AMD Launches Carrizo: The Laptop Leap of Efficiency and Architecture Updates
by Ian Cutress on June 2, 2015 9:00 PM ESTGraphics
The big upgrade in graphics for Carrizo is that the maximum number of compute units for a 15W mobile APU moves up from six (384 SPs) to eight (512 SPs), affording a 33% potential improvement. This means that the high end A10 Carrizo mobile APUs will align with the A10 Kaveri desktop APUs, although the desktop APUs will use 6x the power. Carrizo also moves to AMD’s third generation of Graphics Core Next, meaning GCN 1.2 and similar to Tonga based retail graphics cards (the R9 285).
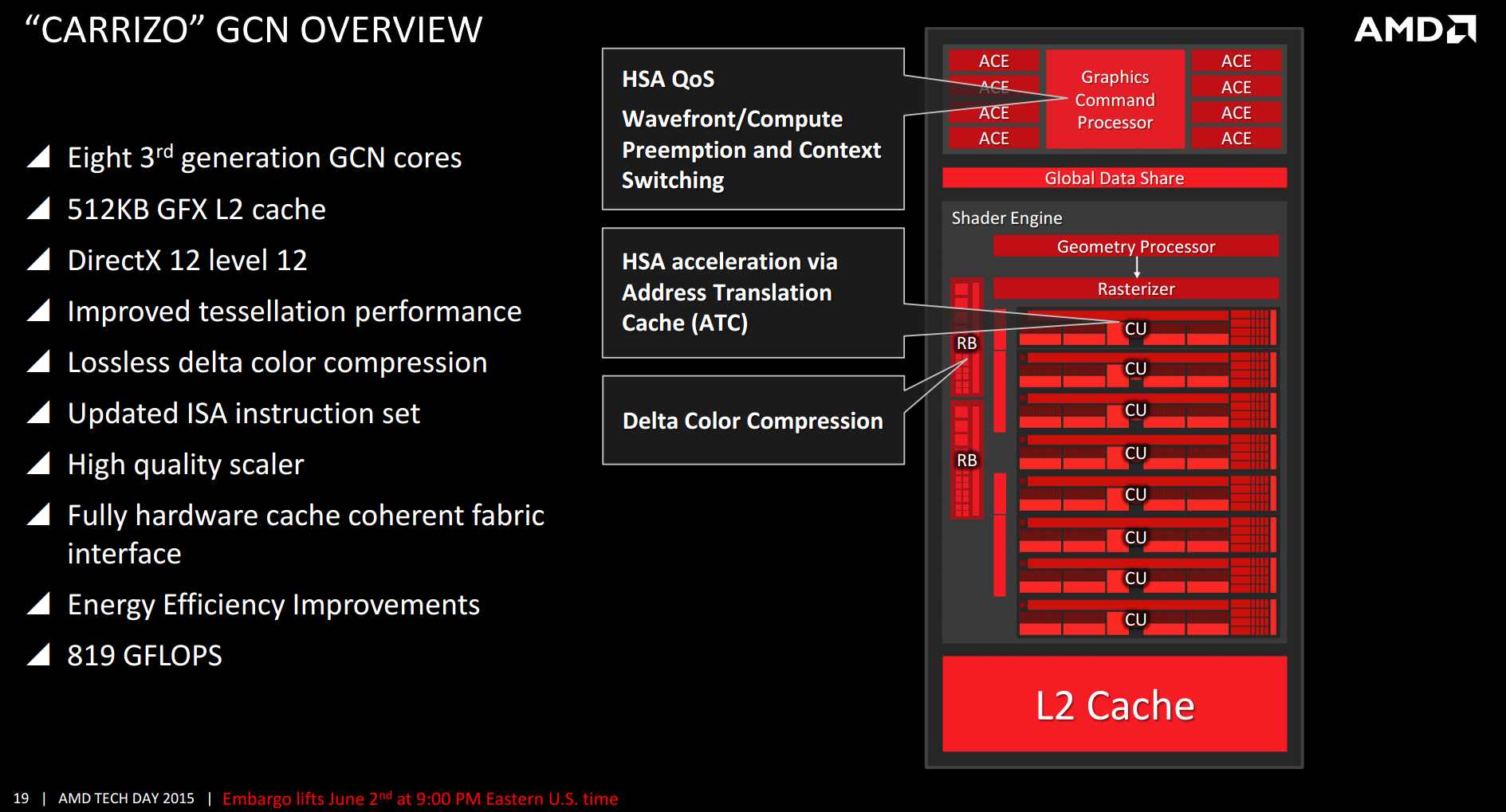
This gives DirectX 12 support, but one of AMD’s aims with Carrizo is full HSA 1.0 support. Earlier this year when AMD first released proper Carrizo details, we were told that Carrizo will support the full HSA 1.0 draft as it currently stands as it has not been ratified, and they will not push back the launch of Carrizo until that happens. So there is a chance that Carrizo will not be certified has a fully HSA 1.0 compliant APU, but very few people are predicting major changes to the specification at this point before ratification that requires hardware adjustments.
