AMD Launches Carrizo: The Laptop Leap of Efficiency and Architecture Updates
by Ian Cutress on June 2, 2015 9:00 PM ESTIPC Increases: Double L1 Data Cache, Better Branch Prediction
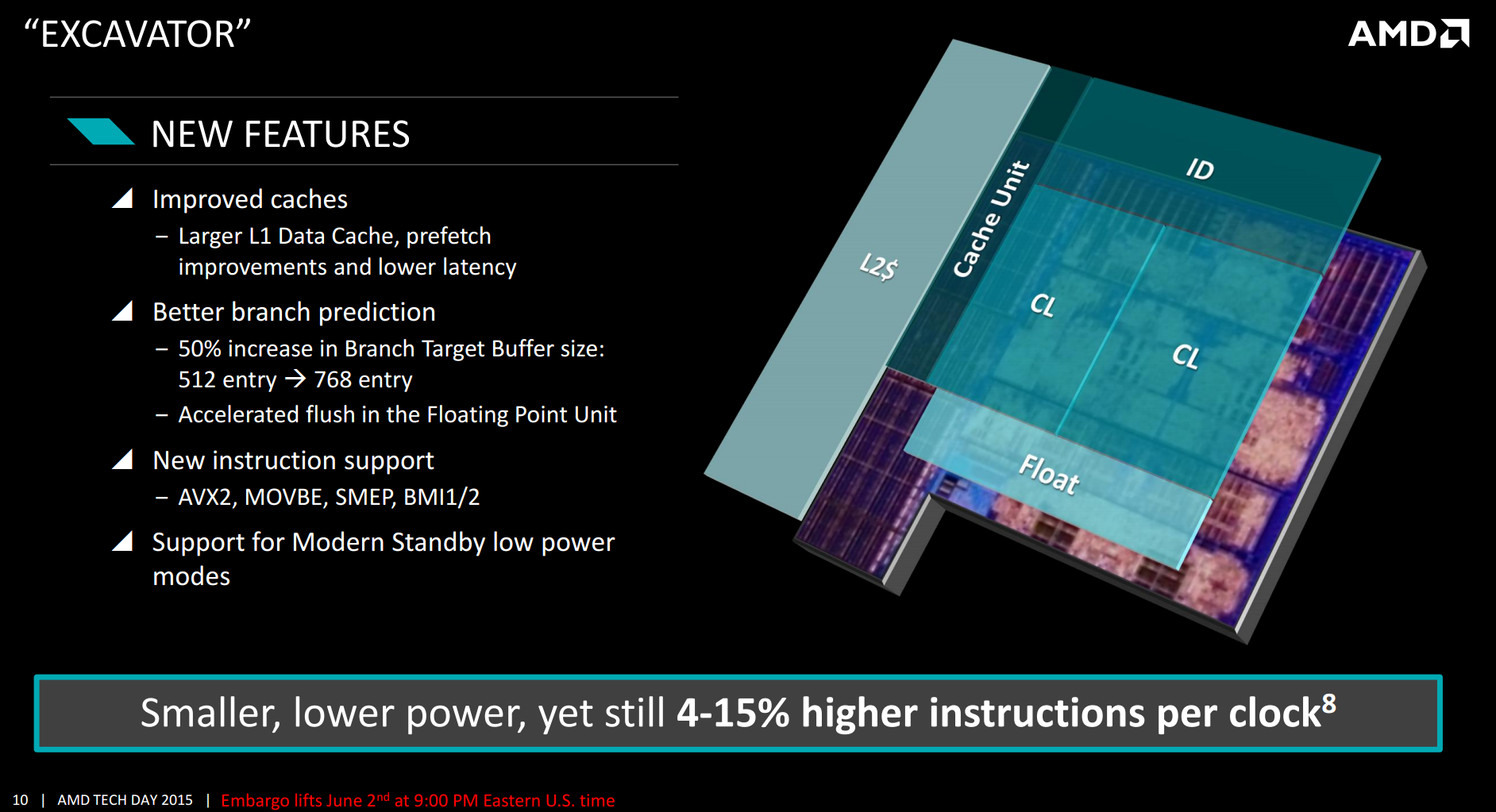
One of the biggest changes in the design is the increase in the L1 data cache, doubling its size from 64 KB to 128 KB while keeping the same efficiency. This is combined with a better prefetch pipeline and branch prediction to reduce the level of cache misses in the design. The L1 data cache is also now an 8-way associative design, but with the better branch prediction when needed it will only activate the one segment required and when possible power down the rest. This includes removing extra data from 64-bit word constructions. This reduces power consumption by up to 2x, along with better clock gating and minor adjustments. It is worth pointing out that doubling the L1 cache is not always easy – it needs to be close to the branch predictors and prefetch buffers in order to be effective, but it also requires space. By using the high density libraries this was achieved, as well as prioritizing lower level cache. Another element is the latency, which normally has to be increased when a cache increases in size, although AMD did not elaborate into how this was performed.
