Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTHaswell's Wide Execution Engine
Conroe introduced the six execution ports that we've seen used all the way up to Ivy Bridge. Sandy Bridge saw significant changes to the execution engine to enable 256-bit AVX operations but without increasing the back end width. Haswell does a lot here.
Just as before, I put together a few diagrams that highlight the major differences throughout the past three generations for the execution engine.
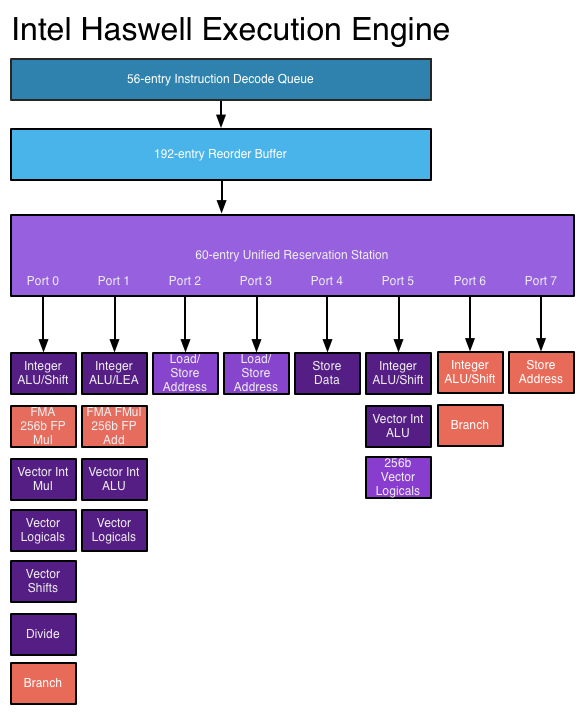
The reorder buffer is one giant tracking structure for all of the micro-ops that are in various stages of execution. The size of this buffer is directly impacted by the accuracy of the branch predictor as that will determine how many instructions can be kept in flight at a given time.
The reservation station holds micro-ops as they wait for the data they need to begin execution. Both of these structures grow by low double-digit percentages in Haswell.
Simply being able to pick from more instructions to execute in parallel is one thing, we haven't seen an increase in the number of parallel execution ports since Conroe. Haswell changes that.
From Conroe to Ivy Bridge, Intel's Core micro-architecture has supported the execution of up to six micro-ops in parallel. While there are more than six execution units in the system, there are only six ports to stacks of execution units. Three ports are used for memory operations (loads/stores) while three are on math duty. Over the years Intel has added additional types and widths of execution units (e.g. Sandy Bridge added 256-bit AVX operations) but it hasn't strayed from the 6 port architecture.
Haswell finally adds two more execution ports, one for integer math and branches (port 6) and one for store address calculation (port 7). Including both additional compute and memory hardware is a balanced decision on Intel's part.
The extra ALU and port does one of two things: either improve performance for integer heavy code, or allow integer work to continue while FP math occupies ports 0 and 1. Remember that Haswell, like its predecessors, is an SMT design meaning each core will see instructions from up to two threads at the same time. Although a single app is unlikely to mix heavy vector FP and integer code, it's quite possible that two applications running at the same time may produce such varied instructions. Having more integer ALUs is never a bad thing.
Also using port 6 is another unit that can handle x86 branch instructions. Branch heavy code can now enjoy two independent branch units, or if port 0 is occupied with other math the machine can still execute branches on port 6. Haswell moved the original Core branch unit from port 5 over to port 0, the most capable port in the system, so a branch unit on a lightly populated port makes helps ensure there's no performance regression as a result of the change.
Sandy Bridge made ports 2 & 3 equal class citizens, with both capable of being used for load or store address calculation. In the past you could only do loads on port 2 and store addresses on port 3. Sandy Bridge's flexibility did a lot for load heavy code, which is quite common. Haswell's dedicated store address port should help in mixed workloads with lots of loads and stores.
