The iPhone 5s Review
by Anand Lal Shimpi on September 17, 2013 9:01 PM EST- Posted in
- Smartphones
- Apple
- Mobile
- iPhone
- iPhone 5S
GPU Architecture
Dating back to the original iPhone, Apple has relied on GPU IP from Imagination Technologies. In recent years, the iPhone and iPad lines have pushed the limits of Img’s technology - integrating larger and higher performing GPUs than all other Img partners. Apple definitely attempted to obfuscate its underlying GPU architecture this time around for some reason.
Dating back to a year ago I got a lot of tips saying that Apple would be integrating Imagination Technologies’ PowerVR Series 6 GPU this generation, but I needed more proof.

The first indication that this isn’t simply a Series 5XT part is the listed support for OpenGL ES 3.0. The only GPUs presently shipping with ES 3.0 support are Qualcomm’s Adreno 3xx (which is only integrated into Qualcomm silicon), ARM’s Mali-T6xx series and PowerVR Series 6. NVIDIA’s Tegra 4 GPU doesn’t support ES 3.0, and it’s too early for Logan/mobile Kepler. With Qualcomm out of the running that leaves Mali and PowerVR Series 6.
“All GPUs used in iOS devices use tile-based deferred rendering (TBDR).”
Apple’s developer documentation lists all of its SoCs as supporting Tile Based Deferred Rendering (TBDR). If you ask Imagination, they will tell you that they are the only ones with a true TBDR implementation. However if you look at ARM’s Mali-T6xx documentation, ARM also claims its GPU is a TBDR.
The real hint comes with anti-aliasing support:
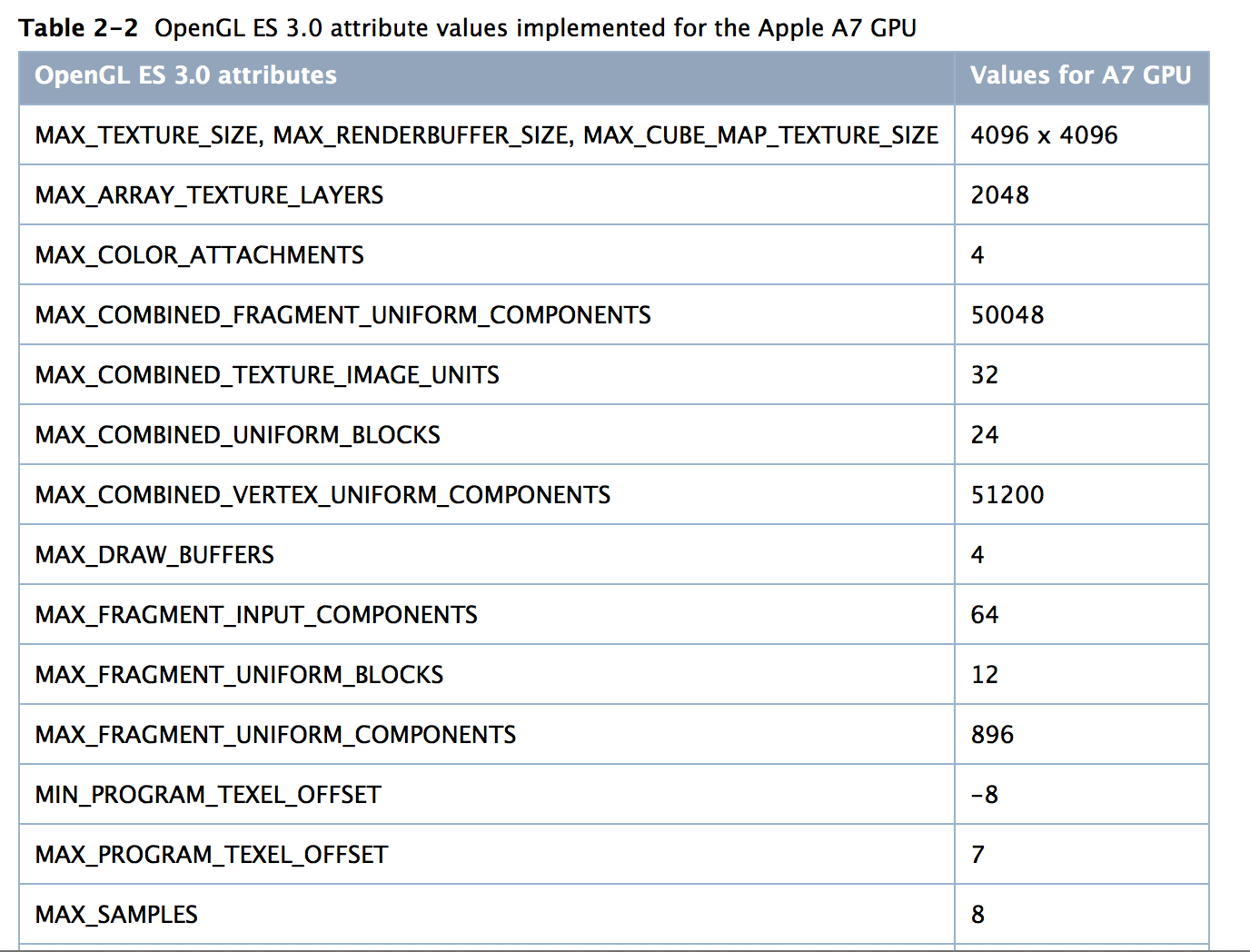
The last line in the screenshot above, MAX_SAMPLES = 8. That’s a reference to 8 sample MSAA, a mode that isn’t supported by ARM’s Mali-T6xx hardware - only PowerVR Series 6 (Mali-T6xx supports 4x and 16x AA modes).
