SUN’s UltraSparc T1 - the Next Generation Server CPUs
by Johan De Gelas on December 29, 2005 10:03 AM EST- Posted in
- CPUs
The 8 little cores that could
Each core is pretty small, as it has only one pipeline, no Branch Prediction Unit, no OOO buffers, and no OOO pipeline stages, which search for independent instructions. Only the large register file and thread select logic make the very simple core a bit fatter and more complex.
An 8 KB data cache and 16 KB instruction cache give an L1-hitrate of 90% or less, but it also helps to keep each core small. To keep 8 cores with such tiny L1-caches running at 70% efficiency with so many threads, a big L2-cache and massive memory bandwidth is needed.
We have quantified this effect of faster cache coherency in our Linux database server article. A dual core Opteron was about 13% faster than two single core CPUs at the same clock speed. With 8 cores that might share data, cache coherency has an even bigger impact on performance. Sharing the L2-cache also ensures that no coherency traffic is necessary on the level 2 cache.
There is more. Each core has a modular arithmetic unit (MAU) that supports modular multiplication and exponentiation to speed up Secure Sockets Layer (SSL) processing. This compensates for the lack of the FPU and the low clock speed. A single 1.2 GHz MAU seems to "sign" as fast as a 1.8 GHz Opteron, but quite a bit slower at verifying authenticity.
Each core is pretty small, as it has only one pipeline, no Branch Prediction Unit, no OOO buffers, and no OOO pipeline stages, which search for independent instructions. Only the large register file and thread select logic make the very simple core a bit fatter and more complex.
An 8 KB data cache and 16 KB instruction cache give an L1-hitrate of 90% or less, but it also helps to keep each core small. To keep 8 cores with such tiny L1-caches running at 70% efficiency with so many threads, a big L2-cache and massive memory bandwidth is needed.
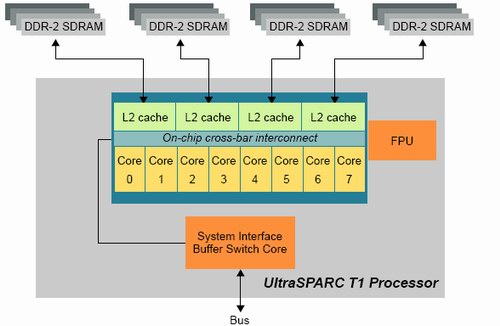
Fig 5: 8 cores fed by a 3 MB L2-cache and 4 integrated memory controllers. Source:SUN.
We have quantified this effect of faster cache coherency in our Linux database server article. A dual core Opteron was about 13% faster than two single core CPUs at the same clock speed. With 8 cores that might share data, cache coherency has an even bigger impact on performance. Sharing the L2-cache also ensures that no coherency traffic is necessary on the level 2 cache.
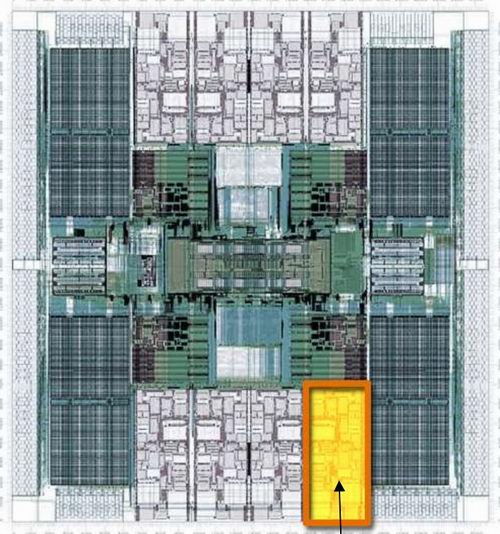
Fig 6: One (yellow) of the 8 cores (gray) of the T1. Source:SUN.
As a rough guideline, performance degrades if the number of floating-point instructions exceeds 1 percent of total instructions.Some instructions like division have long latencies, causing the thread to be skipped. The situation is then similar to a thread with a long latency load. To keep power consumption and die size per core low, each core has a very shallow six-stage pipeline: fetch, thread select, decode, execute, memory, and write back. The result is an architecture that does not need branch prediction, thanks to a shallow pipeline and FMT. However, this limits clock speed to 1.2 GHz in 90 nm, while competing chips are clocking between 2 and 4 GHz.
There is more. Each core has a modular arithmetic unit (MAU) that supports modular multiplication and exponentiation to speed up Secure Sockets Layer (SSL) processing. This compensates for the lack of the FPU and the low clock speed. A single 1.2 GHz MAU seems to "sign" as fast as a 1.8 GHz Opteron, but quite a bit slower at verifying authenticity.








49 Comments
View All Comments
Brian23 - Saturday, December 31, 2005 - link
While it's true that HT helps fight this issue, it's not the complete solution. Sun's approach is much better.Betwon - Thursday, December 29, 2005 - link
How terrible!The single issue pipeline/core!
Poeple always complains that: we fails to find the enough threads(2 or 4 threads) in the most apps for the multi-thread CPU.
Now, it is very difficult to find a app(8X4=32 threads parallel well).
Calin - Tuesday, January 3, 2006 - link
It is hard to find parallelism in one application so you could run it well on two cores. However, if you use 32 applications, you can run it very well on 32 cores.JarredWalton - Thursday, December 29, 2005 - link
Most servers don't run a lot of single-threaded apps, or if they do they run many instances of the single-threaded app/process at the same time. This is clearly not a chip designed for all markets, but it is instead focused on doing very well in a niche market.thesix - Thursday, December 29, 2005 - link
Johan,Nice article!
A small point: I don't think it's correct to refer Sun Microsystems Inc. as 'SUN', it should be 'Sun'.
Even though it originally stands for Standford University Network, 'SUN' is no longer the semi-official name, AFAIK.
When T1 based system is announced, I was hoping to see some independent benchmarks from Anandtech, especially the MySQL one you guys used to benchmark the server performance.
I know it's not scientific, and SPEC is as good as it gets, still I am curious :-)
Have you guys considered using T1000/T2000 to power Anandtech, given it's so cheap and designed for webserver type of workload?
That would be a good win-back story for Sun, I remembered you guys migraded from Sun Ultra boxes to PC server several years ago :-)
steveha - Thursday, December 29, 2005 - link
Why drop the opteron from the Specweb2005 results? Did it destroy the T1?stephenbrooks - Monday, January 2, 2006 - link
We think we should be told.NullSubroutine - Thursday, December 29, 2005 - link
How do these price? It seems the performance per watt is very good, but what if the cpu and the platform costs more?I might have missed it, but what was the die size?
icarus4586 - Thursday, December 29, 2005 - link
I'm assuming that should read,
I wouldn't guess Sun is using IBM technology or marketing terms.
JohanAnandtech - Thursday, December 29, 2005 - link
As thesix already commented (thanks :-), hypervisor is indeed IBM talk. AFAIK, IBM was first.