The IBM POWER8 Review: Challenging the Intel Xeon
by Johan De Gelas on November 6, 2015 8:00 AM EST- Posted in
- IT Computing
- CPUs
- Enterprise
- Enterprise CPUs
- IBM
- POWER
- POWER8
"Per Core" Integer Performance: 7-Zip
The profile of a compression algorithm is somewhat similar to many server workloads: it can be hard to extract instruction level parallelism (ILP) and it's sensitive to memory parallelism and latency. The instruction mix is a bit different, but it's still somewhat similar to many server workloads. Testing single threaded is also a great way to check how well the turbo boost feature works in a CPU.
We ran this benchmark on the POWER8 a few months ago, but there are several reasons to do this again. First of all, we can now use GCC 4.9.2, which has specific support for POWER8 (-mcpu=power8). It is good to note that POWER8 is not a radical new design compared to POWER7. So we only expect modest gains from the compiler.
Secondly, last time we ran on top of PowerKVM, inside a virtual machine. Although that should not make a big difference either - as the benchmark runs almost completely (99%) in user modus and thus runs at 100% - it's still worthwhle to rule out the influence of the virtual machine.
So we recompiled the 7-Zip source code on every machine with the -O3 optimization with GCC 4.9.2.
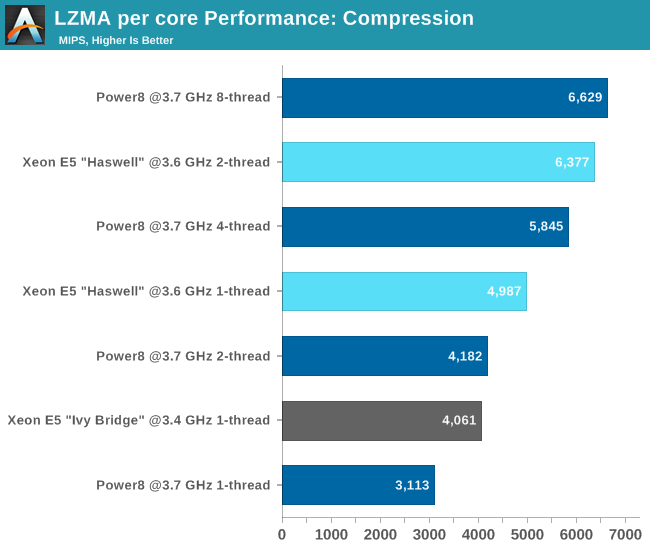
It is important to note that Intel is extremely aggressive with Turbo-boost on the Xeon E5-2699v3. Running code on one core causes the 2.3 GHz Xeon to boost to 3.6 GHz. As a result, the typical clockspeed advantage of the POWER8 was minimized to a measly 90 MHz, with the POWER8 CPUs boosting from 3.425 GHz to 3.690 GHz.
We found that the POWER8 needs more than one thread to deliver good performance: with one thread we only achieve 62% of the performance of a Haswell core at the same speed. Using the mcpu=power8 compiler flag did little more than boost the performance by 1-3%, which is within the margin of error of this benchmark. So your (occassional?) single threaded code will fare badly on POWER8.
Once you fire off 8 threads however, the POWER8 CPU outperforms the hyperthreaded Haswell core slightly (4%).
How about decompression which is even more (IPC) unfriendly to our brainiacs?
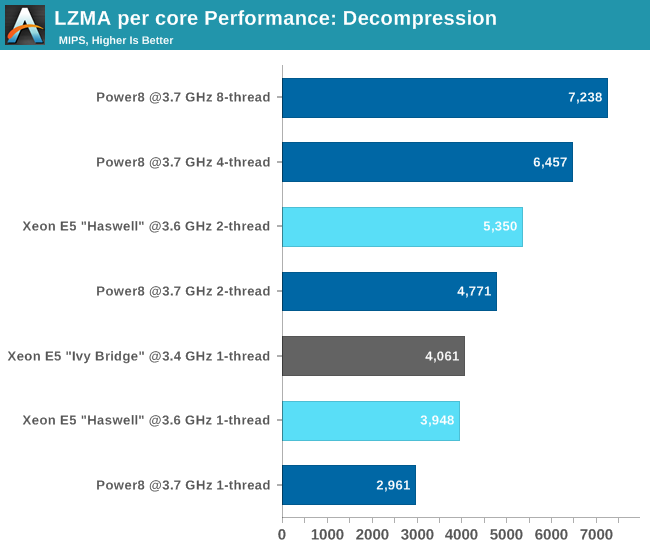
With a single thread, performance of a POWER8 core is about 25% slower than a Haswell core. The Haswell core is still clearly better in extracting Instruction Level Parallelism out of this ILP-unfriendly code. However, let there be no mistake about the integer crunching power of POWER8: it delivers 35% higher performance than the hyperthreaded Xeon E5, core per core, clock per clock (give or take a few MHz).
Compression depends more on the datacache and OoO engine. It is remarkable that the Haswell core with its smaller L1-datacache does a lot better than the POWER8. The many unpredictable branches of the decompression code underutilize these very wide modern cores, and as a result the SMT-8 capable POWER8 outperforms the dual-threaded (SMT-2) Haswell. Notice that running two threads instead one thread on the POWER8 offers 61% better performance. Running 8 threads delivers 2.4x higher performance, a clear indication that the POWER8 CPU has a very wide integer execution engine, but can only deliver if enough threads are active.








