Itanium - is there light at the end of the tunnel?
by Johan De Gelas on November 9, 2005 12:05 AM EST- Posted in
- CPUs
The limits of TLP...
Hardware engineers do not believe in massive superscalar CPUs anymore[2]. Increasing ILP a tiny bit requires exponentially bigger out-of-order hardware, which exponentially requires more power.
TLP and multi-core is hot and trendy. But the same problems that were true for squeezing ILP out of hardware are true about TLP in software. On the exception of naturally parallel applications such as rendering and database servers, getting more and more threads out of the majority of hardware will require exponentially more programming and debugging time. There are more high TLP designs such as Sun's Niagara that increase throughput, but also response time. And while the numbers of users that can update and read the database matters, the response time of the database can be important too. For example, while OLTP loads consist of many relatively simple SQL selects, Decision Support Systems (DSS or OLAP) fire off very complex queries with a high response time. To offer a good "data mining" experience, the single thread performance must not be neglected. The same can be said for some HPC and many typical workstation applications.
So, while designs that sacrifice ILP completely on the altar of TLP, such as Sun's Niagara, they may well be very popular in some markets such as webserving. Single thread performance is going to make the difference between the different multi-core solutions.
Here, the Itanium can leverage two big advantages: higher ILP and smaller cores. This last comment might seem ridiculous, given that the current Itanium Madison is about 432 mm2 large. However, if we look at the core (L1 inclusive), there about 25 million transistors that take about 80 mm2 die space. Note that the pictures below have been scaled and resized to reflect the relative proportions of the different cores.
Itanium: a slim figure
We compare the different CPU cores in the table below. We consider the L1-cache being part of the core, but we list the number of transistors separately to be clear. To keep it fair, we compare all CPU using the same process technologies, 0.13µ, with the exception of the Intel Xeon.
There is no doubt that a 0.13µ Xeon MP is no match for either of the IBM Power 5, the Itanium or Opteron with both Spec FP2000 and SpecInt around 1200 for a Xeon MP 3 GHz. The Xeon MP 0.13µ is also a 32 bit CPU, so it does not belong in the list below.
The reason why I listed the 90nm Xeon (DP) is to show how complex an x86 architecture can get when it has 64 bit and an extremely deep pipeline in a quest for high clock speeds, which must negate the low ILP. With more than 50 million transistors, it is no wonder that Xeon "Irwindale/Nocona" is the hottest CPU (per core) of the bunch despite being manufactured in a more advanced process.
Why do we use Spec FP2000 and Spec Int2000[3]? It is true that these benchmarks are close to meaningless when you want to compare server or workstation performance in the real world. Spec FP is a decent predictor of HPC/scientific performance, but fails to predict Digital Content Creation performance despite containing a few OpenGL benchmarks. The reason why we use these two benchmarks is that currently, we are evaluating the CPU architecture, its future potential and current compiler performance, and not the complete system.
* per core, two cores: about 70 million transistors
** for two cores
To calculate the cache sizes, we used the following formula:
HP and Intel have stated that the Itanium 2 core, including the L2-cache, has about 40 million transistors. If we subtract the L2 cache, we end up with about 26 million transistors, which still includes the x86 compatibility transistors (about 4 million) and the L2-tag. It wouldn't be fair to include the x86 transistors when we compare the merits of EPIC with x86 and RISC.
And, what about the Pentium M? Well, the core is about 25 million transistors, but it is pretty hard to compare this CPU with Itanium as the Pentium M is optimised for low power consumption. If we keep it fair and compare the two cores using the same process technology, the Pentium M isn't even close when it comes to performance. A 2 GHz Pentium M scores a respectable 1500 in SpecInt, but trails far behind with a specfp score of about 1000.
Hardware engineers do not believe in massive superscalar CPUs anymore[2]. Increasing ILP a tiny bit requires exponentially bigger out-of-order hardware, which exponentially requires more power.
TLP and multi-core is hot and trendy. But the same problems that were true for squeezing ILP out of hardware are true about TLP in software. On the exception of naturally parallel applications such as rendering and database servers, getting more and more threads out of the majority of hardware will require exponentially more programming and debugging time. There are more high TLP designs such as Sun's Niagara that increase throughput, but also response time. And while the numbers of users that can update and read the database matters, the response time of the database can be important too. For example, while OLTP loads consist of many relatively simple SQL selects, Decision Support Systems (DSS or OLAP) fire off very complex queries with a high response time. To offer a good "data mining" experience, the single thread performance must not be neglected. The same can be said for some HPC and many typical workstation applications.
So, while designs that sacrifice ILP completely on the altar of TLP, such as Sun's Niagara, they may well be very popular in some markets such as webserving. Single thread performance is going to make the difference between the different multi-core solutions.
