NVIDIA's 1.4 Billion Transistor GPU: GT200 Arrives as the GeForce GTX 280 & 260
by Anand Lal Shimpi & Derek Wilson on June 16, 2008 9:00 AM EST- Posted in
- GPUs
Tweaks and Enahancements in GT200
NVIDIA provided us with a list, other than the obvious addition of units and major enhancements in features and technology, of adjustments made from G80 to GT200. These less obvious changes are part of what makes this second generation Tesla architecture a well evolved G80. First up, here's a quick look at percent increases from G80 to GT200.
| NVIDIA Architecture Comparison | 8800 GTX | GTX 280 | % Increase |
| Cores | 128 | 240 | 87.5% |
| Texture | 64t/clk | 80t/clk | 25% |
| ROP Blend | 12p / clk | 32p / clk | 167% |
| Max Precision | fp32 | fp64 | |
| GFLOPs | 518 | 933 | 80% |
| FB Bandwidth | 86 GB/s | 142 GB/s | 65% |
| Texture Fill Rate | 37 GT/s | 48 GT/s | 29.7% |
| ROP Blend Rate | 7 GBL/s | 19 GBLs | 171% |
| PCI Express Bandwidth | 6.4 GB/s | 12.8GB/s | 100% |
| Video Decode | VP1 | VP2 |
Communication between the driver and the front-end hardware has been enhanced through changes to the communications protocol. These changes were designed to help facilitate more efficient data movement between the driver and the hardware. On G80/G92, the front-end could end up in contention with the "data assembler" (input assembler) when performing indexed primitive fetches and forced the hardware to run at less than full speed. This has been fixed with GT200 through some optimizations to the memory crossbar between the assembler and the frame buffer.
The post-transform cache size has been increased. This cache is used to hold transformed vertex and geometry data that is ready for the viewport clip/cull stage, and increasing the size of it has resulted in faster communication and fewer pipeline stalls. Apparently setup rates are similar to G80 at up to one primative per clock, but feeding the setup engine is more efficient with a larger cache.
Z-Cull performance has been improved, while Early-Z rejection rates have increased due to the addition of more ROPs. Per ROP, GT200 can eliminate 32 pixles (or up to 256 samples with 8xAA) per clock.
The most vague improvement we have on the list is this one: "significant micro-architectural improvements in register allocation, instruction scheduling, and instruction issue." These are apparently the improvements that have enabled better "dual-issue" on GT200, but that's still rather vague as to what is actually different. It is mentioned that scheduling between the texture units and SMs within a TPC has also been improved. Again, more detail would be appreciated, but it is at least worth noting that some work went into that area.
Register Files? Double Em!
Each of those itty-bitty SPs is a single-core microprocessor, and as such it has its own register file. As you may remember from our CPU architecture articles, registers are storage areas used to directly feed execution units in a CPU core. A processor's register file is its collection of registers and although we don't know the exact number that were in G80's SPs, we do know that the number has been doubled for GT200.
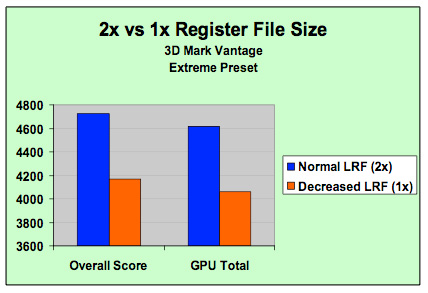
NVIDIA's own data shows a greater than 10% increase in performance due to the larger register file size (source: NVIDIA)
If NVIDIA is betting that games are going to continue to get more compute intensive, then register file usage should increase as well. More computations means more registers in use, which in turn means that there's a greater likelihood of running out of registers. If a processor runs out of registers, it needs to start swapping data out to much slower memory and performance suffers tremendously.
If you haven't gotten the impression that NVIDIA's GT200 is a compute workhorse, doubling the size of the register file per SP (multiply that by 240 SPs in the chip) should help drive the idea home.
Double the Precision, 1/8th the Performance
Another major feature of the GT200 GPU and cards based on it is support for hardware double precision floating point operations. Double precision FP operations are 64-bits wide vs. 32-bit for single precision FP operations.
Now the 240 SPs in GT200 are single-precision only, they simply can't accept 64-bit operations at all. In order to add hardware level double precision NVIDIA actually includes one double precision unit per shading multiprocessor, for a total of 30 double precision units across the entire chip.
The ratio of double precision to single precision hardware in GT200 is ridiculously low, to the point that it's mostly useless for graphics rasterization. It is however, useful for scientific computing and other GPGPU applications.
It's unlikely that 3D games will make use of double precision FP extensively, especially given that 8-bit integer and 16-bit floating point are still used in many shader programs today. If anything, we'll see the use of DP FP operations in geometry and vertex operations first, before we ever need that sort of precision for color - much like how the transition to single precision FP started first in vertex shaders before eventually gaining support throughout the 3D pipeline.
Geometry Wars
ATI's R600 is alright at geometry shading. So is RV670. G80 didn't really keep up in this area. Of course, games haven't really made extensive use of geometry shaders because neither AMD nor NVIDIA offered compelling performance and other techniques made more efficient use of the hardware. This has worked out well for NVIDIA so far, but they couldn't ignore the issue forever.
GT200 has enhanced geometry shading support over G80 and is now on par with what we wish we had seen last year. We can't fault NVIDIA too much as with such divergent new features they had to try and predict the usage models that developers might be interested in years in advance. Now that we are here and can see what developers want to do with geometry shading, it makes sense to enhance the hardware in ways that support these efforts.