The difference between Kaveri’s ‘HSA Ready’ and Carrizo’s ‘HSA Final’ nomenclature comes down to one main feature – context switching. Kaveri can do everything Carrizo can do, apart from this. Context switching allows the HSA device to switch between work asynchronously while it waits on the other part that needs to finish. I would imagine that if Kaveri came across work that required this, it would sit there idle waiting for work to finish before continuing, which means that Carrizo would be faster in this regard.
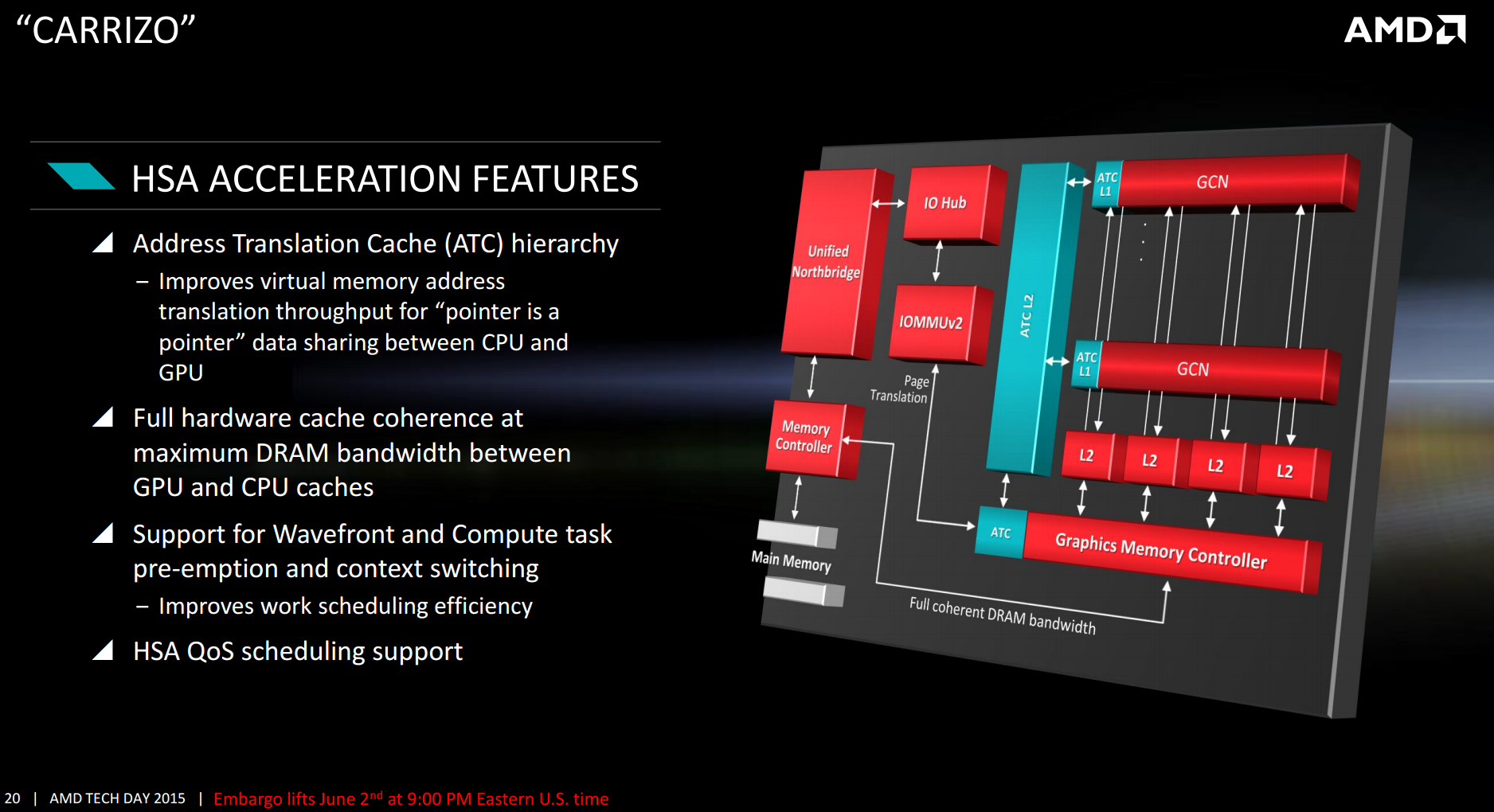
One of the key parts of HSA is pointer translation, allowing both the CPU and GPU to access the same memory despite their different interpretations of how the memory in the system is configured. One of the features on Carrizo will be the use of address translation caches inside the GPU, essentially keeping a record of which address points to which data and when an address is in a lower cache, that data can be accessed quicker. These ATC L1/L2 caches will be inside the compute units themselves as well as the GPU memory controller and an overriding ATC L2 beyond the regular L2 per compute unit.

