AMD's Radeon HD 6990: The New Single Card King
by Ryan Smith on March 8, 2011 12:01 AM EST- Posted in
- AMD
- Radeon HD 6990
- GPUs
BattleForge
Up next is BattleForge, Electronic Arts’ free to play online RTS. As far as RTSes go this game can be quite demanding, and this is without the game’s DX11 features.

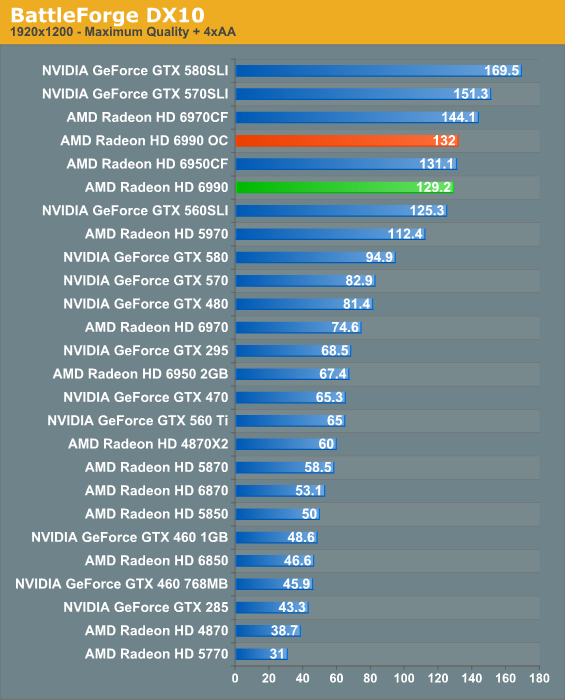
With BattleForge we see the 6990 fall in to a similar hole as the rest of the 6900 series when it comes to performance relative to NVIDIA’s 500 series: sometimes they do well, and sometimes NVIDIA has an advantage in the game; this is the latter.
In the meantime this is one of our better examples of why memory bandwidth matters, as not only does the 6990OC gain little on the 6990, but even the 6990OC trails the 6970CF by 8%. Clearly performance relative to the 6970CF is going to depend on how limited a game is by memory bandwidth. In the worst case, we’re looking at 6950CF-like memory bandwidth, and as a result 6950CF-like performance. The 6990’s advantage over the 5970 also shrinks here as a result, dropping to 17%.








130 Comments
View All Comments
smookyolo - Tuesday, March 8, 2011 - link
My 470 still beats this at compute tasks. Hehehe.And damn, this card is noisy.
RussianSensation - Tuesday, March 8, 2011 - link
Not even close, unless you are talking about outdated distributed computing projects like Folding@Home code. Try any of the modern DC projects like Collatz Conjecture, MilkyWay@home, etc. and a single HD4850 will smoke a GTX580. This is because Fermi cards are limited to 1/8th of their double-precision performance.In other words, an HD6990 which has 5,100 Gflops of single-precision performance will have 1,275 Glops double precision performance (since AMD allows for 1/4th of its SP). In comparison, the GTX470 has 1,089 Gflops of SP performance which only translates into 136 Gflops in DP. Therefore, a single HD6990 is 9.4x faster in modern computational GPGPU tasks.
palladium - Tuesday, March 8, 2011 - link
Those are just theoretical performance numbers. Not all programs *even newer ones* can effectively extract ILP from AMD's VLIW4 architecture. Those that can will no doubt with faster; others that can't would be slower. As far as I'm aware lots of programs still prefer nV's scalar arch but that might change with time.MrSpadge - Tuesday, March 8, 2011 - link
Well.. if you can oly use 1 of 4 VLIW units in DP then you don't need any ILP. Just keep the threads in flight and it's almost like nVidias scalar architecture, just with everything else being different ;)MrS
IanCutress - Tuesday, March 8, 2011 - link
It all depends on the driver and compiler implementation, and the guy/gal coding it. If you code the same but the compilers are generations apart, then the compiler with the higher generation wins out. If you've had more experience with CUDA based OpenCL, then your NVIDIA OpenCL implementation will outperform your ATI Stream implementation. Pick your card for it's purpose. My homebrew stuff works great on NVIDIA, but I only code for NVIDIA - same thing for big league compute directions.stx53550 - Tuesday, March 15, 2011 - link
off yourself idiotm.amitava - Tuesday, March 8, 2011 - link
".....Cayman’s better power management, leading to a TDP of 37W"- is it honestly THAT good? :P
m.amitava - Tuesday, March 8, 2011 - link
oops...re-read...that was idle TDP !!MamiyaOtaru - Tuesday, March 8, 2011 - link
my old 7900gt used 48 at loadD:
Don't like the direction this is going. In GPUs it's hard to see any performance advances that don't come with equivalent increases in power usage, unlike what Core 2 was compared to Pentium4.
Shadowmaster625 - Tuesday, March 8, 2011 - link
Are you kidding? I have a 7900GTX I dont even use, because it fried my only spare large power supply. A 5670 is twice as fast and consumes next to nothing.