Linux Shootout: Opteron 150 vs. Xeon 3.6 Nocona
by Kristopher Kubicki on August 12, 2004 2:35 PM EST- Posted in
- Linux
TSCP
We apologize for the broken TSCP Makefile in the previous review which rendered our initial results inaccurate. Fortunately we posted the file so that others were able to detect the error and not find fault with the processors instead. The large issue many of our readers have brought to our attention are the severe difference in performance between various optimizations. Below you can see how various compile flags affected our benchmark scores.
The first benchmark is run with the optimization flags:
-O2 -funroll-loops -frerun-cse-after-loop
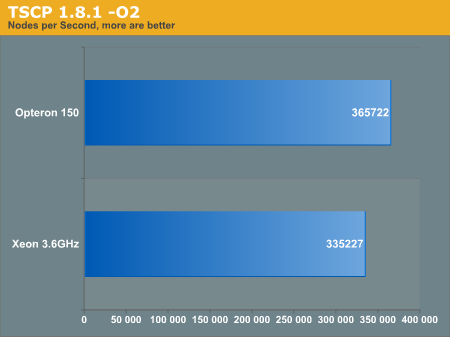
The next benchmark is run with the optimization flags:
-O3 funroll-loops -frerun-cse-after-loop
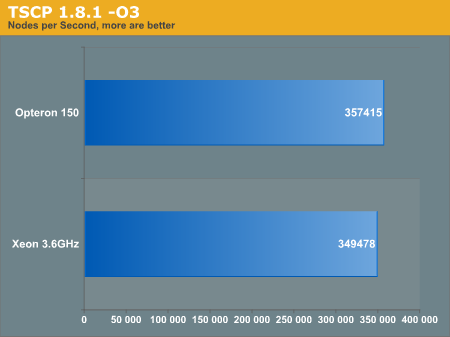
Finally, we have the architecture optimized flags as well:
(Intel) -O3 - march=nocona -funroll-loops -frerun-cse-after-loop
(AMD) -O3 - march=k8 -funroll-loops -frerun-cse-after-loop
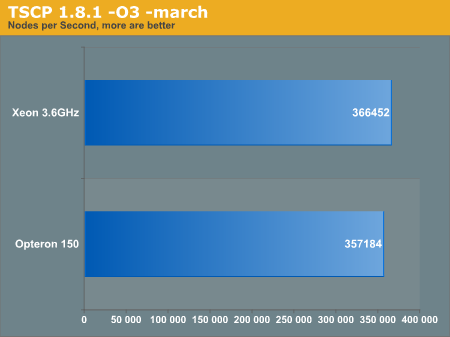
You are reading these charts correctly, the O3 flag actually penalizes the AMD CPU. We also compiled the program with -O2 -march=k8 but we got virtually the same score with or without the march flag.
We were informed others have been capable of much faster nodes per second using GCC 3.4.1 and the flagset:
-O3 -march=athlon-xp -funroll-loops -fomit-frame-pointer -ffast-math -fbranch-probabilities
We did not have time to fully test GCC 3.4.1, although there is a strong likelihood that 3.4 encourages better optimizations (particularly on the x86_64 platforms).
Crafty
For good measure, we have included Crafty into our chess benchmarks section. Crafty was only built using the "make linux-amd64" target. From the Makefile, it seems as though the "AMD64" moniker is slightly inappropriate. The target claims:
# -INLINE_AMD Compiles with the Intel assembly code for FirstOne(), # LastOne() and PopCnt() for the AMD opteron, only tested # with the 64-bit opteron GCC compiler.
The benchmark was generated by running the "bench" command inside the program.
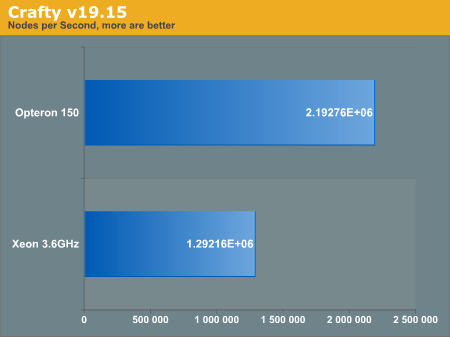
It is clear the difference between both processors is quite severe in this instance. Although it is difficult to pin an exact culprit, there are likely multiple arch optimizations were left untapped, and thus our reasoning for discouraging overusage of optimizations in general.