There are some other hints here that Apple is talking about PowerVR Series 6 when it references the A7’s GPU:
“The A7 GPU processes all floating-point calculations using a scalar processor, even when those values are declared in a vector. Proper use of write masks and careful definitions of your calculations can improve the performance of your shaders. For more information, see “Perform Vector Calculations Lazily” in OpenGL ES Programming Guide for iOS.
Medium- and low-precision floating-point shader values are computed identically, as 16-bit floating point values. This is a change from the PowerVR SGX hardware, which used 10-bit fixed-point format for low-precision values. If your shaders use low-precision floating point variables and you also support the PowerVR SGX hardware, you must test your shaders on both GPUs.”
As you’ll see below, both of the highlighted statements apply directly to PowerVR Series 6. With Series 6 Imagination moved to a scalar architecture, and in ImgTec’s developer documentation it confirms that the lowest precision mode supported is FP16.
All of this leads me to confirm what I heard would be the case a while ago: Apple’s A7 is the first shipping mobile silicon to integrate ImgTec’s PowerVR Series 6 GPU.
Now let’s talk about hardware.
The A7’s GPU Configuration: PowerVR G6430
Previously known by the codename Rogue, series 6 has been announced in the following configurations:
| PowerVR Series 6 "Rogue" | ||||||||||||
| GPU | # of Clusters | # of FP32 Ops per Cluster | Total FP32 Ops | Optimization | ||||||||
| G6100 | 1 | 64 | 64 | Area | ||||||||
| G6200 | 2 | 64 | 128 | Area | ||||||||
| G6230 | 2 | 64 | 128 | Performance | ||||||||
| G6400 | 4 | 64 | 256 | Area | ||||||||
| G6430 | 4 | 64 | 256 | Performance | ||||||||
| G6630 | 6 | 64 | 384 | Performance | ||||||||
Based on the delivered performance, as well as some other products coming down the pipeline I believe Apple’s A7 features a variant of the PowerVR G6430 - a 4 cluster Rogue design optimized for performance (vs. area).
Rogue is a significant departure from the Series 5XT architectures that were used in the iPhone 5, iPad mini and iPad 4. The biggest change? A switch to a fully scalar architecture, similar to the present day AMD and NVIDIA GPUs.
Whereas with 5XT designs we talked about multiple cores, the default replication unit in Rogue is a “cluster”. Each core in 5XT replicated all hardware, while each cluster in Rogue only replicates the shader ALUs and texture hardware. Rogue is still a unified architecture, but the front end no longer scales 1:1 with shading hardware. In many ways this approach is a lot more sensible, as it is typically how you build larger GPUs.
In 5XT, each core featured a number of USSE2 pipelines. Each pipeline was capable of a Vec4 multiply+add plus one additional FP operation that could be dual-issued under the right circumstances. Img never detailed the latter so I always counted flops by looking at the number of Vec4 MADs. If you count each MAD as two FP operations, that’s 8 FLOPS per USSE2 pipe. Each USSE2 was a SIMD, so that’s one instruction across all 4 slots and not some combination of instructions. If you had 3 MADs and something else, the USSE2 pipe would act as a Vec3 unit instead. The same goes for 1 or 2 MADs.
