The AMD Radeon R9 295X2 Review
by Ryan Smith on April 8, 2014 8:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- Radeon 200
Compute
Our final set of performance benchmarks is compute performance, which for dual-GPU cards is always a mixed bag. Unlike gaming where the somewhat genericized AFR process is applicable to most games, when it comes to compute the ability for a program to make good use of multiple GPUs lies solely in the hands of the program’s authors and the algorithms they use.
At the same time while we’re covering compute performance for completeness, the high price and unconventional cooling apparatus for the 295X2 is likely to deter most serious compute users.
In any case, our first compute benchmark is LuxMark2.0, the official benchmark of SmallLuxGPU 2.0. SmallLuxGPU is an OpenCL accelerated ray tracer that is part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
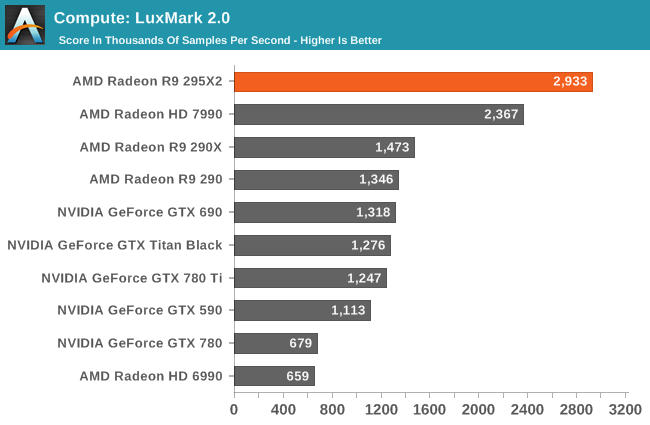
As one of the few compute tasks that’s generally multi-GPU friendly, ray tracing is going to be the best case scenario for compute performance for the 295X2. Under LuxMark AMD sees virtually perfect scaling, with the 295X2 nearly doubling the 290X’s performance under this benchmark. No other single card is currently capable of catching up to the 295X2 in this case.
Our second compute benchmark is Sony Vegas Pro 12, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
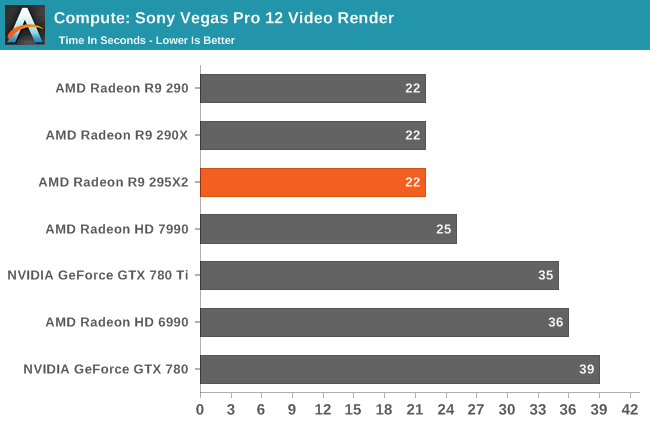
Sony Vegas Pro on the other hand sees no advantage from multiple GPUs. The 295X2 does just as well as the other Hawaii cards at 22 seconds, sharing the top of the chart, but the second GPU goes unused.
Our third benchmark set comes from CLBenchmark 1.1. CLBenchmark contains a number of subtests; we’re focusing on the most practical of them, the computer vision test and the fluid simulation test. The former being a useful proxy for computer imaging tasks where systems are required to parse images and identify features (e.g. humans), while fluid simulations are common in professional graphics work and games alike.
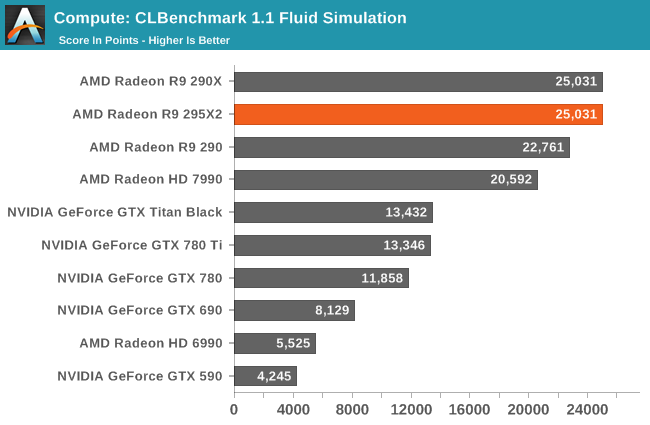
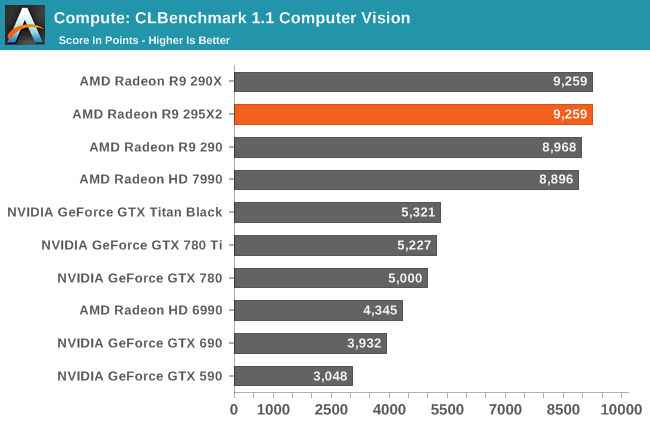
Like Vegas Pro, the CLBenchmark sub-tests we use here don't scale with additional GPUs. So the 295X2 can only match the performance of the 290X on these benchmarks.