92 Comments
View All Comments
menads - Thursday, August 12, 2004 - link
Now all I want to say is big thanks for listening to your readers. Unlike other site which I would not mention that claims they are never wrong I think it is very nice of Anandtech editors to accept the criticizm and feedback from their readers and to get back retesting/reviewing.It is not about scores or brands - it is about the trust of the people reading these arcticles - a misleading review in most cases is worse than non-review.
Also Kristoper please do not take criticizm of the previous article personally - by criticizing your article most people were hoping you will do better next time.
KristopherKubicki - Thursday, August 12, 2004 - link
Hi Tau,>Handcoding ASM for specific tasks is NOT ancient
No youre correct. The context of the sentence though its the hand coded ASM used in 3.6 "stable" is ancient. Someone pointed out to me it doesnt even have the original MMX optimizations in it (i think).
Kristopher
Jeff7181 - Thursday, August 12, 2004 - link
What's that sound? I hear heavy footsteps and heavy breathing... oh... wait... it's the Xeon trying to keep pace with the Opteron :DSDA - Thursday, August 12, 2004 - link
Yeah, gj Kris, and yeah, I'd say you deserve a vacation after all that... thanks for listening to people, that's a lot more than certain editors at certain sites COUGHCOUGHTHGCOUGH would do.Pirox - Thursday, August 12, 2004 - link
Lmao...i got hand to kriz though ..you sure are one tough guy! Nice article...and to think that the guy remains calm...what gives?KristopherKubicki - Thursday, August 12, 2004 - link
Lynx516:Parts of 3.4.1 are backported into 3.3.3. Please check the SuSE 9.1 man pages.
Kristopher
TauCeti - Thursday, August 12, 2004 - link
Hi Kris,First: I appreciate the work you put into this review. But i cannot restrain to offer one (hopefully constructive) remark:
you write: "We are using John the Ripper 1.6.37 in this portion of the benchmark. As a few extremely knowledgeable readers pointed out, the "stable" 1.6 branch of code relies heavily on hand coded ASM which by today's standards is fairly ancient anyway."
Handcoding ASM for specific tasks is NOT ancient. Handcoded ASM allows you to utilize the execution units and the cache-latency distribution of a given core architecture to fullest extend.
That is of uttermost importance to widespread library functions used in scientific calculations. Even the popular GIMPS client is handcoded in ASM for every CPU-variation (there are even different codepaths for different cache sizes). The GIMPS developers are fighting for every single clock that can be saved in a inner loop for different architectures.
That aside...
Have a nice vacation. I guess you ned it ;)
If you - for yourself - agree that you could have done better, swallow your pride and try to convert the substantial complaints into positive energy. Ingnore the personal bullshit from wannabe-i-know-betters. Never waste a minute of your life for that. It's not worth is.
Regards,
Tau
Lynx516 - Thursday, August 12, 2004 - link
Hang on You said that you used -march=nocona and -march=k8 with gcc3.3.3. However those compile options are NOT IN gcc3.3.3! There is a serious problem if you use non existant optimisations as it casts a shadow of doubt on the competence of the author as it shows they dont know what they are doing.If this is the case read up on Linux before doing articles! If I am being overly harsh then correct the error
Lynx516 - Thursday, August 12, 2004 - link
Much better. Your compiler flags arnt the best as things like "-funroll-loops" tends to do nothing but bloat the binarys. Also your config page is not working in Firebird. Its nice to see realistic results. From the last version it looked as if all x86-64 cpus got owned by intel's offering because that was the only data you where presented with.However this shows a price for price comparison which is much better.
One point I have to make is why the first article was ever published in the first place as it was of little value as you had nothign realistic to compare it wiht.
syadnom - Thursday, August 12, 2004 - link
nice to see comparable processors benched against each other, the 164 in the old review justs isn't in the same category of processors.that said. i'm dissapointed to see the Xeon look so weak. I expected the benches to flop back and forth on which proc was faster because of their different designs. I know the Opt150 is one hell of a chip, but I think intel can do better.