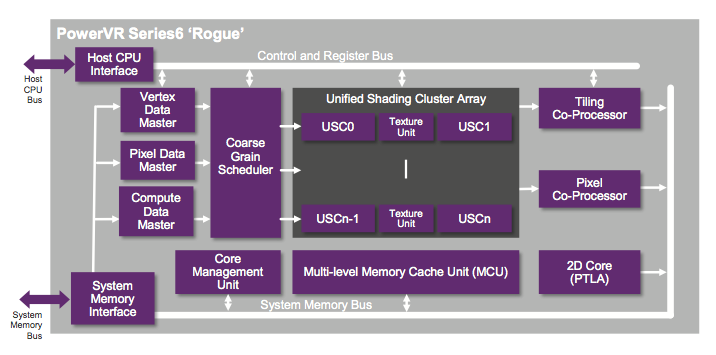
With Rogue the USSE2 pipe is gone and replaced by a Unified Shading Cluster (USC). Each USC is a 16-wide scalar SIMD, with each slot capable of up to 4 FP32 ops per clock. Doing the math, a single USC implementation can do a total of 64 FP32 ops per clock - the equivalent of a PowerVR SGX 543MP2. Efficiency obviously goes up with a scalar design, so realizable performance will likely be higher on Rogue than 5XT.
The A7 is a four cluster design, so that four USCs or a total of 256 FP32 ops per clock. At 200MHz that would give the A7 twice the peak theoretical performance of the GPU in the iPhone 5. And from what I’ve heard, the G6430 is clocked much higher than that.
There’s more graphics horsepower under the hood of the iPhone 5s than there is in the iPad 4. While I don’t doubt the iPad 5 will once again widen that gap, keep in mind that the iPhone 5s has less than 1/4 the number of pixels as the iPad 4. If I were a betting man, I’d say that the A7 was designed not only to drive the 5s’ 1136 x 640 display, but also a higher res panel in another device. Perhaps an iPad mini with Retina Display? There’s no solving the memory bandwidth requirements, but the A7 surely has enough compute power to get there. There's also the fact that Apple has prior history of delivering an SoC that wasn’t perfect for the display (e.g. iPad 3).
GPU Performance
As I mentioned earlier, the iPhone 5s is the first Apple device (and consumer device in the world) to ship with a PowerVR Series 6 GPU. The G6430 inside the A7 is a 4 cluster configuration, with each cluster featuring a 16-wide array of SIMD pipelines. Whereas the 5XT generation of hardware used a 4-wide vector architecture (1 pixel per clock, all 4 color components per SIMD), Series 6 moves to a scalar design (think 16 pixels per clock, one color per clock). Each pipeline is capable of two FP32 MADs per clock, for a total of 64 FP32 operations per clock, per cluster. With the A7's 4 cluster GPU, that works out to be the same throughput per clock as the 4th generation iPad.
Imagination claims its new scalar architecture is not only more computationally dense, but also far more efficient. With the transition to scalar GPU architectures in the PC space we generally saw efficiency go up, so I'm inclined to believe Imagination's claims here.
Apple claims up to a 2x increase in GPU performance compared to the iPhone 5, but just looking at the raw numbers in the table above there's far more shading power under the hood of the A7 than only "2x" the A6.
| Mobile SoC GPU Comparison | ||||||||||||
| PowerVR SGX 543 | PowerVR SGX 543MP2 | PowerVR SGX 543MP3 | PowerVR SGX 543MP4 | PowerVR SGX 554 | PowerVR SGX 554MP2 | PowerVR SGX 554MP4 | PowerVR G6430 | |||||
| Used In | - | iPad 2/iPhone 4S | iPhone 5 | iPad 3 | - | - | iPad 4 | iPhone 5s | ||||
| SIMD Name | USSE2 | USSE2 | USSE2 | USSE2 | USSE2 | USSE2 | USSE2 | USC | ||||
| # of SIMDs | 4 | 8 | 12 | 16 | 8 | 16 | 32 | 4 | ||||
| MADs per SIMD | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 32 | ||||
| Total MADs | 16 | 32 | 48 | 64 | 32 | 64 | 128 | 128 | ||||
| GFLOPS @ 300MHz | 9.6 GFLOPS | 19.2 GFLOPS | 28.8 GFLOPS | 38.4 GFLOPS | 19.2 GFLOPS | 38.4 GFLOPS | 76.8 GFLOPS | 76.8 GFLOPS | ||||
GFXBench 2.7
As always, we'll start with GFXBench (formerly GLBenchmark) 2.7 to get a feel for the theoretical performance of the new GPU. GFXBench 2.7 tends to be more computationally bound than most games as it is frequently used by silicon vendors to stress hardware, not by game developers as an actual performance target. Keep that in mind as we get to some of the actual game simulation results.

