Itanium - is there light at the end of the tunnel?
by Johan De Gelas on November 9, 2005 12:05 AM EST- Posted in
- CPUs
The limits of TLP...
Hardware engineers do not believe in massive superscalar CPUs anymore[2]. Increasing ILP a tiny bit requires exponentially bigger out-of-order hardware, which exponentially requires more power.
TLP and multi-core is hot and trendy. But the same problems that were true for squeezing ILP out of hardware are true about TLP in software. On the exception of naturally parallel applications such as rendering and database servers, getting more and more threads out of the majority of hardware will require exponentially more programming and debugging time. There are more high TLP designs such as Sun's Niagara that increase throughput, but also response time. And while the numbers of users that can update and read the database matters, the response time of the database can be important too. For example, while OLTP loads consist of many relatively simple SQL selects, Decision Support Systems (DSS or OLAP) fire off very complex queries with a high response time. To offer a good "data mining" experience, the single thread performance must not be neglected. The same can be said for some HPC and many typical workstation applications.
So, while designs that sacrifice ILP completely on the altar of TLP, such as Sun's Niagara, they may well be very popular in some markets such as webserving. Single thread performance is going to make the difference between the different multi-core solutions.
Here, the Itanium can leverage two big advantages: higher ILP and smaller cores. This last comment might seem ridiculous, given that the current Itanium Madison is about 432 mm2 large. However, if we look at the core (L1 inclusive), there about 25 million transistors that take about 80 mm2 die space. Note that the pictures below have been scaled and resized to reflect the relative proportions of the different cores.
Itanium: a slim figure
We compare the different CPU cores in the table below. We consider the L1-cache being part of the core, but we list the number of transistors separately to be clear. To keep it fair, we compare all CPU using the same process technologies, 0.13µ, with the exception of the Intel Xeon.
There is no doubt that a 0.13µ Xeon MP is no match for either of the IBM Power 5, the Itanium or Opteron with both Spec FP2000 and SpecInt around 1200 for a Xeon MP 3 GHz. The Xeon MP 0.13µ is also a 32 bit CPU, so it does not belong in the list below.
The reason why I listed the 90nm Xeon (DP) is to show how complex an x86 architecture can get when it has 64 bit and an extremely deep pipeline in a quest for high clock speeds, which must negate the low ILP. With more than 50 million transistors, it is no wonder that Xeon "Irwindale/Nocona" is the hottest CPU (per core) of the bunch despite being manufactured in a more advanced process.
Why do we use Spec FP2000 and Spec Int2000[3]? It is true that these benchmarks are close to meaningless when you want to compare server or workstation performance in the real world. Spec FP is a decent predictor of HPC/scientific performance, but fails to predict Digital Content Creation performance despite containing a few OpenGL benchmarks. The reason why we use these two benchmarks is that currently, we are evaluating the CPU architecture, its future potential and current compiler performance, and not the complete system.
* per core, two cores: about 70 million transistors
** for two cores
To calculate the cache sizes, we used the following formula:
HP and Intel have stated that the Itanium 2 core, including the L2-cache, has about 40 million transistors. If we subtract the L2 cache, we end up with about 26 million transistors, which still includes the x86 compatibility transistors (about 4 million) and the L2-tag. It wouldn't be fair to include the x86 transistors when we compare the merits of EPIC with x86 and RISC.
And, what about the Pentium M? Well, the core is about 25 million transistors, but it is pretty hard to compare this CPU with Itanium as the Pentium M is optimised for low power consumption. If we keep it fair and compare the two cores using the same process technology, the Pentium M isn't even close when it comes to performance. A 2 GHz Pentium M scores a respectable 1500 in SpecInt, but trails far behind with a specfp score of about 1000.
Hardware engineers do not believe in massive superscalar CPUs anymore[2]. Increasing ILP a tiny bit requires exponentially bigger out-of-order hardware, which exponentially requires more power.
