Linux Shootout: Opteron 150 vs. Xeon 3.6 Nocona
by Kristopher Kubicki on August 12, 2004 2:35 PM EST- Posted in
- Linux
TSCP
We apologize for the broken TSCP Makefile in the previous review which rendered our initial results inaccurate. Fortunately we posted the file so that others were able to detect the error and not find fault with the processors instead. The large issue many of our readers have brought to our attention are the severe difference in performance between various optimizations. Below you can see how various compile flags affected our benchmark scores.
The first benchmark is run with the optimization flags:
-O2 -funroll-loops -frerun-cse-after-loop
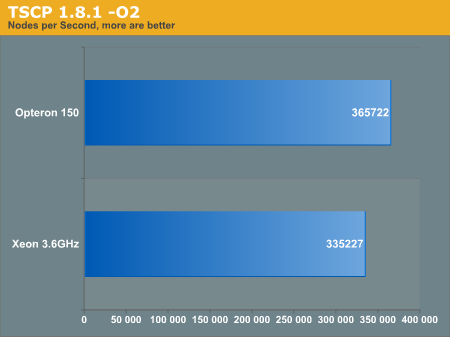
The next benchmark is run with the optimization flags:
-O3 funroll-loops -frerun-cse-after-loop
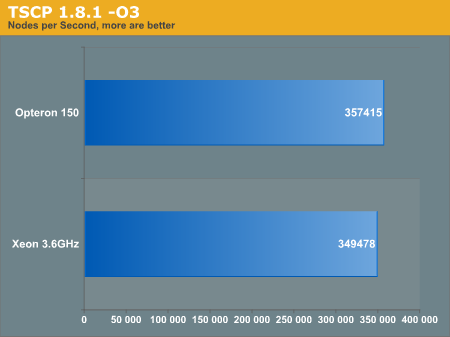
Finally, we have the architecture optimized flags as well:
(Intel) -O3 - march=nocona -funroll-loops -frerun-cse-after-loop
(AMD) -O3 - march=k8 -funroll-loops -frerun-cse-after-loop
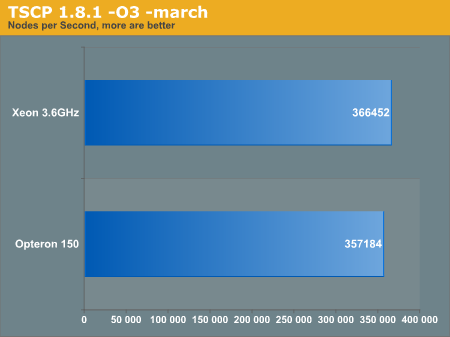
You are reading these charts correctly, the O3 flag actually penalizes the AMD CPU. We also compiled the program with -O2 -march=k8 but we got virtually the same score with or without the march flag.
We were informed others have been capable of much faster nodes per second using GCC 3.4.1 and the flagset:
-O3 -march=athlon-xp -funroll-loops -fomit-frame-pointer -ffast-math -fbranch-probabilities
We did not have time to fully test GCC 3.4.1, although there is a strong likelihood that 3.4 encourages better optimizations (particularly on the x86_64 platforms).
Crafty
For good measure, we have included Crafty into our chess benchmarks section. Crafty was only built using the "make linux-amd64" target. From the Makefile, it seems as though the "AMD64" moniker is slightly inappropriate. The target claims:
# -INLINE_AMD Compiles with the Intel assembly code for FirstOne(), # LastOne() and PopCnt() for the AMD opteron, only tested # with the 64-bit opteron GCC compiler.
The benchmark was generated by running the "bench" command inside the program.
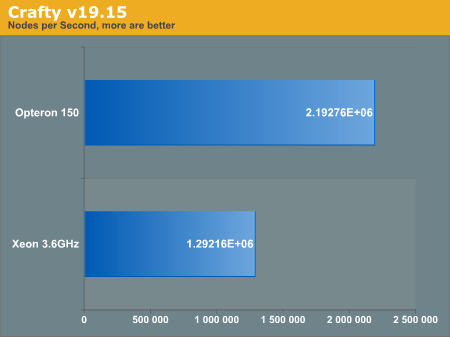
It is clear the difference between both processors is quite severe in this instance. Although it is difficult to pin an exact culprit, there are likely multiple arch optimizations were left untapped, and thus our reasoning for discouraging overusage of optimizations in general.








92 Comments
View All Comments
JGunther - Thursday, August 12, 2004 - link
Yeah... this reivew (to me) proves that Kris is a good, well-intentioned guy, as he put aside his own personal time to re-do these benchmarks. But the results within also prove how utterly inaccurate the first review was, thus justifying (some of) the criticism he recieved.I can see that you did learn at least one lesson, Kris; there are no claims in the conclusion of the Opteron "trouncing" the Xeon this time (even though such a remark may be justified now). :)
thatsright - Thursday, August 12, 2004 - link
Now will all of you A-Holes get off KrizK's & AT editorial staff's back!!