Twice the fill rate of the iPhone 5, and clearly higher than anything else we've tested. Rogue is off to a good start.
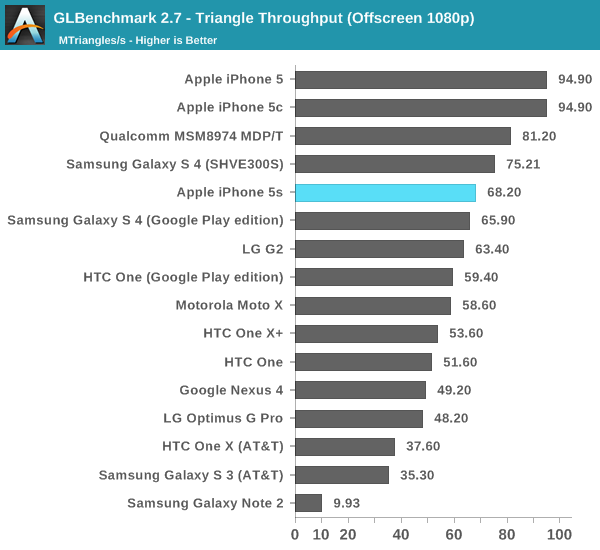
What's this? A performance regression? Remember what I said earlier in the description of Rogue. Whereas 5XT replicated nearly the entire GPU for "multi-core" versions, multi-cluster versions of Rogue only replicate at the shader array. The result? We don't see the same sort of peak triangle setup scaling we did back on multi-core 5XT parts. I don't suppose this will be a big issue in actual games (and likely a better balance between triangle setup/rasterization and shading hardware), but it's worth pointing out.
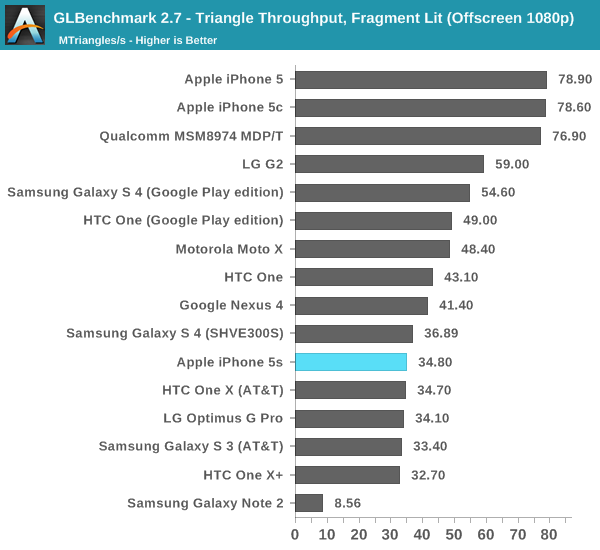
This is the worst case regression we've seen from 5XT to Rogue. Its clear that per chip triangle rates are much higher on Rogue, but with a many core implementation of 5XT there's just no competing. I suspect this change is part of how Img was able to increase the overall density of Rogue vs. 5XT. Now the question is whether or not this regression will actually appear in games? To find out we turn to the two game simulation tests in GFXBench 2.7, starting with the most stressful one: T-Rex HD.
As always, the onscreen tests run at a device's native resolution with v-sync enabled, while the offscreen results happen at 1080p and v-sync disabled.
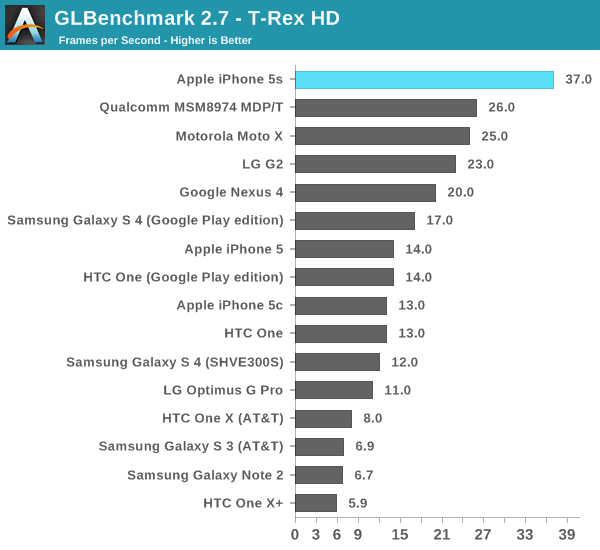
As expected, the G6430 in the iPhone 5s is more than twice the speed of the part in the iPhone 5. It is also the first device we've tested capable of breaking the 30 fps barrier in T-Rex HD at its native resolution. Given just how ridiculously intense this test is, I think it's safe to say that the iPhone 5s will probably have the longest shelf life from a gaming perspective of any previous iPhone.

