AMD Radeon HD 7990 Review: 7990 Gets Official
by Ryan Smith on April 24, 2013 12:01 AM EST- Posted in
- GPUs
- AMD
- Radeon
- Radeon HD 7000
- Tahiti
Compute
As always we'll start with our DirectCompute game example, Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes. While DirectCompute is used in many games, this is one of the only games with a benchmark that can isolate the use of DirectCompute and its resulting performance.
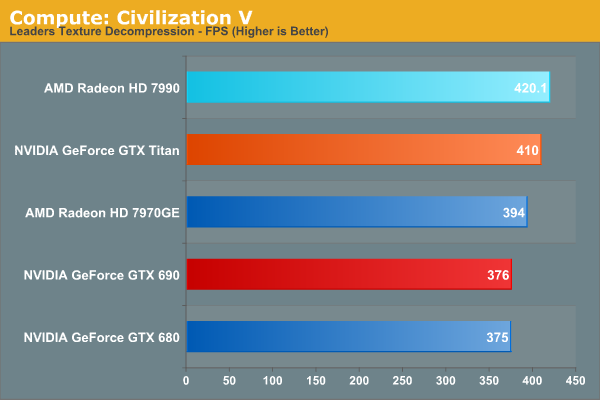
Civ V's texture compression routines are technically mutli-GPU capable, but multi-GPU scaling has never been particularly impressive here. So this test mostly reinforces what we already know about the Tahiti GPU being very capable in most DirectCompute workloads.
Our next benchmark is LuxMark2.0, the official benchmark of SmallLuxGPU 2.0. SmallLuxGPU is an OpenCL accelerated ray tracer that is part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
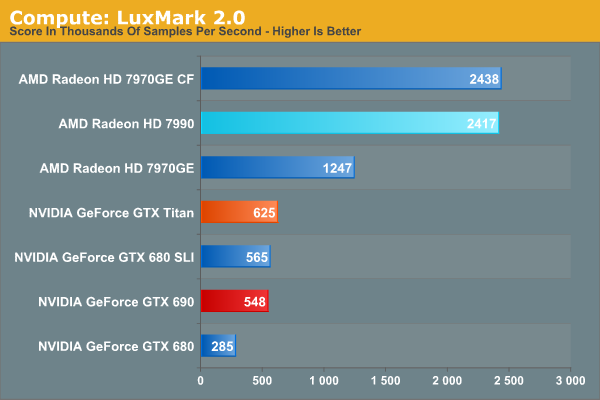
The 7990 isn’t billed as a compute product, but that doesn’t mean it’s at all weak at compute. On the contrary, as LuxMark doesn’t hit the ROPs hard the 7990 has no trouble staying under its 375W target, allowing it to sustain 1000MHz indefinitely. As a result the 7990 takes AMD’s compute advantage and runs with it. The 7990 is a bit more 2x the cost of a 680, but it’s 8.5x faster. Even against GTX Titan the difference is just short of 4x; NVIDIA simply doesn’t do well in our OpenCL tests.
Our 3rd benchmark set comes from CLBenchmark 1.1. CLBenchmark contains a number of subtests; we’re focusing on the most practical of them, the computer vision test and the fluid simulation test. The former being a useful proxy for computer imaging tasks where systems are required to parse images and identify features (e.g. humans), while fluid simulations are common in professional graphics work and games alike.


These two CLBenchmark sub-tests aren’t multi-GPU capable, so the performance of the 7990 is essentially dictated by its first GPU. All that means however is that the 7990 is once again at the top of the charts, well ahead of NVIIDA’s other cards and beating Titan by 50%-100%. At the same time this is a good reminder that not every compute task scales well across multiple GPUs, which is why single-GPU products still have a strong place in the GPU compute world.
Moving on, our 4th compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, as Folding @ Home is moving exclusively OpenCL this year with FAHCore 17.