Use of GCN 1.2 means that AMD can use their latest color compression algorithms with little effort – it takes a little more die area to implement (of which Excavator has more to play with than Kaveri), but affords performance improvements particularly in gaming. The texture data is stored losslessly to maintain visual fidelity, and move between graphics cores in this compressed state.
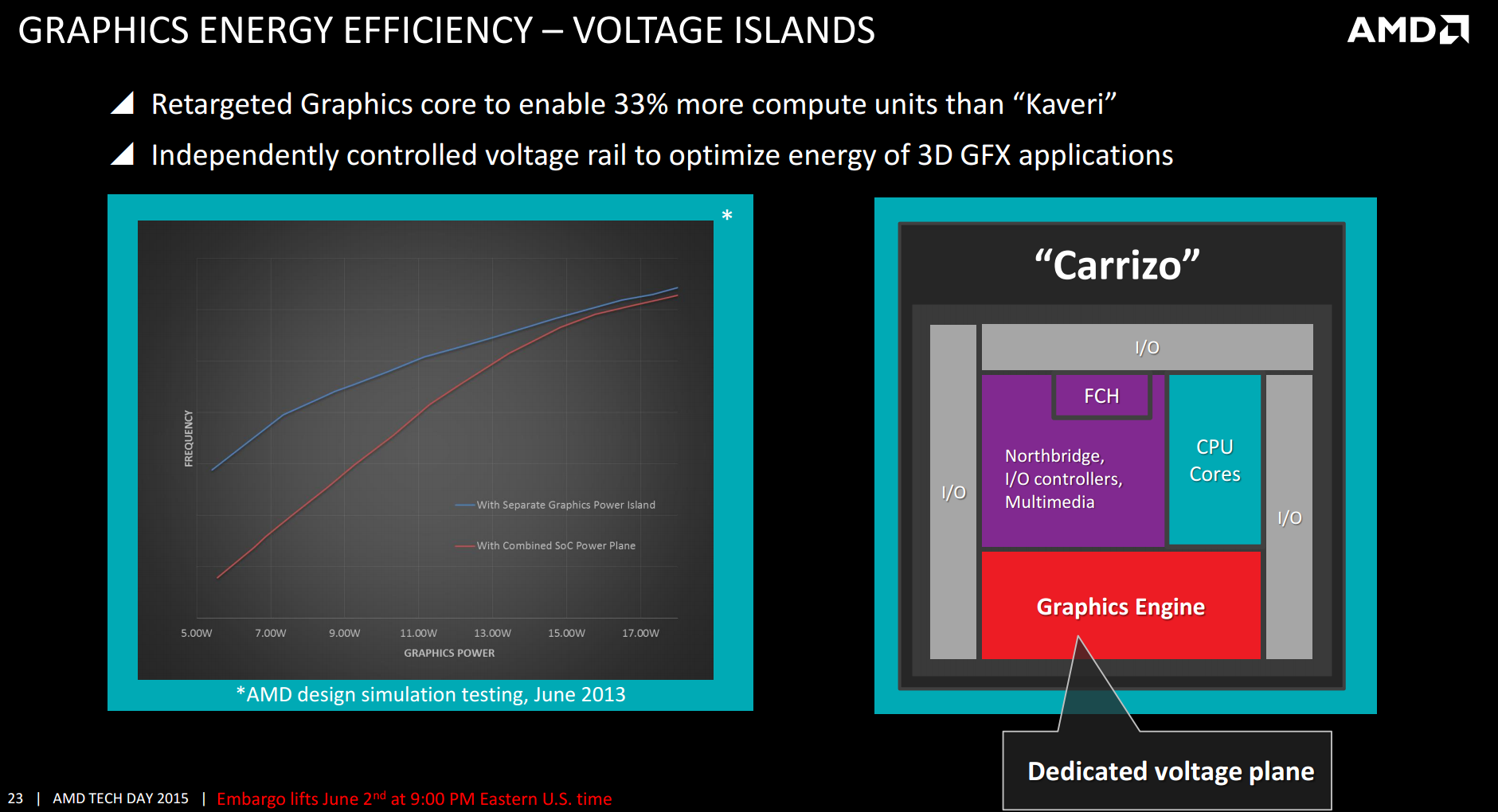
In yet more effort to suction power out of the system, the GPU will have its own dedicated voltage plane as part of the system, rather than a separate voltage island requiring its own power delivery mechanism as before. AMD’s latest numbers on the improvements here only date back to June 2013 via internal simulations, rather than an actual direct comparison.
