AMD Zen Microarchitecture: Dual Schedulers, Micro-Op Cache and Memory Hierarchy Revealed
by Ian Cutress on August 18, 2016 9:00 AM ESTLow Power, FinFET and Clock Gating
When AMD launched Carrizo and Bristol Ridge for notebooks, one of the big stories was how AMD had implemented a number of techniques to improve power consumption and subsequently increase efficiency. A number of those lessons have come through with Zen, as well as a few new aspects in play due to the lithography.
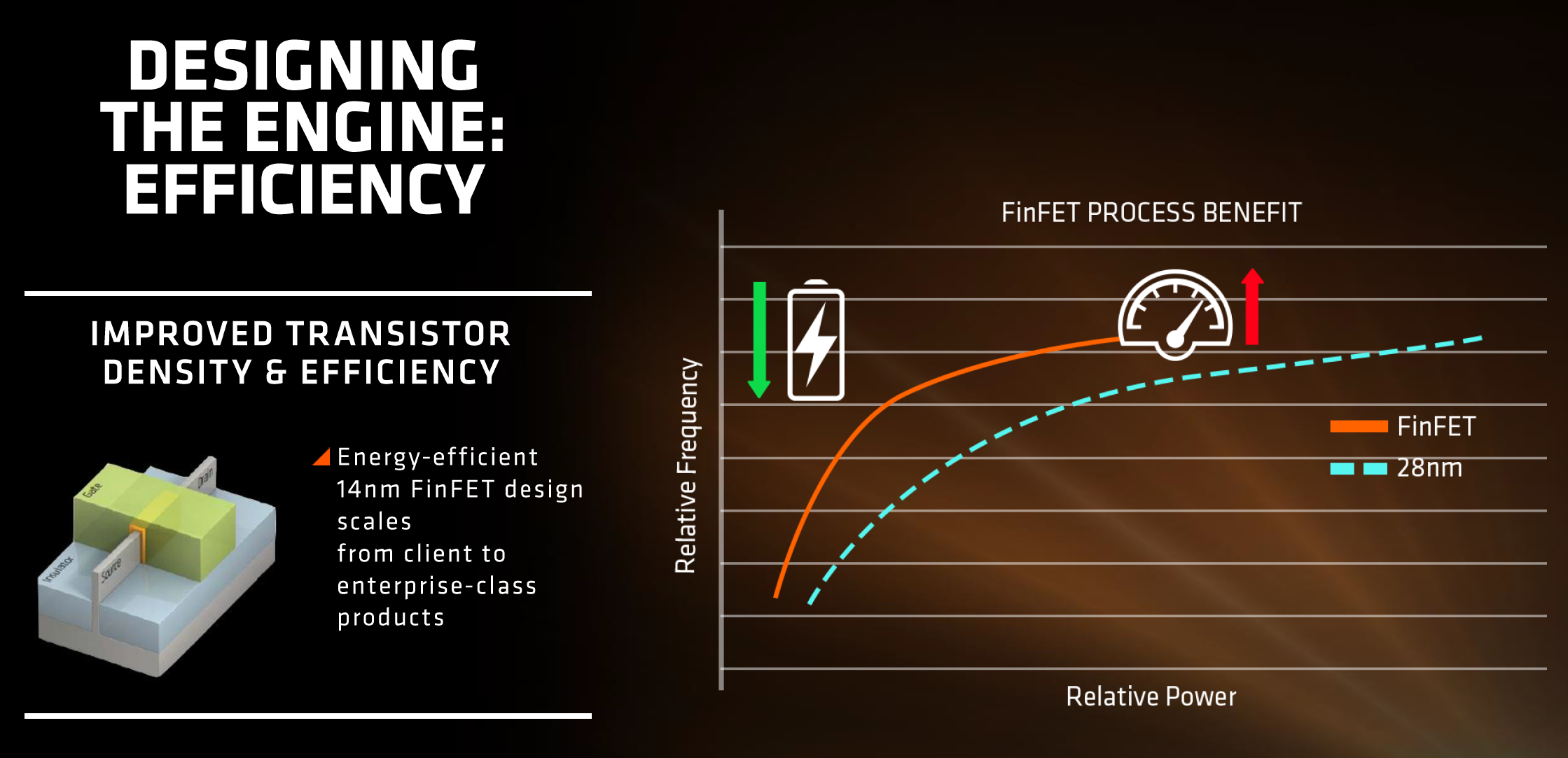
First up is the FinFET effect. Regular readers of AnandTech and those that follow the industry will already be bored to death with FinFET, but the design allows for a lower power version of a transistor at a given frequency. Now of course everyone using FinFET can have a different implementation which gives specific power/performance characteristics, but Zen on the 14nm FinFET process at Global Foundries is already a known quantity with AMD’s Polaris GPUs which are built similarly. The combination of FinFET with the fact that AMD confirmed that they will be using the density-optimised version of 14nm FinFET (which will allow for smaller die sizes and more reasonable efficiency points) also contributes to a shift of either higher performance at the same power or the same performance at lower power.
