Itanium - is there light at the end of the tunnel?
by Johan De Gelas on November 9, 2005 12:05 AM EST- Posted in
- CPUs
EPIC 101
The basics of EPIC (Explicitly Parallel Instruction-set Computing) is a mix of typical RISC and VLIW (very long instruction word) features. From RISC, it copies a relatively straightforward instruction set, a very large register file (128 registers for integer and floating point) and three operand instructions that use registers. Using three operands, two source registers and a destination register (R1 = R2 +R3), instead of two (R2 = R1 + R2), does the calculation job in less instructions and avoids - given enough registers - unnecessary trips to hidden registers or the L1- cache.
Load and Store instruction are used to getting data and instructions from the memory; instructions that actually calculate do not reference memory locations as in x86.
A fixed instruction length makes it much easier to decode, like RISC ISA's, and completely contrary to the x86 instruction set where decoding is a very painful job that requires many pipeline stages. These additional stages are necessary to obtain high clockspeeds, but they make the pipeline unnecessarily long and the branch prediction penalty worse. The Itanium 2 has only an 8-stage pipeline, but is still able to clock up to 1.7 GHz (conservative) using a 130 nm process. Compared to the Xeon MP (130 nm), which clocked up to 3 GHz, it needed a 28-stage pipeline (20 after Trace cache + 8 before) to achieve less than a twice as high a clock speed.
Inside the hardware, the Itanium uses instruction bundles that are 128 bits large. Such a bundle consists of three 41 bit instructions and one 5 bit template. It is this 5 bit template that contains the "compiler grouping" information about the parallelism between the different instructions. Thus, compilers will use this template to tell the CPU what instructions should be issued together. It gets even better; this template also contains an end-of-bundle bit. With this bit, the compiler can indicate whether or not the bundle is finished after the first three instructions or if the CPU should chain two (or even more) bundles together.
Another 6 bits specify the 64 combinations of predication that allow the compiler to eliminate branches, as each instruction can be conditional. So, instead of:
The instruction grouping and elimination of most of the branches opens the way to higher ILP. So, while the Athlon 64 can sustain at most 3 instructions per clock cycle, the Itanium can fetch, decode, issue, execute and retire 2 bundles or 6 instructions per clock cycle.
Contrary to old VLIW designs, the compiler is not obliged to put the instruction in a strict order in a bundle. But there are certain limitations to what kind of instruction mix you can find inside a bundle, as you can see in the table below.
Cache hints, data and instruction pre-fetching and data speculation are a few of the tricks that the Itanium and its compiler can use to keep the caches full with the right instructions and data. Those tricks and the large caches are essential to the Itanium: a L2 cache miss can result in a real stall, as the CPU cannot check dynamically for independent instruction to issue.
In a nutshell, the Itanium has the following advantages:
The basics of EPIC (Explicitly Parallel Instruction-set Computing) is a mix of typical RISC and VLIW (very long instruction word) features. From RISC, it copies a relatively straightforward instruction set, a very large register file (128 registers for integer and floating point) and three operand instructions that use registers. Using three operands, two source registers and a destination register (R1 = R2 +R3), instead of two (R2 = R1 + R2), does the calculation job in less instructions and avoids - given enough registers - unnecessary trips to hidden registers or the L1- cache.
Load and Store instruction are used to getting data and instructions from the memory; instructions that actually calculate do not reference memory locations as in x86.
A fixed instruction length makes it much easier to decode, like RISC ISA's, and completely contrary to the x86 instruction set where decoding is a very painful job that requires many pipeline stages. These additional stages are necessary to obtain high clockspeeds, but they make the pipeline unnecessarily long and the branch prediction penalty worse. The Itanium 2 has only an 8-stage pipeline, but is still able to clock up to 1.7 GHz (conservative) using a 130 nm process. Compared to the Xeon MP (130 nm), which clocked up to 3 GHz, it needed a 28-stage pipeline (20 after Trace cache + 8 before) to achieve less than a twice as high a clock speed.
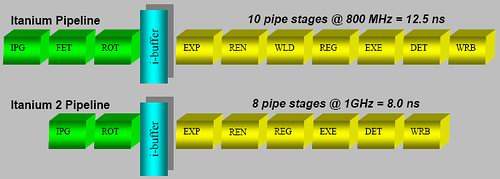
The short Itanium and Itanium 2 pipeline
Inside the hardware, the Itanium uses instruction bundles that are 128 bits large. Such a bundle consists of three 41 bit instructions and one 5 bit template. It is this 5 bit template that contains the "compiler grouping" information about the parallelism between the different instructions. Thus, compilers will use this template to tell the CPU what instructions should be issued together. It gets even better; this template also contains an end-of-bundle bit. With this bit, the compiler can indicate whether or not the bundle is finished after the first three instructions or if the CPU should chain two (or even more) bundles together.

