar USIIIi does on the various benchmarks.
Rather than focus on the absolute numbers, it is more important to note that web applications have 3 times less IPC than CPU intensive integer apps. OLTP databases (TPC-C) do even worse: the CPU sustains on average 0.2 instructions per clock pulse, or 4.5 less than SpecInt. These numbers are no different for the Opteron or Xeon. So despite Out of Order execution, nifty branch prediction schemes and big caches, commercial server loads utilize a very meagre 10 to 15% of the potential of modern CPUs.
One possible solution is to focus on clock speed instead of trying to process as many instructions in parallel (ILP, instruction level parallelism). The long pipelines of such CPUs make the branch prediction problem worse, and the power consumption goes up exponentially as we discussed in a previous article about dynamic power and power leakage.
SUN's Ultrasparc T1, formerly known as Niagara, is much more than just a new UltraSparc. It is the harbinger of a new generation of CPUs, which focus almost solely on Thread Level Parallelism. No less than 32 independent parts of a different program (threads) can be "in flight" on the chip. It is SUN's first implementation of their Throughput computing philosophy, and compared to what we are used to in the AMD/Intel world, it is a pretty extreme architecture that focuses on network and server performance.

Fig 1. The 2U SUN T2000
Stubborn Server applications
The basic idea behind the UltraSparc T1 is that most modern superscalar Out-Of-Order CPUs may be excellent for games, digital content creation and scientific calculations, but they are not a good match for commercial server loads.
These complex CPUs can decode up to 3 (Opteron) to 8 (Power 5) instructions in parallel, put in a buffer and try to issue them across 9 or more units. In theory, these CPUs can decode, issue, execute and retire up to 3 (Opteron) to 5 (IBM Power) instructions per clock cycle. They have huge buffers (up to 200 instructions) to keep many instructions in flight.
Server workloads, however, cannot make good use of all this parallelism for several reasons. The main reason is that commercial server loads move a lot of data around and perform relatively little calculation on that data. Moving a lot of data around means that you may need a lot of accesses to the memory, which results in many cycles wasted while the CPU has to wait for the data to arrive. As many different users query different parts of the database, caching cannot be as efficient (low locality of reference). In the past years, memory latency has become worse as memory speed increased a lot slower than the speed of the CPU. Memory latency is even worse on MP (Multi-Processor) systems, and has risen from a few tens of CPU cycles to 200-400 clock cycles. The second reason is that many of the calculations performed on that data involve data dependent (read: hard to predict) branches, which makes it even harder to do a lot in parallel.
You might counter these two problems by eliminating the branches through predication and incorporate very large caches. That is what the Itanium family does, but even the mighty Itanium is not capable of running those server loads at high speeds despite predication and gigantic caches. Below, you can see Intel's own numbers for CPU utilization on the 3 different workloads.
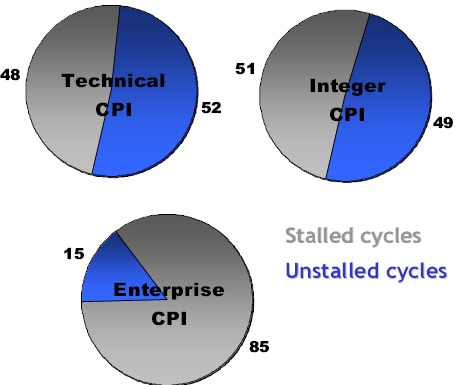
Fig 2: Intel reporting the percentage of stalled cycles of different applications on the Itanium 2 family. Source:Intel.
The applications that can be found inside Spec Integer benchmark are still rather compute-intensive compared to server applications. Compression, FPGA Circuit Placement and Routing, Compiling and interpreting, and computer visualization are representatives of very CPU intensive integer loads. On average, the best desktop CPUs such as the Athlon 64 or Intel Dothan are capable of sustaining 0.8 to 1 instructions per clock cycle in this benchmark, while the Pentium 4 is around 0.5-0.7 IPC. Itanium is capable of a 1.3-1.5 IPC. That may sound like very low numbers, but let us compare SpecInt with typical server loads. In the table below, you find how the 4-way superscalar USIIIi does on the various benchmarks.
| Benchmark | IPC |
| SPECint | 0.9 |
| SPECjbb | 0.5 |
| SPECweb | 0.3 |
| TPC-C | 0.2 |
Rather than focus on the absolute numbers, it is more important to note that web applications have 3 times less IPC than CPU intensive integer apps. OLTP databases (TPC-C) do even worse: the CPU sustains on average 0.2 instructions per clock pulse, or 4.5 less than SpecInt. These numbers are no different for the Opteron or Xeon. So despite Out of Order execution, nifty branch prediction schemes and big caches, commercial server loads utilize a very meagre 10 to 15% of the potential of modern CPUs.