146 Comments
View All Comments
Der2 - Friday, November 6, 2015 - link
Life's good when you got power.BlueBlazer - Friday, November 6, 2015 - link
Aye, the power bills will skyrocket.Brutalizer - Friday, November 13, 2015 - link
It is confusing that sometimes you are benchmarking cores, and sometimes cpus. The question here is "which is the fastest cpu, x86 or POWER8" - and then you should bench cpu vs cpu. Not core vs core. If a core is faster than another core says nothing, you also need to know how many cores there are. Maybe one cpu has 2 cores, and the other has 1.000 cores. So when you tell which core is fastest, you give incomplete information so I still have to check up how many cores and then I can conclude which cpu is fastest. Or can I? There are scaling issues, just because one benchmark runs well on one core, does not mean it runs equally well when run on 18 cores. This means I can not extrapolate from one core to the entire cpu. So I still am not sure which cpu is fastest as you give me information about core performance. Next time, if you want to talk about which cpu is faster, please benchmark the entire cpu. Not core, as you are not talking about which core is faster.Here are 20+ world records by SPARC M7 cpu. It is typically 2-3x faster than POWER8 and Intel Xeon, all the way up to >10x faster. For instance, M7 achieves 87% higher saps than E5-2699v3.
https://blogs.oracle.com/BestPerf/
The big difference between POWER and SPARC vs x86, is scalability and RAS. When I say scalability, I talk about scale-up business Enterprise servers with as many as 16- or even 32-sockets, running business software such as SAP or big databases, that require one large single server. SGI UV2000 that scales to 10.000s of cores can only run scale-out HPC number crunching workloads, in effect, it is a cluster. There are no customers that have ever run SGI UV2000 using enterprise business workloads, such as SAP. There are no SAP benchmarks nor database benchmarks on SGI UV2000, because they can only be used as clusters. The UV2000 are exclusively used for number crunching HPC workloads, according to SGI. If you dont agree, I invite you to post SAP benchmarks with SGI UV2000. You wont find any. The thing is, you can not use a small cluster with 10.000 cores and replace a big 16- or 32-socket Unix server running SAP. Scale-out clusters can not run SAP, only scale-up servers can. There does not exist any scale-out clustered SAP benchmarks. All the highest SAP benchmarks are done by single large scale-up servers having 16- or 32-sockets. There are no 1.000-socket clustered servers on the SAP benchmark list.
x86 is low end, and have for decades stopped at maximum 8-sockets (when we talk about scale-up business servers), and just recently we see 16- and 32- sockets scale-up business x86 servers on the market (HP Kraken, and SGI UV300H) but they are brand new, so performance is quite bad. It takes a couple of generations until SGI and HP have learned and refined so they can ramp up performance for scale-up servers. Also, Windows and Linux has only scaled to 8-sockets and not above, so they need a major rewrite to be able to handle 16-sockets and a few TB of RAM. AIX and Solaris has scaled to 32-sockets and above for decades, were recently rewritten to handle 10s of TB of RAM. There is no way Windows and Linux can handle that much RAM efficiently as they have only scaled to 8-sockets until now. Unix servers scale way beyond 8-sockets, and perform very well doing so. x86 does not.
The other big difference apart from scalability is RAS. For instance, for SPARC and POWER you can hot swap everything, motherboards, cpu, RAM, etc. Just like Mainframes. x86 can not. Some SPARC cpus can replay instructions if something went wrong. x86 can not.
For x86 you typically use scale-out clusters: many cheap 1-2 socket small x86 servers in a huge cluster just like Google or Facebook. When they crash, you just swap them out for another cheap server. For Unix you typically use them as a single scale-up server with 16- or 32-sockets or even 64-sockets (Fujitsu M10-4S) running business software such as SAP, they have the RAS so they do not crash.
zeeBomb - Friday, November 6, 2015 - link
New author? Niiiice!Ryan Smith - Friday, November 6, 2015 - link
Ouch! Poor Johan.=(Johan is in fact the longest-serving AT editor. He's been here almost 11 years, just a bit longer than I have.
hans_ober - Friday, November 6, 2015 - link
@Johan you need to post this stuff more often, people are forgetting you :)JohanAnandtech - Friday, November 6, 2015 - link
well he started with "niiiiice". Could have been much worse. Hi zeeBomb, I am Johan, 43 years old and already 17 years active as a hardware editor. ;-)JanSolo242 - Friday, November 6, 2015 - link
Reading Johan reminds me of the days of AcesHardware.com.joegee - Friday, November 6, 2015 - link
The good old days! I remember so many of the great discussions/arguments we had. We had an Intel guy, an AMD guy, and Charlie Demerjian. Johan was there. Mike Magee would stop in. So would Chris Tom, and Kyle Bennett. It was an awesome collection of people, and the discussions were FULL of real, technical points. I always feel grateful when I think back to Ace's. It was quite a place.JohanAnandtech - Saturday, November 7, 2015 - link
And many more: Paul Demone, Paul Hsieh (K7-architect), Gabriele svelto ... Great to see that people remember. :-)