TLP and multi-core is hot and trendy. But the same problems that were true for squeezing ILP out of hardware are true about TLP in software. On the exception of naturally parallel applications such as rendering and database servers, getting more and more threads out of the majority of hardware will require exponentially more programming and debugging time. There are more high TLP designs such as Sun's Niagara that increase throughput, but also response time. And while the numbers of users that can update and read the database matters, the response time of the database can be important too. For example, while OLTP loads consist of many relatively simple SQL selects, Decision Support Systems (DSS or OLAP) fire off very complex queries with a high response time. To offer a good "data mining" experience, the single thread performance must not be neglected. The same can be said for some HPC and many typical workstation applications.
So, while designs that sacrifice ILP completely on the altar of TLP, such as Sun's Niagara, they may well be very popular in some markets such as webserving. Single thread performance is going to make the difference between the different multi-core solutions.
Here, the Itanium can leverage two big advantages: higher ILP and smaller cores. This last comment might seem ridiculous, given that the current Itanium Madison is about 432 mm2 large. However, if we look at the core (L1 inclusive), there about 25 million transistors that take about 80 mm2 die space. Note that the pictures below have been scaled and resized to reflect the relative proportions of the different cores.
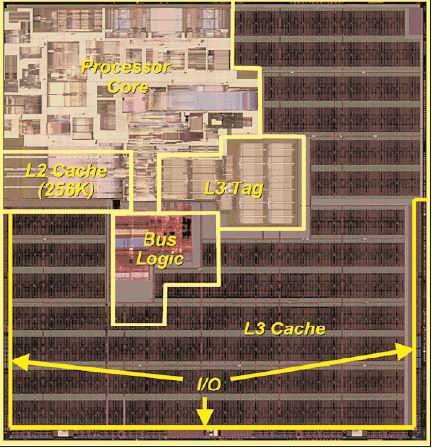
Madison 9 MB die
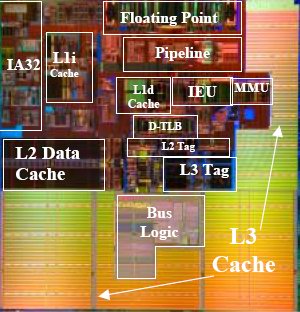
Madison core parts

Opteron die, rotated 90°
Itanium: a slim figure
We compare the different CPU cores in the table below. We consider the L1-cache being part of the core, but we list the number of transistors separately to be clear. To keep it fair, we compare all CPU using the same process technologies, 0.13µ, with the exception of the Intel Xeon.
There is no doubt that a 0.13µ Xeon MP is no match for either of the IBM Power 5, the Itanium or Opteron with both Spec FP2000 and SpecInt around 1200 for a Xeon MP 3 GHz. The Xeon MP 0.13µ is also a 32 bit CPU, so it does not belong in the list below.
The reason why I listed the 90nm Xeon (DP) is to show how complex an x86 architecture can get when it has 64 bit and an extremely deep pipeline in a quest for high clock speeds, which must negate the low ILP. With more than 50 million transistors, it is no wonder that Xeon "Irwindale/Nocona" is the hottest CPU (per core) of the bunch despite being manufactured in a more advanced process.
Why do we use Spec FP2000 and Spec Int2000[3]? It is true that these benchmarks are close to meaningless when you want to compare server or workstation performance in the real world. Spec FP is a decent predictor of HPC/scientific performance, but fails to predict Digital Content Creation performance despite containing a few OpenGL benchmarks. The reason why we use these two benchmarks is that currently, we are evaluating the CPU architecture, its future potential and current compiler performance, and not the complete system.