One possible solution is to focus on clock speed instead of trying to process as many instructions in parallel (ILP, instruction level parallelism). The long pipelines of such CPUs make the branch prediction problem worse, and the power consumption goes up exponentially as we discussed in a previous article about dynamic power and power leakage.








49 Comments
View All Comments
thesix - Thursday, December 29, 2005 - link
"Hypervisor" is a technology used mostly by IBM from mainframe days. Every system vendor can implement this technology in their systems.pmurphy - Thursday, December 29, 2005 - link
Actually lets start by saying you're missed on aceshardware.. and I do have to wonder how you felt about the oath of allegiance to Intel anandtech requires?Ah well, all that aside the most glaring omission with respect to the Niagara II is the fact that it has a full floating point component in each core - meaning that the current floating point limitation will largely go away.
In addition: you cite (as a lot of other people do to) this 1.2Ghz "maximum" as if it had reality - it does not. As issued, the T1 incorporates some design trade-offs that make higher cycle rates impractical, but those are the result of engineering vs. marketing (time and cost) trade-offs, not inherent consequences of the technology. Sun has faster test units running now - with very high end products in the pipeline.
defter - Thursday, December 29, 2005 - link
"Ah well, all that aside the most glaring omission with respect to the Niagara II is the fact that it has a full floating point component in each core - meaning that the current floating point limitation will largely go away."Floating point limitation won't go away, 8 FPUs@1.4GHz will just make floating point capabilities of the chip somehow useful. For the comparison dual-core Opteron has 6 FPUs@2.4GHz NOW and in 2007 there will be quad-core Opterons (12 FPUs) available.
As somebody already mentioned, performance/$ is also very important. While T1 is way faster than any other chip, I guess it will cost much more, probably more than 2 high end dual-core Opterons.
I'm not saying that T1 isn't good. It is, but only in certain tasks.
JohanAnandtech - Thursday, December 29, 2005 - link
I don't think it is a tradition at Anandtech to swear allegiance to Intel, or either they have forgotten to tell me.:-)All jokes aside, When I say Intel has the advantage on hardware VT technology and the software support needed, that is solely based on facts. Sun is actively trying to get full support of Xen (VM), and also Linux and FreeBSD OS support, but for the moment T1 is Solaris only if you want good software support.
AFAIK there is no indication that SUN can go much faster than 1.2 GHz. To let the 4 threads access a 5.7 KB register file in one cycle is probably limiting the clockspeed, and the 6 stage pipeline is another clear indication that this CPU won't clock much higher. SUN counting on 65 nm to increase the clockspeed higher (1.4 GHz and more) is another indication.
ravedave - Thursday, December 29, 2005 - link
When might we expect to see Anandtech benchmarks? 1-2 months?Puddleglum - Thursday, December 29, 2005 - link
The [2] SUN T1 benchmarks reference link is pointing to a bizarre location at intel.com. The text says sun.com, but the link points to intel.com.It should be fixed to point to: http://www.sun.com/servers/coolthreads/t1000/bench...">http://www.sun.com/servers/coolthreads/t1000/bench...
ncage - Thursday, December 29, 2005 - link
It looks like sun is back with a vengance. This thing seems perfect for the server market. I am really suprised that they were able to get their $hit back together. I dought the single threaded performance on this thing would be that great but, then again, who cares this thing is a server not a workstation made for single threaded use. This thing would be perfect for virtualization. I don't know if this is possible for solaris or maybe vmware/ms virtual server will have this feature in the future but hopefully they will allow you to allocate which core to which virtualization layer that you want. So say your running 4 OS and you have 8 cores. You allocate 2 cores to each OS. You notice that 2 of the four high really high cpu utilization. You could then dynamically add one more core to each of the virtualized OS that had high cpu usage from the ones that had low cpu usage. For those of you who think virtualization isn't a big deal...now wouldnt' this be cool.Slaimus - Thursday, December 29, 2005 - link
Are these benchmarks all running similar TCP/IP stacks? We all know solaris 10 has a new TCP/IP stack that is much faster than linux.Puddleglum - Thursday, December 29, 2005 - link
The benchmarks are from Sun's website (http://www.sun.com/servers/coolthreads/t1000/bench...">link)"SPECjAppServer2004 is the only industry-standard benchmark used for Java Enterprise Edition application servers."
So, yes, you can assume they're all using the same TCP/IP stack. But, as the article mentions: "Of course, this is an ideal benchmark for the T1 with many java threads."