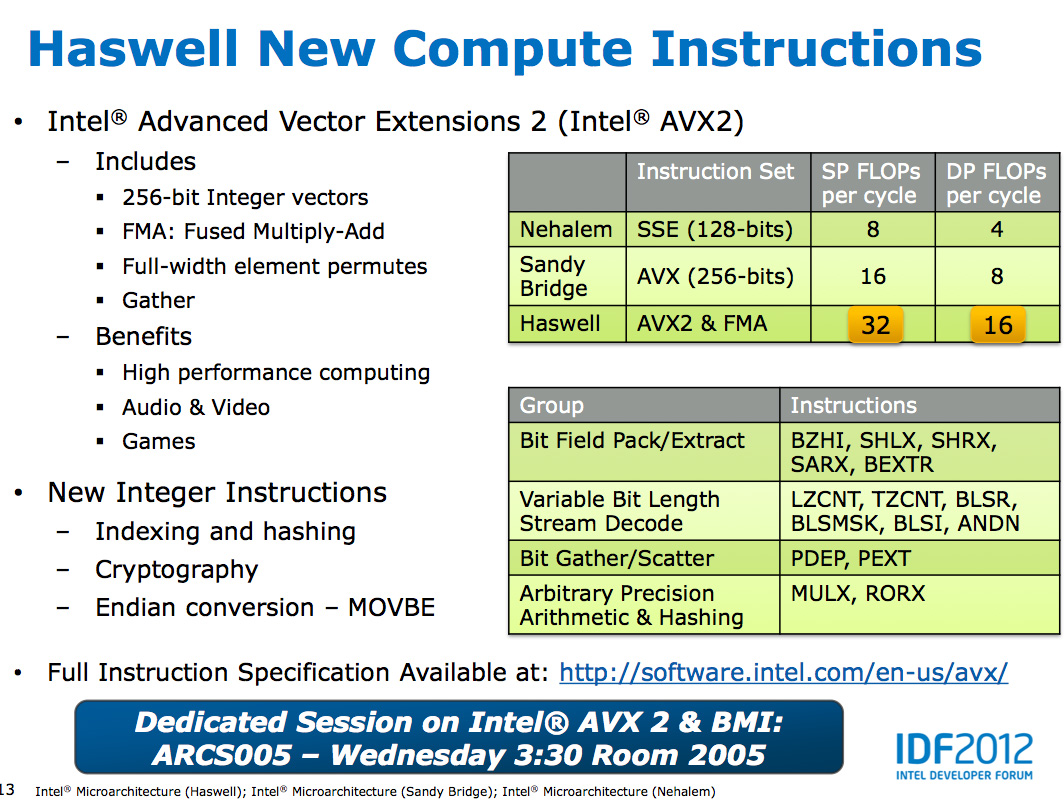
The other major addition to the execution engine is support for Intel's AVX2 instructions, including FMA (Fused Multiply-Add). Ports 0 & 1 now include newly designed 256-bit FMA units. As each FMA operation is effectively two floating point operations, these two units double the peak floating point throughput of Haswell compared to Sandy/Ivy Bridge. A side effect of the FMA units is that you now get two ports worth of FP multiply units, which can be a big boon to legacy FP code.
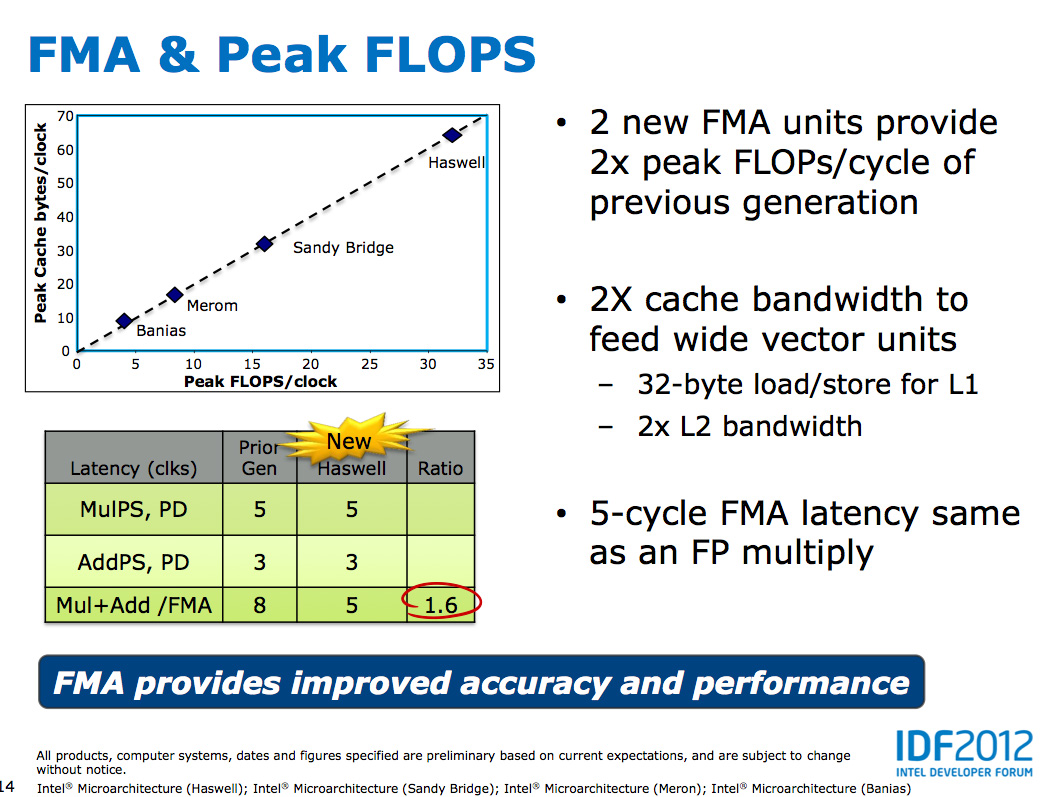
Fused Multiply-Add operations are incredibly handy in all sorts of media processing and 3D work. Rather than having to independently multiply and add values, being able to execute both in tandem via a single execution port increases the effective execution width of the machine. Note that a single FMA operation takes 5 cycles in Haswell, which is the same latency as a FP multiply from Sandy/Ivy Bridge. In the previous generation a floating point multiply+add took 8 cycles, so there's a good latency improvement here as well as the throughput boost from having two FMA units.
