Itanium - is there light at the end of the tunnel?
by Johan De Gelas on November 9, 2005 12:05 AM EST- Posted in
- CPUs
EPIC 101
The basics of EPIC (Explicitly Parallel Instruction-set Computing) is a mix of typical RISC and VLIW (very long instruction word) features. From RISC, it copies a relatively straightforward instruction set, a very large register file (128 registers for integer and floating point) and three operand instructions that use registers. Using three operands, two source registers and a destination register (R1 = R2 +R3), instead of two (R2 = R1 + R2), does the calculation job in less instructions and avoids - given enough registers - unnecessary trips to hidden registers or the L1- cache.
Load and Store instruction are used to getting data and instructions from the memory; instructions that actually calculate do not reference memory locations as in x86.
A fixed instruction length makes it much easier to decode, like RISC ISA's, and completely contrary to the x86 instruction set where decoding is a very painful job that requires many pipeline stages. These additional stages are necessary to obtain high clockspeeds, but they make the pipeline unnecessarily long and the branch prediction penalty worse. The Itanium 2 has only an 8-stage pipeline, but is still able to clock up to 1.7 GHz (conservative) using a 130 nm process. Compared to the Xeon MP (130 nm), which clocked up to 3 GHz, it needed a 28-stage pipeline (20 after Trace cache + 8 before) to achieve less than a twice as high a clock speed.
Inside the hardware, the Itanium uses instruction bundles that are 128 bits large. Such a bundle consists of three 41 bit instructions and one 5 bit template. It is this 5 bit template that contains the "compiler grouping" information about the parallelism between the different instructions. Thus, compilers will use this template to tell the CPU what instructions should be issued together. It gets even better; this template also contains an end-of-bundle bit. With this bit, the compiler can indicate whether or not the bundle is finished after the first three instructions or if the CPU should chain two (or even more) bundles together.
Another 6 bits specify the 64 combinations of predication that allow the compiler to eliminate branches, as each instruction can be conditional. So, instead of:
The instruction grouping and elimination of most of the branches opens the way to higher ILP. So, while the Athlon 64 can sustain at most 3 instructions per clock cycle, the Itanium can fetch, decode, issue, execute and retire 2 bundles or 6 instructions per clock cycle.
Contrary to old VLIW designs, the compiler is not obliged to put the instruction in a strict order in a bundle. But there are certain limitations to what kind of instruction mix you can find inside a bundle, as you can see in the table below.
Cache hints, data and instruction pre-fetching and data speculation are a few of the tricks that the Itanium and its compiler can use to keep the caches full with the right instructions and data. Those tricks and the large caches are essential to the Itanium: a L2 cache miss can result in a real stall, as the CPU cannot check dynamically for independent instruction to issue.
In a nutshell, the Itanium has the following advantages:
The basics of EPIC (Explicitly Parallel Instruction-set Computing) is a mix of typical RISC and VLIW (very long instruction word) features. From RISC, it copies a relatively straightforward instruction set, a very large register file (128 registers for integer and floating point) and three operand instructions that use registers. Using three operands, two source registers and a destination register (R1 = R2 +R3), instead of two (R2 = R1 + R2), does the calculation job in less instructions and avoids - given enough registers - unnecessary trips to hidden registers or the L1- cache.
Load and Store instruction are used to getting data and instructions from the memory; instructions that actually calculate do not reference memory locations as in x86.
A fixed instruction length makes it much easier to decode, like RISC ISA's, and completely contrary to the x86 instruction set where decoding is a very painful job that requires many pipeline stages. These additional stages are necessary to obtain high clockspeeds, but they make the pipeline unnecessarily long and the branch prediction penalty worse. The Itanium 2 has only an 8-stage pipeline, but is still able to clock up to 1.7 GHz (conservative) using a 130 nm process. Compared to the Xeon MP (130 nm), which clocked up to 3 GHz, it needed a 28-stage pipeline (20 after Trace cache + 8 before) to achieve less than a twice as high a clock speed.
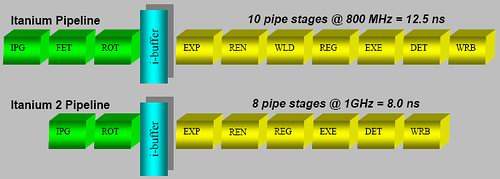
The short Itanium and Itanium 2 pipeline
Inside the hardware, the Itanium uses instruction bundles that are 128 bits large. Such a bundle consists of three 41 bit instructions and one 5 bit template. It is this 5 bit template that contains the "compiler grouping" information about the parallelism between the different instructions. Thus, compilers will use this template to tell the CPU what instructions should be issued together. It gets even better; this template also contains an end-of-bundle bit. With this bit, the compiler can indicate whether or not the bundle is finished after the first three instructions or if the CPU should chain two (or even more) bundles together.