| CPU feature | Intel Itanium "Madison" | Intel Xeon P4 Irwindale | IBM Power 5 (+) | AMD Opteron |
| Process technology | 0.13 µ CU | 0.09 µ CU | 0.13 µ CU SOI | 0.13 µ CU SOI |
| Die Size (mm2) | 432 | 130 | 389 | 190 |
| Number of transistors (Million) | 592 | 169 | 276 | 106 |
| Number of transistors (Million) L1-cache | 1.8 | +/- 6 | 5.3 | 7.7 |
| Number of transistors (Million) L2 Cache | 14 | 113 | 107 | 57 |
| Number of transistors (Million) L3 Cache | 510 | 0 | off die | 0 |
| Number of transistors (Million) Tag (L2 + L3) | 23 | 4 | 33 | 4 |
| Number of transistors (Million) Core | 20 | 50 | 35* | 40 |
| Pure logic core (-L1) | 18 | 44 | 30 | 32 |
| Top clock speed | 1600 | 3800 | 1900 | 2600 |
| Best Spec FP2000 Score | 2712 | 1898 | 2839 | 1955 |
| Best Spec Int2000 Score | 1590 | 1810 | 1470 | 1713 |
| TDP | 107 W | 115-130 W | 200 W** | <95W |
** for two cores
To calculate the cache sizes, we used the following formula:
Cache size expressed in Bytes x 9 bits per byte (8 + 1 bit ECC/parity protection) x 6 Transistors per bit (SRAM)We calculated the Power 5 core as follows. The PowerPC 970FX, aka Apple's G5, is essentially a Power 4 core with Altivec, but without the L3 cache tag. If we subtract the number of transistors of the L2 cache (28 million) from the total number of transistors in the PowerPC 970, we end up with about 30 million transistors. The Power 5 core is a bit more complex (SMT and a few tweaks have been added), so we estimate it at about 35 million transistors.
HP and Intel have stated that the Itanium 2 core, including the L2-cache, has about 40 million transistors. If we subtract the L2 cache, we end up with about 26 million transistors, which still includes the x86 compatibility transistors (about 4 million) and the L2-tag. It wouldn't be fair to include the x86 transistors when we compare the merits of EPIC with x86 and RISC.

The Itanium core is twice as small as the Xeon's
And, what about the Pentium M? Well, the core is about 25 million transistors, but it is pretty hard to compare this CPU with Itanium as the Pentium M is optimised for low power consumption. If we keep it fair and compare the two cores using the same process technology, the Pentium M isn't even close when it comes to performance. A 2 GHz Pentium M scores a respectable 1500 in SpecInt, but trails far behind with a specfp score of about 1000.








43 Comments
View All Comments
JohanAnandtech - Wednesday, November 9, 2005 - link
Yes, very nice remark. Part of that 25% is thanks to the L2-I cache which is now better adapted to the bigger instructions without increasing latency. Most RISC have a bigger I cache than D-cache.Do you have an URL handy? I have been searching all over the web to find that 25%.
mino - Wednesday, November 9, 2005 - link
Well, IMHO going for 1.7bilion transistors core on 90nm process was an idiocy from the beginning. Also the 24M L3 cache is clear waste. Had intel emplemented on-die memory controlled the montecino may have been online allready.Actually it popular to say AMD marketing likes to shot its legs. However at least in the period 2002-2004 the one who shot its legs by R&D cannon was clearly Intel. No pun intended.
BTW nice article.
It's sad Intel has not gone the Alpha route in the 90's. That one was in McKinley league allready in 2000 and the software support (the biggest problem of IA64) was allready there.
Maybe AMD paid Intel for this ;-). Had intel gone Alpha back then, Opteron would be an niche market now.
No mistake, K8's design is clearly Alpha for masses.
fitten - Wednesday, November 9, 2005 - link
"Had intel emplemented on-die memory controlled the montecino may have been online allready."An on-die memory controller is not a silver bullet for all problems that a CPU faces. Even *with* an on-die memory controller, the latency of memory accesses are an order of magnitude slower than L2 cache access. Sure, it's less than not having it but when a cache miss stalls your entire pipeline, you don't want to wait even the 70+ns for an on-die memory controller. The solution is to reduce the number of cache misses which means larger caches, which is exactly what they are doing.
"No mistake, K8's design is clearly Alpha for masses."
I don't know how to read this at all. If you liked the Alpha, you should like the P4 as their design goals/parameters were the same... high clock speed at any cost and then add the expensive stuff like OOOE. The Athlon(64) designs do not follow this pattern. The Athlons follow the "brainiac" model more than the "speed-freak" model. (Alpha was the speed freak, PARISC was the brainiac, btw).