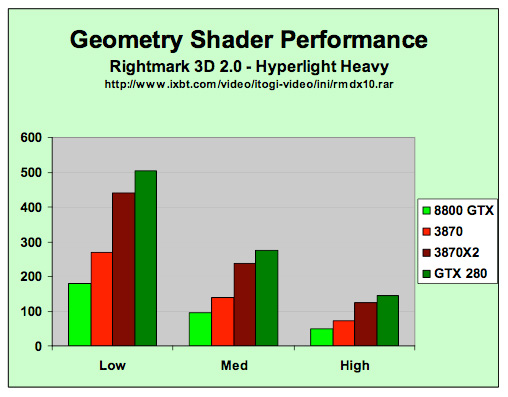
GT200 has significantly improved geometry shader performance compared to G80 (source: NVIDIA)
Generation of vertex data is a particularly weak part of NVIDIA's G80, so GT200 is capable of streaming out 6x the data of G80. Of course there are the scheduling enhancements that affect everything, but it is unclear as to whether NVIDIA did anything beyond increasing the size of their internal output buffers by 6x in order to enhance their geometry shading capability. Certainly this was lacking previously, but hopefully this will make heavy use of the geometry shader something developers are both interested in and can take advantage of.








108 Comments
View All Comments
elchanan - Monday, June 30, 2008 - link
VERY eye-opening discussion on TMT. Thank you for it.I've been trying to understand how GPUs can be competitive for scientific applications which require lots of inter-process communication, and "local" memory, and this appears to be an elegant solution for both.
I can identify the weak points of it being hard to program for, as well as requiring many parallel threads to make it practical.
But are there other weak points?
Is there some memory-usage profile, or inter-process data bandwidth, where the trick doesn't work?
Perhaps some other algorithm characteristic which GPUs can't address well?
Think - Friday, June 20, 2008 - link
This card is a junk bond when taking into consideration cost/perfomance/power consumption.Reminds me of a 1976 Cadillac with a 7.7litre v8 with only 210 horsepower/3600 rpm.
It's a PIG.
Margalus - Tuesday, June 24, 2008 - link
this shows how many people don't run a dual monitor setup. I would snatch up one of these 260/280's over the gx2's anyday, gladly!!The performance may not be quite as good as an sli setup, but it will be much better than a single card which is what a lot of us are stuck with since you CANNOT run a dual monitor setup with sli!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
iamgud - Wednesday, June 18, 2008 - link
"I can has vertex data"LOL
These look fine, but need to be moved to 55nm. By the time I save up for one they will .
calyth - Tuesday, June 17, 2008 - link
Well what the heck are they doing with 1.4B transistors, which is becoming the largest die that TMSC has been producing so far?The larger the core, the more likely that an blemish would take out the core. As far as I know, didn't Phenom (4 cores on die) suffered low-yield problems?
gochichi - Tuesday, June 17, 2008 - link
You know, when you consider the price and you look at the benchmarks, you start looking for features and NVIDIA just doesn't have the features going on at all.COD4 -- Ran perfect at 1920x1200 with last gen stuff (the HD3870 and 8800GT(S))so now the benchmarks have to be for outrageous resolutions that a handful of monitors can handle (and those customers already bought SLI or XFIRE, or GTX2 etc.)
Crysis is a pig of a game, but it's not that great (it is a good technical preview though, I admit), and I don't think even these new cards really satisfy this system hog... so maybe this is a win, but I doubt too many people care... if you had an 8800GT or whatever, you're already played this game "well enough" on medium settings and are plenty tired of it. Though we'll surely fire it up in the future once our video cards "happen to be able to run it on high" very few people are going to go out of their way $500+ for this silly title.
In any case, then you look at ATI, and they have the HDMI audio, the DX 10.1 support and all they have to do at this point is A) Get a good price out the door, B) Make a good profit (make them cheap, which these NVIDIA are expensive to make, no doubt) and C) handily beat the 8800GTS and many of us are going to be sold.
These cards are what I would call a next gen preview. Some overheated prototypes of things to come. I doubt AMD will be as fast, and in fact I hope they aren't just as long as they keep the power consumption in check, the price, and the value (HDMI, DX10.1, etc).
Today's release reminded me that NVIDIA is the underdog, they are the company that released the FX series (desperate technology, like these are). ATI has been around well before 3DFX made 3d-accelerators. They were down for a bit, and we all said it was over for ATI but this desperate release from NVIDIA makes me think that ATI is going to be quite tought to beat.
Brazofuerte - Tuesday, June 17, 2008 - link
Can I go somewhere to find the exact settings used for these benchmarks? I appreciate the tech side of the write up but when it comes to determining whether I want one of these for my gaming machine (I ordered mine at midnight), I find HardOCP's numbers much more useful.woofermazing - Tuesday, June 17, 2008 - link
AMD/ATI isn't going to abandon the high end like your article implies. Their plan is to make a really good mid range chip, and ductape to cores together ala the X2's. Nvidia goes from the high-end down, ATI from the mid-end up. From the look of it, ATI might have the right idea, atleast this time around. I seriously doubt we'll see a two core version of this monster anytime soon.DerekWilson - Tuesday, June 17, 2008 - link
they are abandoning the high end single GPU ...we did state that they are planning on competing in the high end space with multiGPU cards, but that there are drawbacks to that.
we'll certainly have another article coming out sometime soon that looks a little more closely at AMD's strategy.
KeypoX - Tuesday, June 17, 2008 - link
i dont like it, not impressed either :(. Hopefully my 8800gt last for a while, far past this crap atleast