The offscreen test helps put the G6430's performance in perspective. Here we show the 5s barely falling behind Qualcomm's Adreno 330 (Snapdragon 800). There are obvious thermal differences between the two platforms, but if we look at the G2's performance (another S800/A330 part) we get a better indication of an apples to apples comparison. Looking at the leaked Nexus 5 (also S800/A330) T-Rex HD scores confirms what we're seeing above. In a phone, it looks like the G6430 is a bit quicker than Qualcomm's Adreno 330.
The Egypt HD tests are much lighter and a lot closer to the workload of a lot of games on the store today, although admittedly it is getting a little light.
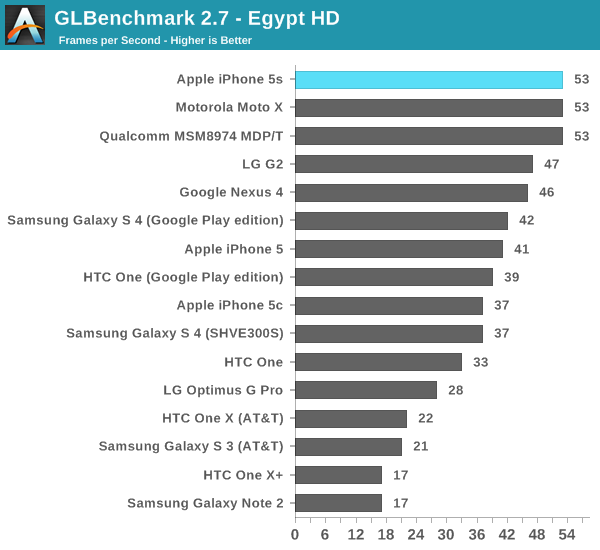
Onscreen we're at Vsync already, something the iPhone 5 wasn't capable of doing. The 5s should have no issues running most games at 30 fps.
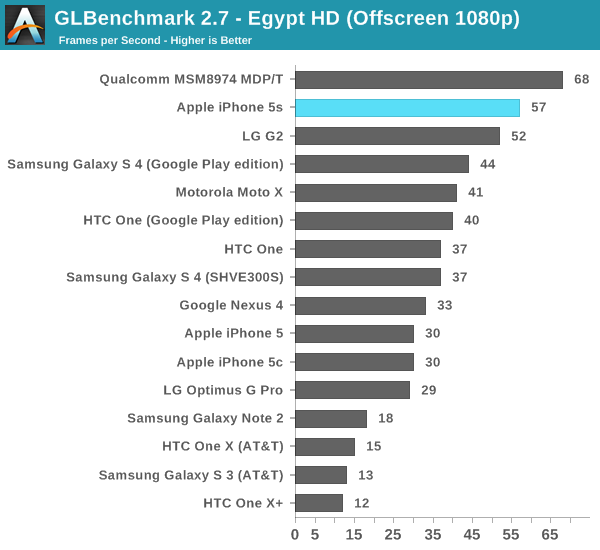
Offscreen, even at 1080p, performance doesn't really change. Qualcomm's Adreno 330 is definitely faster, at least in the MDP/T. In the G2, its performance lags behind the G6430. I really want to measure power on these things.
3DMark
3DMark finally released an iOS version of its benchmark, enabling us to run the 5s through on yet another test. As we've discovered in the past, 3DMark is far more of a CPU test than GFXBench. While CPU load will range from 6 - 25% during GFXBench, we'll see usage greater than 50% on 3DMark - even during the graphics tests. 3DMark is also heavily threaded, with its physics test taking advantage of quad-core CPUs.
With the iOS release of the benchmark comes a new offscreen rendering mode called Unlimited. The benchmark is the same but it renders offscreen at 720p with the display only being updated once every 100 frames to somewhat get around vsync. Because of the new test we don't have a ton of comparison data, so I've included whatever we've got at this point.

3DMark ends up being more of a CPU and memory bandwidth test rather than a raw shader performance test like GFXBench and Basemark X. The 5s falls behind the Snapdragon 800/Adreno 330 based G2 in overall performance. To find out how much of that is GPU performance and how much is a lack of four cores, let's look at the subtests.