Here, the Itanium can leverage two big advantages: higher ILP and smaller cores. This last comment might seem ridiculous, given that the current Itanium Madison is about 432 mm2 large. However, if we look at the core (L1 inclusive), there about 25 million transistors that take about 80 mm2 die space. Note that the pictures below have been scaled and resized to reflect the relative proportions of the different cores.
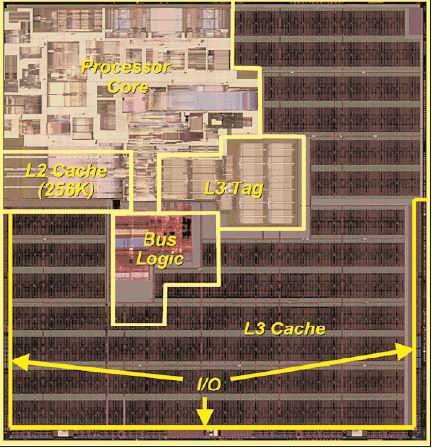
Madison 9 MB die
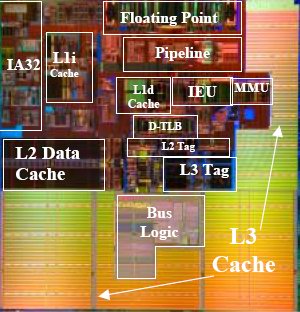
Madison core parts

Opteron die, rotated 90°
Itanium: a slim figure
We compare the different CPU cores in the table below. We consider the L1-cache being part of the core, but we list the number of transistors separately to be clear. To keep it fair, we compare all CPU using the same process technologies, 0.13µ, with the exception of the Intel Xeon.
There is no doubt that a 0.13µ Xeon MP is no match for either of the IBM Power 5, the Itanium or Opteron with both Spec FP2000 and SpecInt around 1200 for a Xeon MP 3 GHz. The Xeon MP 0.13µ is also a 32 bit CPU, so it does not belong in the list below.
The reason why I listed the 90nm Xeon (DP) is to show how complex an x86 architecture can get when it has 64 bit and an extremely deep pipeline in a quest for high clock speeds, which must negate the low ILP. With more than 50 million transistors, it is no wonder that Xeon "Irwindale/Nocona" is the hottest CPU (per core) of the bunch despite being manufactured in a more advanced process.
Why do we use Spec FP2000 and Spec Int2000[3]? It is true that these benchmarks are close to meaningless when you want to compare server or workstation performance in the real world. Spec FP is a decent predictor of HPC/scientific performance, but fails to predict Digital Content Creation performance despite containing a few OpenGL benchmarks. The reason why we use these two benchmarks is that currently, we are evaluating the CPU architecture, its future potential and current compiler performance, and not the complete system.
| CPU feature | Intel Itanium "Madison" | Intel Xeon P4 Irwindale | IBM Power 5 (+) | AMD Opteron |
| Process technology | 0.13 µ CU | 0.09 µ CU | 0.13 µ CU SOI | 0.13 µ CU SOI |
| Die Size (mm2) | 432 | 130 | 389 | 190 |
| Number of transistors (Million) | 592 | 169 | 276 | 106 |
| Number of transistors (Million) L1-cache | 1.8 | +/- 6 | 5.3 | 7.7 |
| Number of transistors (Million) L2 Cache | 14 | 113 | 107 | 57 |
| Number of transistors (Million) L3 Cache | 510 | 0 | off die | 0 |
| Number of transistors (Million) Tag (L2 + L3) | 23 | 4 | 33 | 4 |
| Number of transistors (Million) Core | 20 | 50 | 35* | 40 |
| Pure logic core (-L1) | 18 | 44 | 30 | 32 |
| Top clock speed | 1600 | 3800 | 1900 | 2600 |
| Best Spec FP2000 Score | 2712 | 1898 | 2839 | 1955 |
| Best Spec Int2000 Score | 1590 | 1810 | 1470 | 1713 |
| TDP | 107 W | 115-130 W | 200 W** | <95W |
** for two cores
To calculate the cache sizes, we used the following formula:
Cache size expressed in Bytes x 9 bits per byte (8 + 1 bit ECC/parity protection) x 6 Transistors per bit (SRAM)We calculated the Power 5 core as follows. The PowerPC 970FX, aka Apple's G5, is essentially a Power 4 core with Altivec, but without the L3 cache tag. If we subtract the number of transistors of the L2 cache (28 million) from the total number of transistors in the PowerPC 970, we end up with about 30 million transistors. The Power 5 core is a bit more complex (SMT and a few tweaks have been added), so we estimate it at about 35 million transistors.
HP and Intel have stated that the Itanium 2 core, including the L2-cache, has about 40 million transistors. If we subtract the L2 cache, we end up with about 26 million transistors, which still includes the x86 compatibility transistors (about 4 million) and the L2-tag. It wouldn't be fair to include the x86 transistors when we compare the merits of EPIC with x86 and RISC.