IA-64 instruction bundle
Another 6 bits specify the 64 combinations of predication that allow the compiler to eliminate branches, as each instruction can be conditional. So, instead of:
Compare R1 to 0 (IF...)You get:
If false jump to Label
R2 =R3 ("Then" instructions)
Label: (Else instructions)
R2 =R1
On the condition that R=0, R2=R3So you eliminate the conditional jump ("If false, jump to") and replace the whole "IF THEN ELSE" clause with an instruction that checks the register and then moves the contents from R3 to R2 in one sweep. Conditional jumps are dependant on the instruction before it and they have to wait until the "Compare R1 to 0" instruction is done. Conditional instructions, however, travel through the pipeline for execution and don't have to wait for anything. You could say that the "IF" part and "Then" part are fused together. For the "else" part, you get:
On the condition that R<>0, R2 = R1Predication makes the code more compact, and eliminates branches and dependencies. Branches can make up 20% of your code, easily. So, with one branch every 5 instructions, it is very hard to issue many instructions in parallel. By converting them into conditional instructions, you eliminate the dependencies and the ILP can get much higher.
The instruction grouping and elimination of most of the branches opens the way to higher ILP. So, while the Athlon 64 can sustain at most 3 instructions per clock cycle, the Itanium can fetch, decode, issue, execute and retire 2 bundles or 6 instructions per clock cycle.
Contrary to old VLIW designs, the compiler is not obliged to put the instruction in a strict order in a bundle. But there are certain limitations to what kind of instruction mix you can find inside a bundle, as you can see in the table below.
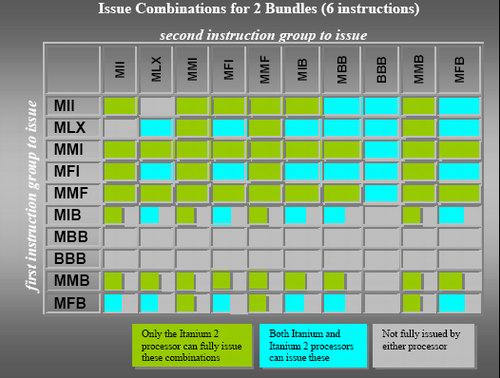
Possible bundles
Cache hints, data and instruction pre-fetching and data speculation are a few of the tricks that the Itanium and its compiler can use to keep the caches full with the right instructions and data. Those tricks and the large caches are essential to the Itanium: a L2 cache miss can result in a real stall, as the CPU cannot check dynamically for independent instruction to issue.
In a nutshell, the Itanium has the following advantages:
- Easy decoding leads to a shorter pipeline as less decoding work has to be done, so less stages are necessary;
- In order issue and execution means that dispatch hardware is much simpler, which leads to a shorter pipeline and less transistors;
- Removing conditional jumps and letting the compiler do the scheduling extracts more ILP; and
- 128 registers and the load/store model reduce the number of memory/cache accesses significantly,
- No out-of-order execution makes cache misses and pipelines stalls much more costly; and
- 128 registers and the whole bundle and group system make the instructions on average much longer than x86.








43 Comments
View All Comments
Starglider - Wednesday, November 9, 2005 - link
Well, back in university I passed my classes on CPU design, and I know a couple of flaours of assembly language and have worked on compilers professionally, so yes I'd say I know what I'm talking about.Hell, why am I being polite, /of course/ you can combine static and dynamic optimisation of instruction order. All x86 compilers /already/ do this. Virtual machine based programming languages (e.g. C# and Java) actually have /three/ tiers of optimisation; the primary compiler optimises the bytecode based on static global information, the runtime compiler optimises for the target instruction set based on medium-scale runtime information (at least Sun's Hotspot does), and then the CPU does instruction reordering and register remapping based on very local information. The efficiency of the final stage, e.g. the processor-level scheduling, can be improved by embedding hints in the instruction stream in exactly the same way that JIT compliation cane be improved by embedding hints in the bytecode of a VM language. Indeed arguably some RISC designs already do this to a limited extent, so implementing it for x86 isn't much of a stretch.
Spoonbender - Wednesday, November 9, 2005 - link
"The main philosophy behind Itanium is, of course, that a compiler can statically schedule instructions much better than a hardware scheduler" - Not always.Of course, the compiler can do all this with the static information within the same translation unit (or in some cases, only within the same basic code block), but not based on runtime behavior. Global optimizations are a pain to implement on a compiler, and a lot of them are simply too complex to even think about, while the hardware scheduler can easily see, for example, where a function is called from, meaning it can figure out some dependencies that might be practically impossible to do in the compiler.