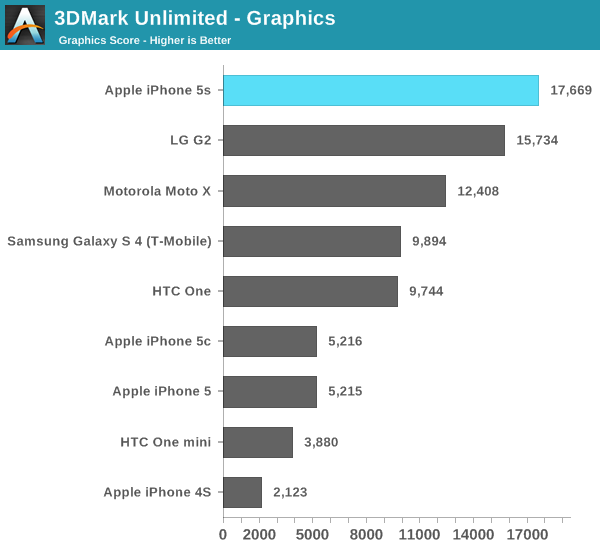
The graphics test is more GPU bound than CPU bound, and here we see the G6430 based iPhone 5s pull ahead. Note how well the Moto X does because of its very high clocked CPU cores rather than its GPU. Although this is a graphics test, it's still well influenced by CPU performance.
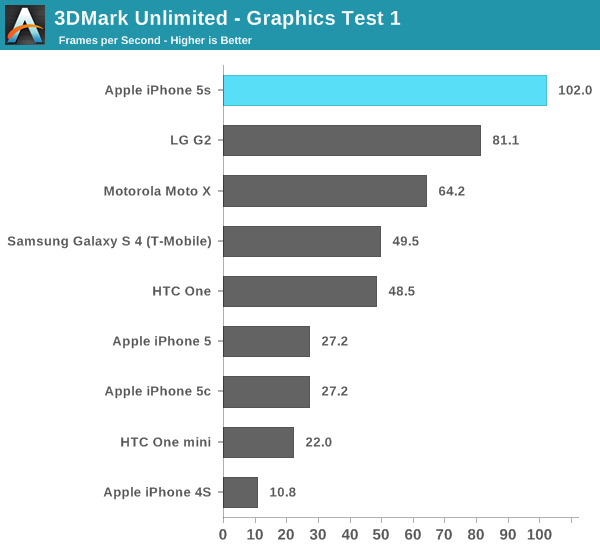
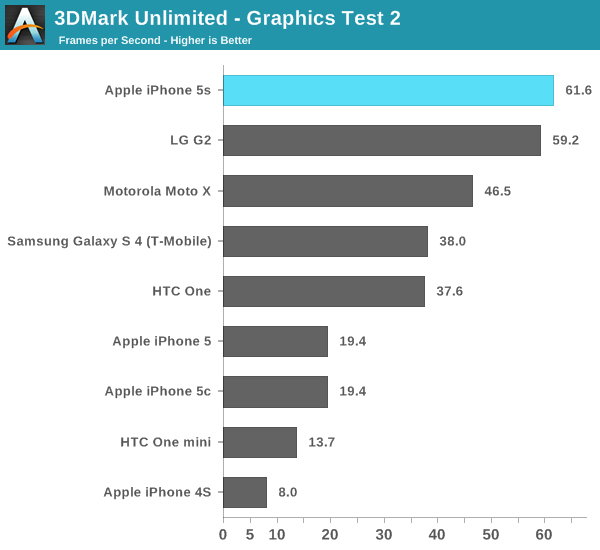

The physics test hits all four cores in a quad-core chip and explains the G2 pulling ahead in overall performance. Note that I saw no improvement in this largely CPU bound test, leading me to believe that we've hit some sort of a bug with 3DMark and the new Cyclone core.

Basemark X
Basemark X is a new addition to our mobile GPU benchmark suite. There are no low level tests here, just some game simulation tests run at both onscreen (device resolution) and offscreen (1080p, no vsync) settings. The scene complexity is far closer to GLBenchmark 2.7 than the new 3DMark Ice Storm benchmark, so frame rates are pretty low.
Unfortunately I ran into a bug with Basemark X under iOS 7 on the iPhone 5/5c/5s that prevented the off screen test from completing, leaving me only with on-screen results at native resolution.