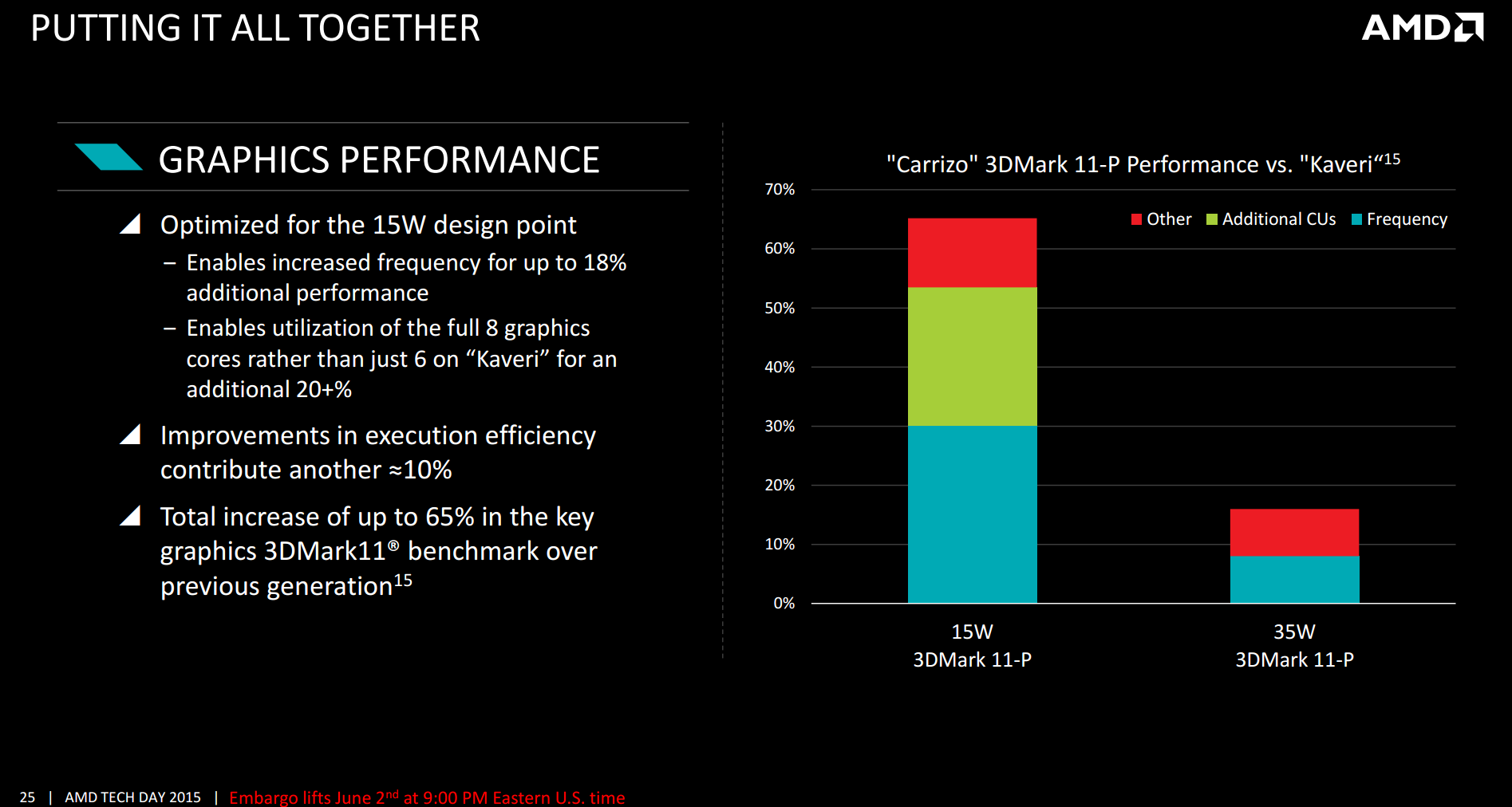
All the performance metrics rolled in, and AMD is quoting a 65% performance improvement at 15W compared to Kaveri. The adjustment in design is allowing higher frequency for the same power, combined with the additional compute units and other enhancements for the overall score. At 35W the gain is less pronounced, but more akin to regular generational improvements anyway. What we see at 35W is what we would normally expect, and it pales in comparison to the 15W numbers.