IA-64 instruction bundle
Another 6 bits specify the 64 combinations of predication that allow the compiler to eliminate branches, as each instruction can be conditional. So, instead of:
Compare R1 to 0 (IF...)You get:
If false jump to Label
R2 =R3 ("Then" instructions)
Label: (Else instructions)
R2 =R1
On the condition that R=0, R2=R3So you eliminate the conditional jump ("If false, jump to") and replace the whole "IF THEN ELSE" clause with an instruction that checks the register and then moves the contents from R3 to R2 in one sweep. Conditional jumps are dependant on the instruction before it and they have to wait until the "Compare R1 to 0" instruction is done. Conditional instructions, however, travel through the pipeline for execution and don't have to wait for anything. You could say that the "IF" part and "Then" part are fused together. For the "else" part, you get:
On the condition that R<>0, R2 = R1Predication makes the code more compact, and eliminates branches and dependencies. Branches can make up 20% of your code, easily. So, with one branch every 5 instructions, it is very hard to issue many instructions in parallel. By converting them into conditional instructions, you eliminate the dependencies and the ILP can get much higher.
The instruction grouping and elimination of most of the branches opens the way to higher ILP. So, while the Athlon 64 can sustain at most 3 instructions per clock cycle, the Itanium can fetch, decode, issue, execute and retire 2 bundles or 6 instructions per clock cycle.
Contrary to old VLIW designs, the compiler is not obliged to put the instruction in a strict order in a bundle. But there are certain limitations to what kind of instruction mix you can find inside a bundle, as you can see in the table below.
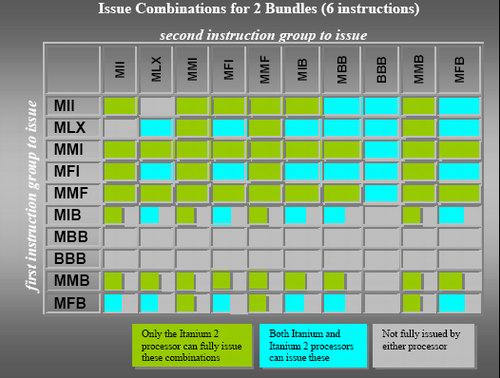
Possible bundles
Cache hints, data and instruction pre-fetching and data speculation are a few of the tricks that the Itanium and its compiler can use to keep the caches full with the right instructions and data. Those tricks and the large caches are essential to the Itanium: a L2 cache miss can result in a real stall, as the CPU cannot check dynamically for independent instruction to issue.
In a nutshell, the Itanium has the following advantages:
- Easy decoding leads to a shorter pipeline as less decoding work has to be done, so less stages are necessary;
- In order issue and execution means that dispatch hardware is much simpler, which leads to a shorter pipeline and less transistors;
- Removing conditional jumps and letting the compiler do the scheduling extracts more ILP; and
- 128 registers and the load/store model reduce the number of memory/cache accesses significantly,
- No out-of-order execution makes cache misses and pipelines stalls much more costly; and
- 128 registers and the whole bundle and group system make the instructions on average much longer than x86.








43 Comments
View All Comments
JohanAnandtech - Wednesday, November 9, 2005 - link
Yes, very nice remark. Part of that 25% is thanks to the L2-I cache which is now better adapted to the bigger instructions without increasing latency. Most RISC have a bigger I cache than D-cache.Do you have an URL handy? I have been searching all over the web to find that 25%.
mino - Wednesday, November 9, 2005 - link
Well, IMHO going for 1.7bilion transistors core on 90nm process was an idiocy from the beginning. Also the 24M L3 cache is clear waste. Had intel emplemented on-die memory controlled the montecino may have been online allready.Actually it popular to say AMD marketing likes to shot its legs. However at least in the period 2002-2004 the one who shot its legs by R&D cannon was clearly Intel. No pun intended.
BTW nice article.
It's sad Intel has not gone the Alpha route in the 90's. That one was in McKinley league allready in 2000 and the software support (the biggest problem of IA64) was allready there.
Maybe AMD paid Intel for this ;-). Had intel gone Alpha back then, Opteron would be an niche market now.
No mistake, K8's design is clearly Alpha for masses.
fitten - Wednesday, November 9, 2005 - link
"Had intel emplemented on-die memory controlled the montecino may have been online allready."An on-die memory controller is not a silver bullet for all problems that a CPU faces. Even *with* an on-die memory controller, the latency of memory accesses are an order of magnitude slower than L2 cache access. Sure, it's less than not having it but when a cache miss stalls your entire pipeline, you don't want to wait even the 70+ns for an on-die memory controller. The solution is to reduce the number of cache misses which means larger caches, which is exactly what they are doing.
"No mistake, K8's design is clearly Alpha for masses."
I don't know how to read this at all. If you liked the Alpha, you should like the P4 as their design goals/parameters were the same... high clock speed at any cost and then add the expensive stuff like OOOE. The Athlon(64) designs do not follow this pattern. The Athlons follow the "brainiac" model more than the "speed-freak" model. (Alpha was the speed freak, PARISC was the brainiac, btw).