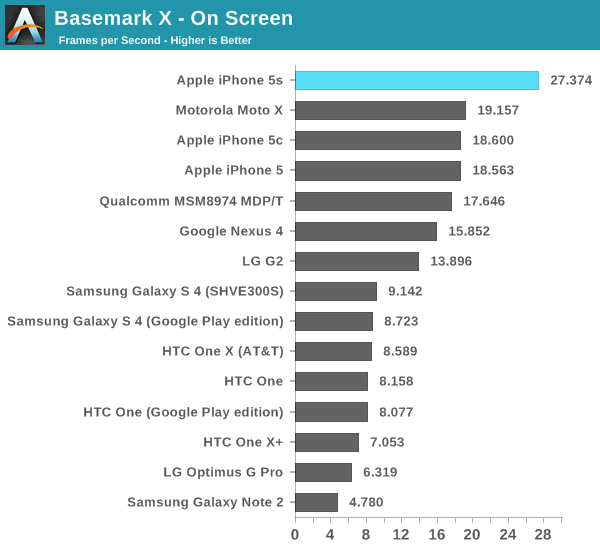
Once again we're seeing greater than 2x scaling comparing the iPhone 5s to the 5.








464 Comments
View All Comments
MatthiasP - Tuesday, September 17, 2013 - link
Wow, first real review on the web AND deep as always, a very nice job from Anand. :)sfaerew - Wednesday, September 18, 2013 - link
Benchmarks(GFXBench 2.7,3DMark.Basemark X.etc.) are AArch64 version?There are 30~40% performance gap between v32geekbench and v64geekbench.
INT(ST)1471 vs 1065.
FP(ST)1339 vs 983
Wilco1 - Wednesday, September 18, 2013 - link
And Bay Trail Geekbench at 2.4GHz: 1063 (INT), 866 (FP)So A7 has beaten BT already by a huge margin despite BT not even being for sale yet...
TraderHorn - Wednesday, September 18, 2013 - link
You're comparing 64bit A7 vs 32bit BT. The 32bit #s are dead even. It'll be interesting to see if BT gets a similar performance boost when Win8 64bit versions are released in 1h 2014.Wilco1 - Wednesday, September 18, 2013 - link
BT's 32-bit result includes hardware accelerated AES, which skews its score (without it, its score is ~936). The 64-bit A7 result does also use hardware acceleration, so it is more comparable.Yes BT will get a speedup from 64-bit as well, but won't be nearly as much as A7 gets: its 32-bit result already has the AES acceleration, and x64 nearly isn't as different from x86 as A64 is from A32.
However the interesting things is that not even in 32-bit A7 wins by a good margin, but that it wins despite running at almost half the frequency of Bay Trail... Forget about Bay Trail, this is Haswell territory - the MacBook Air with the 15W 3.3GHz i7-4650U scores 3024 INT and 3003 FP.
Now imagine a quad core tablet/laptop version of the A7 running at 2GHz on TSMC 20nm next year.
smartypnt4 - Wednesday, September 18, 2013 - link
Why does the frequency matter? If the TDP of the chips are similar (Bay Trail was tested and verified by Anand as using 2.5W at the SoC level under load), who gives a flip about the frequency?If Apple wanted to double the frequency of the chip, they'd need something on the order of 4x the amount of power it already consumes (assuming a back-of-the-napkin quadratic relationship, which is approximately correct), putting it at ~6-8W or so at full load. That's assuming such a scaling could even be done, which is unlikely given that Apple built the thing to run at 1.3GHz max. You can't just say "oh, I want these to switch faster, so let's up the voltage." There's more that goes in to the ability to scale voltage than just the process node you're on.
Now, I will agree that this does prove that if Apple really wanted to, they could build something to compete with Haswell in terms of raw throughput. Next year's A8 or whatever probably will compete directly with Haswell in raw theoretical integer and FP throughput, if Apple manages to double performance again. That's not a given since they had to use ~50% more transistors to get a performance doubling from the A6 to the A7, and building a 1.5B transistor chip is nontrivial since yields are inversely proportional to the number of transistors you're using.
Next year will be really interesting, though. What with Apple's next stuff, Broadwell, the first A57 designs, Airmont, and whatever Qualcomm puts out (haven't seen anything on that, which is odd for Qualcomm.)
Wilco1 - Wednesday, September 18, 2013 - link
Frequency & process matters. Current phones use about 2W at max load without the screen (see recent Nexus 7 test), so the claimed 2.5W just for BT is way too much for a phone. That means (as you explained) it must run at a lower frequency and voltage to get into phones - my guess we won't see anything faster than the Z3740 with a max clock of 1.8GHz. Therefore the A7 will extend its lead even further.According to TSMC 20nm will give a 30% frequency boost at the same power. So I'd expect that a 2GHz A7 would be possible on 20nm using only 35% more power. That means the A7 would get 75% more performance at a small cost in power consumption. This is without adding any extra transistors.