137 Comments
View All Comments
SilthDraeth - Tuesday, June 2, 2015 - link
It is sad that AMD struggles so much. I bought an HP with 1366x768, ie budget screen on most retail laptops, and an AMD A10-4600 and it plays games like Dirt 3, and stuff just fine. I haven't installed a ton of games on it. But it certainly out performs any mobile i5 or i7 that didn't have dedicated graphics card.I really hope Carrizo kicks off, and finally AMD gets some love.
meacupla - Tuesday, June 2, 2015 - link
1366x768 screens is one of the very issues that plagues AMD mobile chips.monstercameron - Tuesday, June 2, 2015 - link
So true, amd needs some kind of program to prevent oem from shipping 13*7 screens with certain socs.Penti - Tuesday, June 2, 2015 - link
1366x768 is fine in like sub 11.6-inch devices. Broadwell GT3e essentially has a stronger GPU so AMD needs to learn it's no selling point. They can't do much until they have a stronger CPU any way so both IGP and decent dGPU (switchable or whatever) makes sense with their chips. AMD chips is essentially still too weak to drive 7970m GPUs from 2012. Plus the only decent design win for mobile GCN is the new MacBook Pro 15, switchable graphics needs to be okay with Windows and Intel CPU/IGP's too. Do a shrink to 16/14 nm and make drivers that makes that happen and they should be decent enough though.BillyONeal - Wednesday, June 3, 2015 - link
1. GT3e is a 28W part; this is a 15W part. 2. GT3e is a part that costs over 3 times as much. (I'm not saying I'd buy the thing; I'm saying we need to be fair to AMD here :) )Taneli - Wednesday, June 3, 2015 - link
GT3e starts at 47W. GT3 (without Crystalwell) is available with dual core cpu in 15W (HD6000) and 28W (HD6100).Penti - Wednesday, June 3, 2015 - link
GT3 is essentially stronger without eDRAM too though.albert89 - Thursday, June 4, 2015 - link
I'd have to agree people arnt reading the stat's correctly. Broadwell beats Kaveri by a few points yet costs between one and a half and three times as much. The price of Intel APU are moving farther than the performance. And it wouldn't surprise me if Carrizo out performs Broadwell in 6 out of 10 games and that's all at 28nm !!!!!Penti - Thursday, June 4, 2015 - link
Actually when you will be able to get a Broadwell laptop (or SFF machine) for the same price, what's the point?Penti - Saturday, June 6, 2015 - link
List price for a 15W GT3 Broadwell is no more then 315 USD. Should be faster or as fast as a top-end Kaveri in game benchmarks. Is available in 370 USD NUC's barbones and soon it's in 600 dollar laptops. How much is it for a Kaveri FX-laptop? Probably a lot, and most Intel parts at least GT2+ SKU's of Haswell and Broadwell is faster than the A10 Kaveri in laptops any way. The jump from 500 to 600-700 USD just gives you a much faster notebook that's just much stronger than a Kaveri A10-device overall and even FX-7600P isn't really strong enough to game on. Carrizo doesn't really change that. AMD's numbers for 3dmark 11 on the 15W parts is on par with Iris graphics and discrete HD 7750M or 940M+ would be faster any way and is found in cheap laptops.