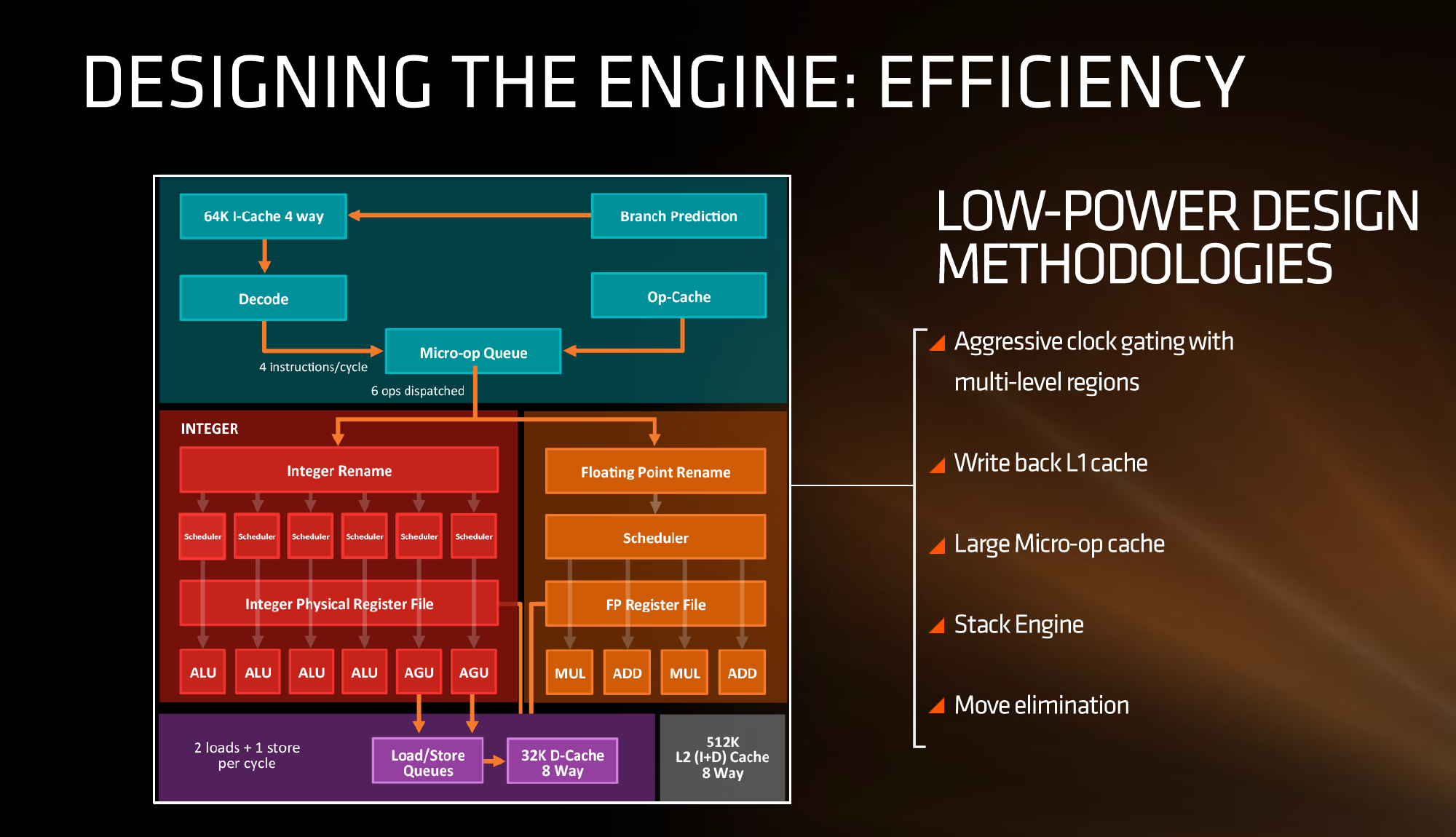
AMD stated in the brief that power consumption and efficiency was constantly drilled into the engineers, and as explained in previous briefings, there ends up being a tradeoff between performance and efficiency about what can be done for a number of elements of the core (e.g. 1% performance might cost 2% efficiency). For Zen, the micro-op cache will save power by not having to go further out to get instruction data, improved prefetch and a couple of other features such as move elimination will also reduce the work, but AMD also states that cores will be aggressively clock gated to improve efficiency.
We saw with AMD’s 7th Gen APUs that power gating was also a target with that design, especially when remaining at the best efficiency point (given specific performance) is usually the best policy. The way the diagram above is laid out would seem to suggest that different parts of the core could independently be clock gated depending on use (e.g. decode vs FP ports), although we were not able to confirm if this is the case. It also relies on having very quick (1-2 cycle) clock gating implementations, and note that clock gating is different to power-gating, which is harder to implement.








216 Comments
View All Comments
Jleppard - Thursday, August 18, 2016 - link
I like AMD and a fan. The agreement with Intel products Intel regardless if the allow someone else that would buy AMD from keeping X64 available to Intelfoobaz - Thursday, August 18, 2016 - link