Moving on, our fouth compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, as Folding @ Home has moved exclusively to OpenCL this year with FAHCore 17.
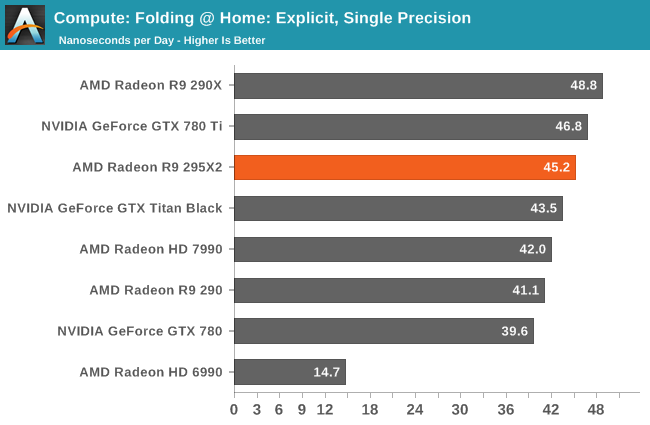
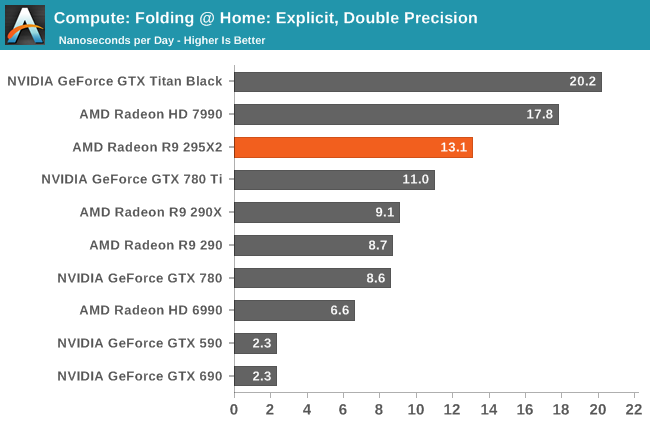
Unlike most of our compute benchmarks, Folding@Home does see some degree of multi-GPU scaling. However the outcome is really a mixed bag; single-precision performance ends up being a wash (if not a slight regression) while double-precision is seeing sub-50% scaling.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, as described in this previous article, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.

Our final compute benchmark has the 295X2 and 290X virtually tied once again, as this is another benchmark that doesn’t scale up with multiple GPUs.








131 Comments
View All Comments
eotheod - Tuesday, April 8, 2014 - link
Same performance as crossfire 290X? Might be time to do a Mini-ITX build. Half the price of Titan Z also makes it a winner.Torrijos - Tuesday, April 8, 2014 - link
A lot of compute benchmark see no improvement from a single 290X...What is happening?
Ryan Smith - Tuesday, April 8, 2014 - link
Most of these compute benchmarks do not scale with multiple GPUs. We include them for completeness, if only to not so subtly point out that not everything scales well.CiccioB - Tuesday, April 8, 2014 - link
Why not adding more real life computing tests like iRay that runs both for CUDA and OpenCL?Syntethic tests are really meaningless as they depends more on the particular istructions used to do... ermm.. nothing?
fourzeronine - Tuesday, April 8, 2014 - link
iRay runs on CUDA only. LuxRender should be used for GPU raytrace benchmarking. http://www.luxrender.net/wiki/LuxMarkAlthough the best renderers that support OpenCL are hybrid systems that only solve some of the problems on GPU and a card like this would never be fully utilized.
The best OpenCL bench mark to have would be an agisoft photoscan dense point cloud generation.
Musaab - Wednesday, April 9, 2014 - link
I have one question why didn't you use 2 R9 290X with water cool or 2 GTX 780Ti with water cool. I hate this marketing Mumbo Jumbo. if I want to pay this money I will chose two cards from above with water cool and with some OC work they will feed this card the dust and for the same money I can buy 2 R9 290 or 2 GTX 780.Musaab - Wednesday, April 9, 2014 - link
Sorry I mean three R9290 or three GTX 780spartaman64 - Sunday, June 1, 2014 - link
i doubt you can afford 3 of them and water cool them and 3 of them would have a very high tdp also many people would run into space restraints and the r9 295x2 out performs 2 780 ti in slikrutou - Tuesday, April 22, 2014 - link
Because water blocks and radiators don't grow on trees. Reviewers only test what they're given, all of which are stock.patrickjp93 - Friday, May 2, 2014 - link
They pretty much do grow on trees. You can get even a moderately good liquid cooling loop for 80 bucks.