As listed above, the branch prediction benefits come about through a 50% increase in the BTB size. This allows the buffer to store more historic records of previous interactions, increasing the likelihood of a prefetch if similar work is in motion. If this requires floating point data, the FP port can initiate a quicker flush required to loop data back into the next command. Support for new instructions is not new, though AVX2 is something a number of high end software packages will be interested in using in the future.
These changes, according to AMD, relate to a 4-15% higher IPC for Excavator in Carrizo compared to Steamroller in Kaveri. This is perhaps a little more what we normally would expect from a generational increase (4-8% is more normal), but AMD likes to stress that this comes in addition to lower power consumption and with a reduced die area. As a result, at the same power Carrizo can have both an IPC advantage and a frequency advantage.
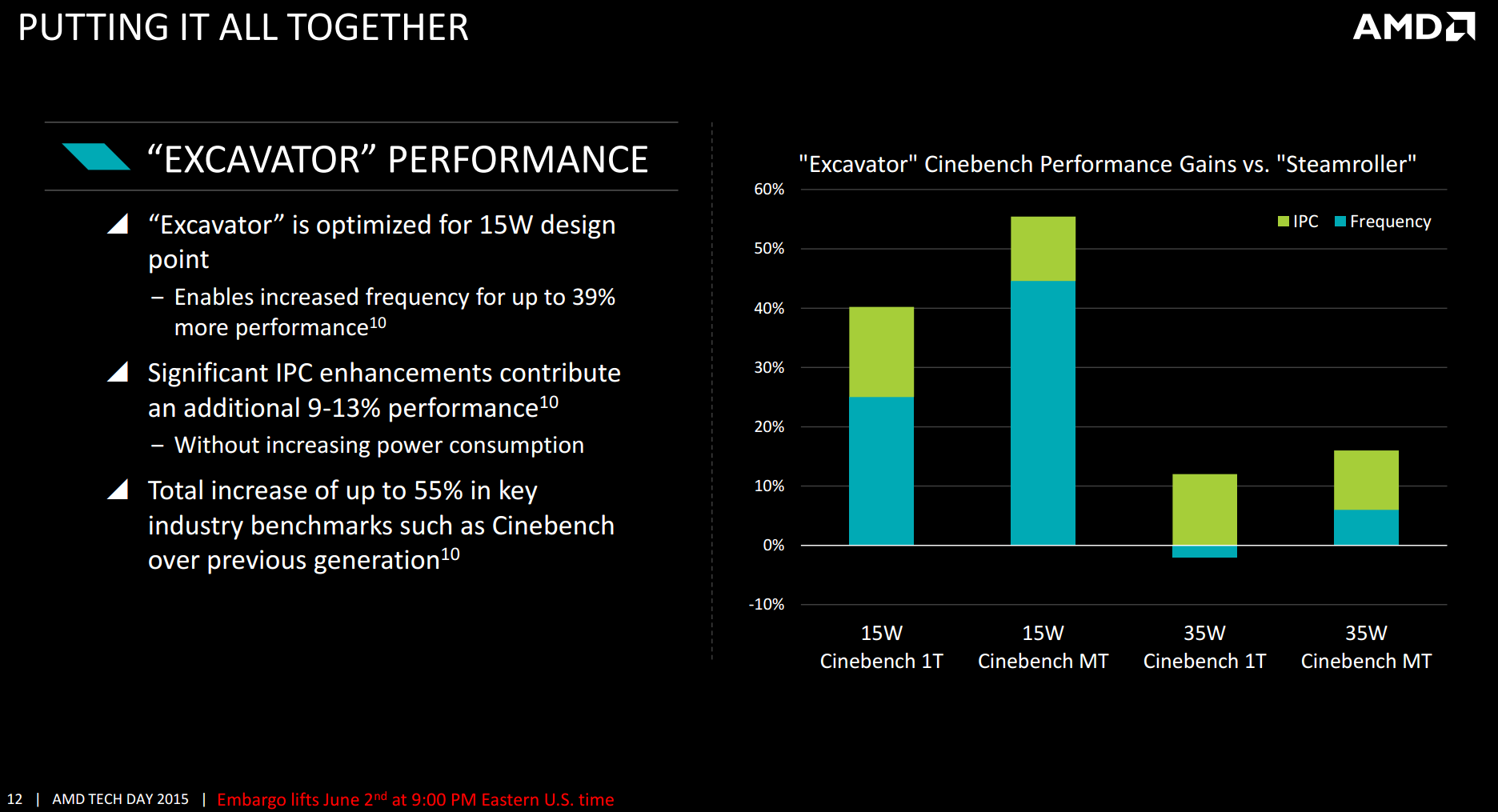
As a result, AMD states that for the same power, Cinebench single threaded results will go up 40% and multithreaded results up 55%. The benefits are fewer however the further up the power band you go despite the increase, as the higher density libraries perform slightly worse at higher power than Kaveri.