Dynamic and static scheduling can achieve different results based on the different data available to them (at compile-time vs runtime), but it's wrong to say that one is much better than the other. The trick is to use the best of both worlds. x86 compilers already lets the compiler do as much scheduling as possible, and then at runtime the hardware scheduler tweaks everything to fit the particular pipeline, and uses the runtime info available that the compiler didn't have.
Of course, the Itanium could do the same, but relying solely on the compiler is a mistake.
Another disadvantage with the Itanium is that everything becomes a lot more architecture-specific. For example, the same compiler can write decent code for either a P4 or an Athlon 64 (or even a 386).
But because so much of the responsibility for scheduling and instruction bundles is put on the compiler, it's the compiler that has to reflect each particular architecture. So far, there's only Itanium and Itanium 2. What when we get to Itanium 5? Or AMD Athlanium? ;)
Different compilers for each? Or should we accept that the same compiler just generates inefficient code on all other EPIC CPU's than the original target?
And how much headroom does the architecture have then?
(What if in the future we want wider instruction bundles? Or if they find out that reaing bigger amounts of smaller bundles is more efficient? Or if they want to remove some of the current restrictions on instruction order inside a bundle?
I just can't see how EPIC can ever become a viable long-term architecture. And honestly, I don't want to go back to the old days of "New CPU? Have to recompile everything. Binary compatibility? What's that?"
JohanAnandtech - Wednesday, November 9, 2005 - link
You bring up very valid points that I will definitely address in a follow up. Indeed statically scheduling is not always better than dynamically. Most of the time it is, as you can look ahead much more far ahead, but it is less flexible.x86 compilers can never extract much ILP as they are limited by the ISA. With 20% branches and 8 registers, your options are very limited.
But your comment about binary compatibility is a mistake. The 128 bit bundle hasn't changed, so your binary compatibility is saved. It is true that the Itanium 2 can use bundles that the Itanium can't, but the same can be said about the P4 using SSE-2 instructions that the Pentium II can't use. You just provide two codepaths in the same code like we do now in apps where you can enable or disable SSE. Secondly, there are almost no Itanium I out there, so it is sufficient to make your code Itanium 2 compatible.
Wider bundles aren't going to happen. There is no reason to do so, as the groups of independent instructions can be as large as you want, you chain bundles together via the template. Montecito is perfectly compatible with Madison and mckinley
mkruer - Wednesday, November 9, 2005 - link
<mindless ramblings>I think one of the key things to point out is that the current x86 has very little in common with the original ISA, and that the ISA has been adapting over time. The current internal cores are more like RISC then the original CISC design which will probably lead to some low level VLIW implementation mainly in the area of the FP units.
My predictions are that we are going to start seeing some low level implementations of VLIW most likely as a sub core options at first. As time progresses we will see those sub cores become more and more powerful and functional, and as time progresses more and more of the current x86 ISA will fall off to be replaced by an updated x86 ISA. </mindless ramblings>
saratoga - Wednesday, November 9, 2005 - link
Yes very little in common aside from almost complete binary compatability. You're confusing ISA (the binary format for operations) with microarch (the layout of transistors in a processor).Also, "low level VLIW", WTF?
Brian23 - Wednesday, November 9, 2005 - link
If Intel would drop the x86 compatability, L3 cache, and up the L1 and L2 chaches significantly and add an on die memory controller, this chip would be incredable. Then they could do something like transmetta did for backwards compatability until they can coax MS to write an os and compiler that runs natively on chip. At that point x86 would be dead.JohanAnandtech - Wednesday, November 9, 2005 - link
If they up the L1 and L2, it would result in higher latencies. Right now, the L1-cache has a 1 cycle L1. So L1-accesses are as good as free, you don't want that to change for an in-order CPU.The L3-cache is important as it lowers the accesses to the memory significantely. But I agree that x86 hardware support should be dropped, and only software emulation should be available. That opens up a few million transistors that can be used for a primitive OOO system or improved prefetching.
highlandsun - Wednesday, November 9, 2005 - link
As a server chip there's really no reason to beg MS for anything. Linux and gcc can take it from here. Note that big Itanium servers from HP and SGI all run Linux anyway, MS is irrelevant in this space. But yes, they really ought to jettison the x86 baggage. In an open source world there's no need to do on-chip emulation to execute legacy binaries - just recompile the source and get a native binary instead.PeteRoy - Wednesday, November 9, 2005 - link
YEahIntelUser2000 - Wednesday, November 9, 2005 - link
Johan, Do you know that the 30% performance advantage is SoEMT only on Montecito??? Not comparing against Madison??Whether by major compiler improvements or core improvements, Montecito should be 25% faster per clock, per core over Madison.
Its sad that Intel had problems with Montecito. At 2GHz it would have been amazing.