Only FAHBench’s explicit mode is multi-GPU capable, and even then the scaling to multiple GPUs isn’t great. Still, it’s enough to help the 7990 take the top spot on this benchmark, even with NVIDIA’s latest drivers slightly closing the gap. What’s particularly interesting here though is that the 7990 is faster than the 7970GE CF, and that’s not a fluke in our results. The 7990 should by all means be at least a bit slower, and more if throttling kicks in. It looks like we’re seeing one of those rare cases where the GPUs are benefitting from the presence of the PLX bridge, as going through the relatively close-by bridge is faster than in a two-card setup where the GPUs would have to communicate through the CPU/Northbridge. However this is the only time we see such an advantage; in most other compute scenarios – let alone gaming – the PLX bridge won’t have any kind of notable impact.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, as described in this previous article, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.
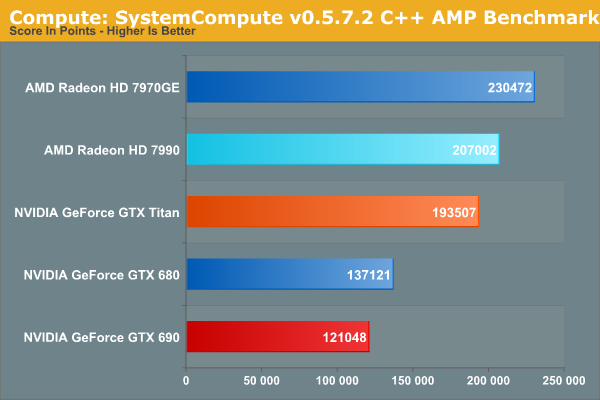
SystemCompute isn’t multi-GPU capable, so once again we’re leaning on the 7990’s first GPU. To that end we find the 7990 in second place, but we also see the 7790 clearly trailing the 7970GE by more than we’ve seen in our other compute benchmarks. SystemCompute does do a lot of I/O, so if FAHBench is the ideal case for showcasing the benefits of the PLX bridge in GPU to GPU I/O, then SystemCompute is good case for showcasing the drawbacks of the PLX bridge, mainly the higher I/O latency. It’s not enough to cripple the 7990 – it’s faster than the GTX Titan even here – but it does cost the 7990 some performance.








91 Comments
View All Comments
Plattypus - Wednesday, April 24, 2013 - link
There's a typo on the Specification Comparison chart, you put 7970 instead of 7990 for the first one.Great review!
deestinct - Thursday, April 25, 2013 - link
There is no typo. It IS 7970 CF. CF stands for CrossFire, which means two 7970s. Therefore the comparison makes sensedeestinct - Thursday, April 25, 2013 - link
Ah sorry ignore my previous comment....i misunderstood what you saidjust4U - Wednesday, April 24, 2013 - link
One thing that bother's me about this and Nvidia's offering. You sort of "hope" (expect.. would be better..) that these types of cards would bring something more to the table besides just a dual stack of their top end card. Higher clocks, better memory.. something.jeffkibuule - Wednesday, April 24, 2013 - link
Power savings compared to 2 cards in SLI/CrossFire. Ability to fit in a smaller chassis. Use of the best binned chips possible. But yeah, it really is for the 1%.mr_tawan - Wednesday, April 24, 2013 - link
Single card also means no need for SLI/Cross Fire mainboard (which save money a bit).Rookierookie - Wednesday, April 24, 2013 - link
I don't know if you are spending $999 on your graphics card that saving money is really an issue. You are not likely to be using a low-end motherboard, and many of the high end motherboards support SLI/Crossfire anyway.just4U - Wednesday, April 24, 2013 - link
The power draw appears to be (in my opinion) partially due to the lower speeds. The cards are for a select crowd but I don't see the draw. There should bring something new to the table which would help to entice buyers.Ktracho - Wednesday, April 24, 2013 - link
There is a fair amount of variability in power consumption from one chip to another. Always choosing two chips that are on the low power side makes a significant difference compared to two chips chosen at random, because in the latter case, the design has to account for the worst case - two chips that are on the high power side.stren - Wednesday, April 24, 2013 - link
5 real monitor outputs and SFF is what it's about for those with unlimited cash, otherwise you'd be better off with mulitple lightnings or matrix cards. Until they support 2D lightboost then I'll be sticking with Nvidia.