137 Comments
View All Comments
SilthDraeth - Tuesday, June 2, 2015 - link
It is sad that AMD struggles so much. I bought an HP with 1366x768, ie budget screen on most retail laptops, and an AMD A10-4600 and it plays games like Dirt 3, and stuff just fine. I haven't installed a ton of games on it. But it certainly out performs any mobile i5 or i7 that didn't have dedicated graphics card.I really hope Carrizo kicks off, and finally AMD gets some love.
meacupla - Tuesday, June 2, 2015 - link
1366x768 screens is one of the very issues that plagues AMD mobile chips.monstercameron - Tuesday, June 2, 2015 - link
So true, amd needs some kind of program to prevent oem from shipping 13*7 screens with certain socs.Penti - Tuesday, June 2, 2015 - link
1366x768 is fine in like sub 11.6-inch devices. Broadwell GT3e essentially has a stronger GPU so AMD needs to learn it's no selling point. They can't do much until they have a stronger CPU any way so both IGP and decent dGPU (switchable or whatever) makes sense with their chips. AMD chips is essentially still too weak to drive 7970m GPUs from 2012. Plus the only decent design win for mobile GCN is the new MacBook Pro 15, switchable graphics needs to be okay with Windows and Intel CPU/IGP's too. Do a shrink to 16/14 nm and make drivers that makes that happen and they should be decent enough though.BillyONeal - Wednesday, June 3, 2015 - link
1. GT3e is a 28W part; this is a 15W part. 2. GT3e is a part that costs over 3 times as much. (I'm not saying I'd buy the thing; I'm saying we need to be fair to AMD here :) )Taneli - Wednesday, June 3, 2015 - link
GT3e starts at 47W. GT3 (without Crystalwell) is available with dual core cpu in 15W (HD6000) and 28W (HD6100).Penti - Wednesday, June 3, 2015 - link
GT3 is essentially stronger without eDRAM too though.albert89 - Thursday, June 4, 2015 - link
I'd have to agree people arnt reading the stat's correctly. Broadwell beats Kaveri by a few points yet costs between one and a half and three times as much. The price of Intel APU are moving farther than the performance. And it wouldn't surprise me if Carrizo out performs Broadwell in 6 out of 10 games and that's all at 28nm !!!!!Penti - Thursday, June 4, 2015 - link
Actually when you will be able to get a Broadwell laptop (or SFF machine) for the same price, what's the point?Penti - Saturday, June 6, 2015 - link
List price for a 15W GT3 Broadwell is no more then 315 USD. Should be faster or as fast as a top-end Kaveri in game benchmarks. Is available in 370 USD NUC's barbones and soon it's in 600 dollar laptops. How much is it for a Kaveri FX-laptop? Probably a lot, and most Intel parts at least GT2+ SKU's of Haswell and Broadwell is faster than the A10 Kaveri in laptops any way. The jump from 500 to 600-700 USD just gives you a much faster notebook that's just much stronger than a Kaveri A10-device overall and even FX-7600P isn't really strong enough to game on. Carrizo doesn't really change that. AMD's numbers for 3dmark 11 on the 15W parts is on par with Iris graphics and discrete HD 7750M or 940M+ would be faster any way and is found in cheap laptops.