Wouldn't the patents from their prior dispute be expired by now? That was a long time ago.Gigaplex - Thursday, August 18, 2016 - link
Some of them may have expired, but there are newer ones that haven't.wiak - Thursday, August 18, 2016 - link
AMD created AMD64 in 2000 and then released it in Athlon 64/Opteron then intel copied and called it EMT64 then everyone started calling it x86-64there is alot of references to amd64 in windows and ubuntu (amd64 isos etc)
https://en.wikipedia.org/wiki/X86-64#History
owan - Thursday, August 18, 2016 - link
Again, not a copy. They licensed it and branded it as their own thing.StormyParis - Thursday, August 18, 2016 - link
a legal copy is still a copy ?ianmills - Thursday, August 18, 2016 - link
Intel licensed the technology so they could copy it. I'm not sure what distinction you are tying to make :PMaybe you are trying to say Intel didn't steal the technology?
sorten - Thursday, August 18, 2016 - link
I think the point was in response to the OP, who was suggesting that AMD only ever copies Intel. The example of AMD64 is one where AMD was the innovator, though that's ancient history now.joex4444 - Thursday, August 18, 2016 - link
Nobody's disputing that AMD invented it. But what do you want Intel to do? Create their own and then all software companies have to support 32-bit, AMD64, and Intel64?Ej24 - Thursday, August 18, 2016 - link
Intel was close to releasing their own and gave up on consumer Intel64 when AMD beat them to market. Though I believe Intel still implemented it in some form in their Itanium brand?