Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2
SPEC - Multi-Core Performance Scaling
I did mention the L3 cache of the Graviton2 was shared amongst all its cores, and we also discovered how only 8-16 cores were able to saturate the memory controllers of the system. To put those aspects into better context, I ran the SPEC suites at rate instance numbers, ranging from 16, 32, 48 and the full 64 cores, and normalised the results relative to the per-thread performance showcased in the rate-1 single-threaded runs.
What this attempts to showcase is the performance scaling of the full SoC across varying loads of the different workload types. Scaling linearly across cores might be easy for some workloads, but for anything that even remotely has some kind of memory pressure should see greater slowdowns given that all the threads are competing for the shared L3 and DRAM resources.
The testing here for all figures were done on a 16xlarge instance with 64 vCPUs to avoid the possibility of noisy neighbours, and give better reliability in the lower core count results.
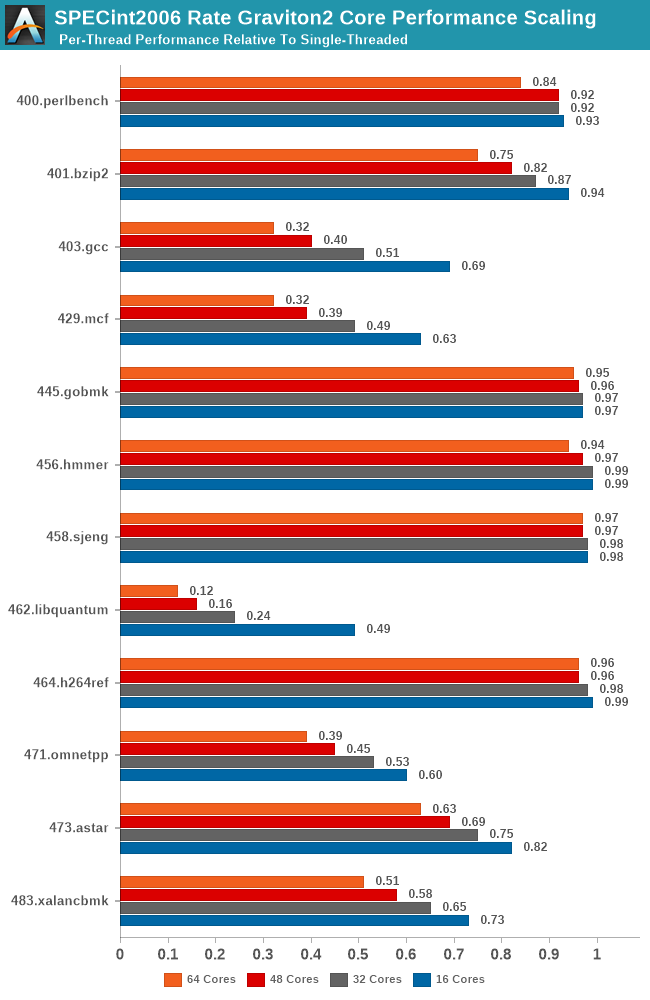
As expected, we’re seeing a quite wide range of results here, and it’s also a good showcase of which SPEC workloads are memory and cache intensive and which are not. Workloads such as 445.gobmk and 456.hmmer aren’t surprising in their near linear scaling as they don’t have too much cache pressure, and the Graviton2’s 1MB L2 per core is also more than enough for 464.h264ref.
On the other hand, well known memory intensive workloads such as 462.libquantum absolutely crater in terms of per-thread performance. This memory bandwidth demanding workload is fully saturating the bandwidth of the system early on with very few cores, meaning that performance barely increases the more threads and cores we throw at it. Such a scaling more or less is mimicked in other workloads of varying cache and memory pressure.
The most worrying result though is 403.gcc. Code compilation should have been one of the bigger use-cases for a platform such as Graviton2, but the platform is having issues scaling well with core count, undoubtedly a result of higher cache pressure of the system. In a single-thread scenario in the system a core would have access to 33MB L2+L3, but when having 64 cores doing the same thing at once you’d end up with only 1.5MB per core, assuming things are evenly competitively shared.
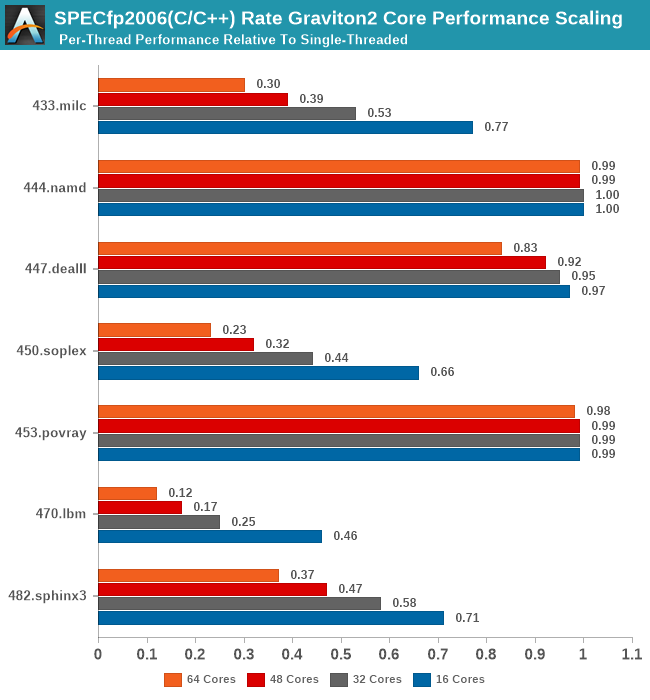
In SPECfp2006, again, we see the well-known memory intensive workloads such as 433.milc and 470.lbm crater in their per-thread performance the more threads you throw at the system, while other workloads are able to scale near linearly with cores.