Add some tweaks (like faster memory) and such a 2GHz A7 would be similar in performance as the 15W Haswell in MacBook Air. So my point is that with a die shrink and a slight increase in power they already have a Haswell competitor.
smartypnt4 - Wednesday, September 18, 2013 - link
Frequency and process matter in that they affect power consumption. If Intel can get Bay Trail to do 2.4GHz on something like 1.0V, then the power should be fine. Current Haswell stuff tops out its voltage around 1.1V or so in laptops (if memory serves), so that's not unreasonable.All of this assumes Geekbench is valid for comparing HSW on Win8 to ARMv8/Cyclone on iOS, which I have serious reservations about attempting to do.
The other issue I have is this: you're talking about a 50% clock boost giving a 100% increase in performance if we look at the Geekbench scores. That's simply not possible. Had you said "raise the clock to 1.6-1.7GHz and give it 4 cores," I'd be right behind you in a 2x theoretical performance increase. But a 50% clock boost will never yield a 100% increase with the same core, even if you change the memory controller.
Also, somehow your math doesn't add up for power... Are you hypothesizing that a 2GHz A7 (with 75% of the performance of Haswell 15W, not the same - as per Geekbench) can pull 2.6W while Haswell needs 15W to run that test? Granted, Haswell integrates things that the A7 doesn't. Namely, more advanced I/O (PCIe, SATA, USB, etc.), and the PCH. Using very fuzzy math, you can claim all of that uses 1/2 the power of the chip.
That brings Haswell's power for compute down to 7-8W, more or less. And you're going to tell me that Apple has figured out how to get 75% of the performance of a 7W part in 2.6W, and Intel hasn't? Both companies have ~100k employees. One is working on a ton of different stuff, and one makes processors, basically exclusively (SSDs and WiFi stuff too, but processors is their main drive). You're telling me that a (relatively) small cadre of guys at Apple have figured out how to do it, and Intel hasn't done it yet on a part that costs ~6x as much after trying to get deep into the mobile space for years. I find that very hard to believe.
Even with the 14nm shrink next year, you're talking about a 30% power savings for Intel's stuff. That brings the 15W total down to 10.5W, and the (again, super, ridiculously fuzzy) computing power to ~5-6W. On a full node smaller than what Apple has access to. And you're saying they'd hypothetically compete in throughput with a 2.6W part. I'm not sure I believe that.
Then again, I suppose theoretical bandwidth could be competitive. That's simply a factor of your peak IPC, not your average IPC while the device is running. I don't know enough about the low level architecture of the A7 (no one does), so I'll just leave it here I guess.
I'm gonna go now... I'm starting to reason in circles.
Wilco1 - Wednesday, September 18, 2013 - link
The sort of "simple" tweaks I was thinking of are: an improved memory controller and prefetcher, doubling of L2, larger branch predictor tables. Assuming a 30% gain due to those tweaks, the result is a 100% speedup at 2GHz (1.3 to 2.0 GHz is a 54% speedup, so you get 1.54 * 1.3 = 2.0x perf). The 30% gain due to tweaks is pure speculation of course, however NVidia claims 15-30% IPC gain for similar tweaks in Tegra 4i, so it's not entirely implausible. As you say a much simpler alternative would be just to double the cores, but then your single threaded performance is still well below that of Haswell.You can certainly argue some reduction in the 15W TDP of Haswell due to IO, however with Turbo it will try to use most of that 15W if it can (the Air goes up to 3.3GHz after all).
Yes I am saying that a relative newcomer like Apple can compete with Intel. Intel may be large, but they are not infallible, after all they made the P4, Itanium and Atom. A key reason AMD cited for moving into ARM servers was that designing an ARM CPU takes far less effort than an equivalent performing x86 one. So the ISA does still matter despite some claiming it no longer does.
smartypnt4 - Wednesday, September 18, 2013 - link
My point wasn't that Apple can't compete; far from it. If anything, the A7 shows they can compete for the most part. However, what you suggest is that Apple could theoretically have the same performance as Intel on a full node process larger at half the power. Ihave no illusions that Intel is infallible. Stuff like Larrabee and the underwhelming GPU in Bay Trail prove that they aren't. I just seriously doubt that Apple could beat Intel at its own game. Specifically, in CPU performance, which is an area it's dominated for years. It's possible, but I find it relatively unlikely, especially this early in Apple's lifetime as a chip designer.
On a different note, after looking at the Geekbench results more, I feel like it's improperly weighted. The massive performance improvement in AES and SHA encryption may be skewing the overall result... I need to dig more in to Geekbench before coming to an actual conclusion. I'm also still not convinced that comparing cross-platform results is actually valid. I'd like to believe it is, but I've always had reservations about it.