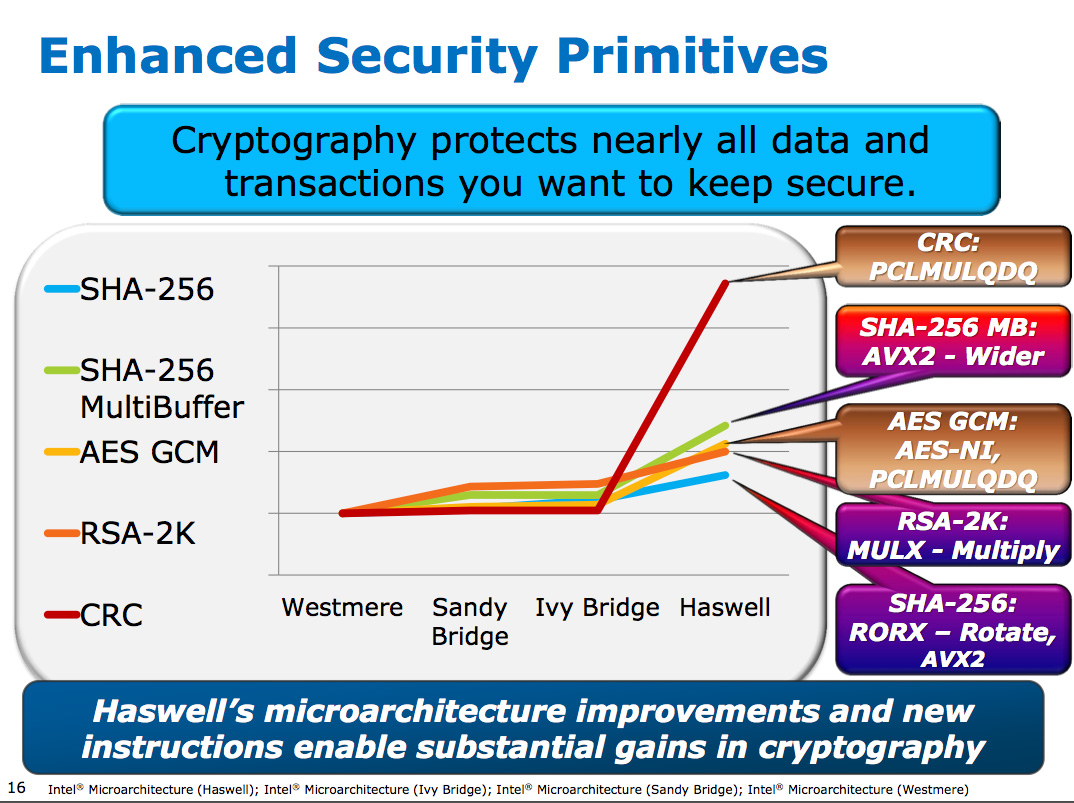
Intel focused a lot on adding more execution horsepower in Haswell without creating a power burden for legacy use cases. All of the new units can be shut off when not in use. Furthermore, Intel went in and ensured that this applied to the older execution units as well: in Haswell if you're not doing work, you're not consuming power.








245 Comments
View All Comments
CaptainDoug - Friday, October 5, 2012 - link
Quite the read. Very informational. Anandtech has some of the best tech writers. True online journalism. Sometimes i miss that while reading tech blogs... You guys are a cut above.. at least one.colonelclaw - Friday, October 5, 2012 - link
Couldn't agree more, this article really brightened up what was otherwise a pretty miserable afternoon here in London.When am I going to be able to walk into a shop and buy something with Haswell inside it? Next March maybe?
Kepe - Friday, October 5, 2012 - link
As stated in the article, Haswell is coming in the summer of 2013.linuxlowdown - Saturday, October 6, 2012 - link
Tag team Intel fanboy puke.Azethoth - Sunday, October 7, 2012 - link
How do I downvote stupid crap like this "Tag team Intel fanboy puke." comment so that collectively we can see high quality comments without having to wade through the interturds as well? It really takes away from the best article I have read in a long time. Not because it is about Intel, but because it is about the state of the art.medi01 - Tuesday, October 9, 2012 - link
Well, I'd also ask how do I downvote stupid butt kissing like OP, while we are at rating....Kisper - Saturday, October 20, 2012 - link
Many people enjoy well written and informative articles. Are you telling me that if you wrote, you would not enjoy positive feedback from your readers?CaptainDoug - Tuesday, October 23, 2012 - link
Exactly.actionjksn - Sunday, October 7, 2012 - link
Why are you even on this article dumb fuck? I'm sure there is something that is of interest to you on the internet somewhere.medi01 - Tuesday, October 9, 2012 - link
Not sure about him, but I've looked into this article to figure power targets for haswell (especially interesting to compare to ARM crowd), NOT to read orgasmic comments about eternal wizdom of Intel's engineering...