The Itanium core is twice as small as the Xeon's
And, what about the Pentium M? Well, the core is about 25 million transistors, but it is pretty hard to compare this CPU with Itanium as the Pentium M is optimised for low power consumption. If we keep it fair and compare the two cores using the same process technology, the Pentium M isn't even close when it comes to performance. A 2 GHz Pentium M scores a respectable 1500 in SpecInt, but trails far behind with a specfp score of about 1000.








43 Comments
View All Comments
fitten - Thursday, November 10, 2005 - link
I'm guessing they'll write an article on it when it actually exists... it's at least two years out still before they expect to have *real* silicon for it and a lot can change between now and then.fic - Thursday, November 10, 2005 - link
Hmmm, their press release says Q3 '06. I know that dates can and do slip, but I doubt they will slip a year.Besides, most of the Itanic stuff that was talked about in the article isn't shipping and probably never will. How late is the "next" version - 2+ years? - with no real expected ship date in the forseeable future. It would be nice to see an article about the architecture of the chips, decisions made and trade offs for the power efficiency that they are driving toward. Also, this was started a few years ago, what lead them down the power efficiency path before some of the major companies (notably intel) even realized it was an issue.
fitten - Friday, November 11, 2005 - link
From the press release:"It will sample in the third calendar quarter of 2006, with single-core and quad-core versions due in early and late 2007, respectively, and an eight-core version planned for 2008."
Sampling doesn't mean general avialability... not even close. The closest thing they have to availability is "early and late 2007" for availability of single- and quad-core versions.
xelpmoc - Wednesday, November 9, 2005 - link
"TLP, caches and power consumption" is more than three words!Interesting article, though.
Questar - Wednesday, November 9, 2005 - link
Excelent article.I've been telling people for years the Itanium architecture is the future (not the chip). In 20 years there will be no OOE chips on the market, everything will be similar to EPIC. AMD will be there too.
highlandsun - Wednesday, November 9, 2005 - link
I don't see any need for EPIC or VLIW. The Itanium is basically using a 41 bit instruction word. The allocation of bits is only slightly different from the allocation used in a 32 bit RISC instruction. Indeed, point a 128-bit memory channel at a stream of 32 bit instructions and you'll get higher instruction dispatch rates and greater code density. EPIC is philosophically the same as hyperthreading - running multiple instruction streams in parallel in a single CPU core. But that just makes CPU designs unnecessarily complex. With the trend to multi-core CPUs, you get parallelism by using separate cores. Let each core crunch on a single instruction stream at a time, and all of that extra baggage is unnecessary. What is the point of having 11 execution units in a single core if you can only feed it 3 instructions per cycle? An efficient design would keep the number of execution units matched to the number of instructions available, any more is just wasted.Personally I would have invested more effort into scaling speeds on the MIPS design. The Itanium's predicated instructions are cool, but the MIPS architecture has those too. Anything you can do to avoid branching is definitely a win. But if you can pre-fetch 4 32-bit instructions in one cycle and decode and detect branches in advance, that's going to give higher IPC than this VLIW implementation.
Questar - Wednesday, November 9, 2005 - link
You don't know what EPIC is. It's not hyperthreading, and it makes CPU's LESS complex as there is no need for all the hardware needed to support OOE. Cell and Xenos are examples.Think what you want, but the brightest mins in the CPU world are all looking this way.
highlandsun - Wednesday, November 9, 2005 - link
Actually, having handwritten IA64 assembly code I'm acutely aware of what EPIC is and isn't. The point is that it's another lame attempt at increasing parallelism in one core. The problem is that it tries to give the illusion of indepent execution units, just as hyperthreading tries to give the illusion of multiple execution units, and neither implementation is sufficiently flexible. You would get more throughput from truly independent cores, letting the programmer (or some layer above the processor) explicitly allocate instructions to execution units.roymbrown - Thursday, November 10, 2005 - link
"it's another lame attempt at increasing parallelism in one core"It sounds like you are confusing different types of parallelism here. You are referring to TLP (thread level), but EPIC attempts to address ILP (instruction level). Hyperthreading is focused on running multiple independent threads on a single core. Hyperthreading improves TLP, often, at the expense of ILP. EPIC is focused on executing non-dependent instructions within a single thread in parallel. This is more analagous to the work done by complex out-of-order scheduler. EPIC attempts to push this scheduling work onto the compiler.
"You would get more throughput from truly independent cores"
Yes, you would, if you have lots of independent threads. Adding more independent cores improves TLP, but does nothing about ILP.
Thunder 57 - Monday, May 6, 2019 - link
It may not be 20 years later, but OoOE is very much alive and Itanium is dead. We've been hearing for years now that ARM will kill off x86-64. I wonder where we will be in another 20 years.