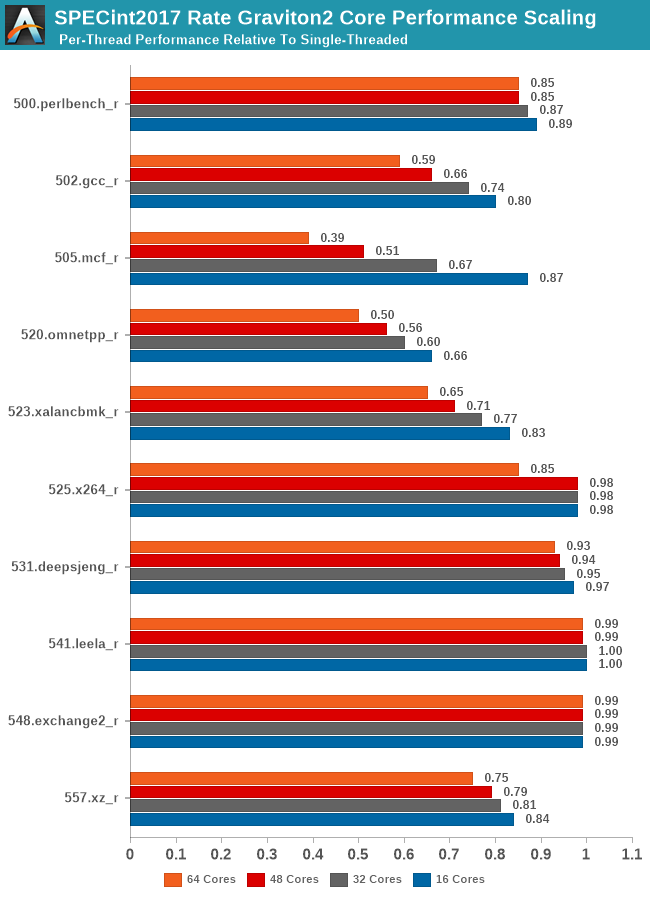
In SPECint2017, we see the workload changes I referred to previously on the single-threaded page. The new gcc and mcf tests are actually scaling better than their 2006 counterparts due to actually reduced memory pressure on the new tests. It does beg the question of which variant of the test is actually more representative of most workloads of these types.
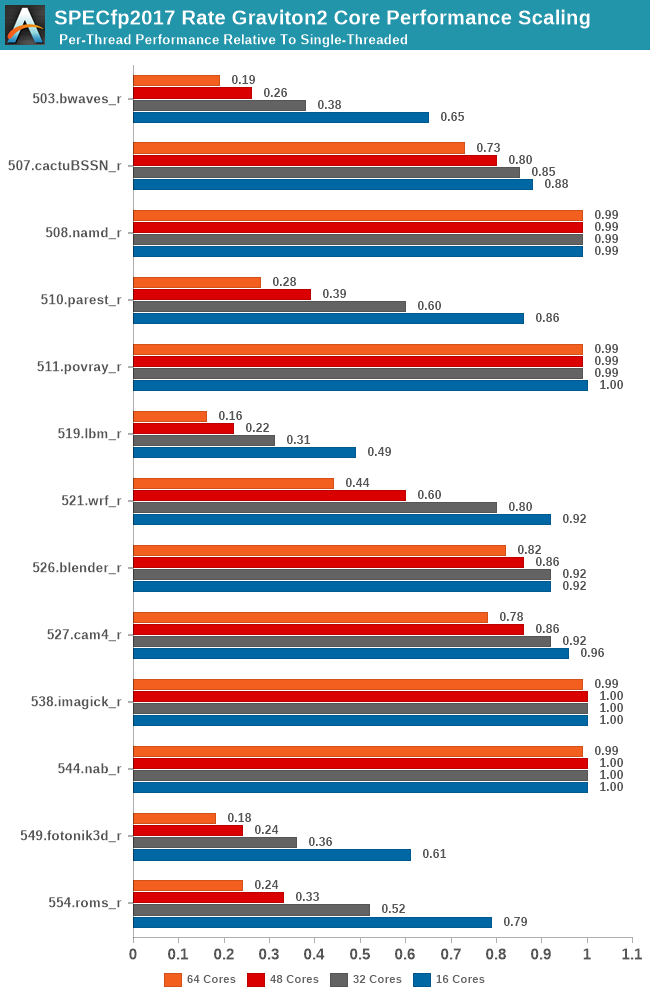
Compared to the int2017 suite, the fp2017 suite scales significantly worse for a larger number of workloads. When Ampere last week talked about its Altra processor, and that it was “designed for integer workloads”, that didn't make too much sense other than in the context that the N1 cores are missing wider SIMD execution units. What does make sense though is that the floating-point suite of SPEC is a lot more memory intensive and SoCs like the Graviton2 don’t fare as well at higher loaded core-counts.
It will be interesting to see where the Arm chip designers are heading to in regards to this general memory bottleneck. If your workload isn’t too memory intensive then scaling up to such huge core counts is an easy way to scale performance as well. On the opposite end of the spectrum on memory hungry workloads, these chips will just be memory starved. Arm had envisioned 64 core Neoverse N1 systems to have 64-128MB of L3 cache, and the CMN-600 scales up to 256MB total in a 128-core system, which seem like more sensible and balanced targets.








96 Comments
View All Comments
SarahKerrigan - Tuesday, March 10, 2020 - link
That single-thread performance is extremely impressive. The multithreaded scaling is ugly, though. Back when N1 was announced, ARM seemed to think 1MB/core was a good spot for Neoverse LLC - I wonder why both Graviton and Altra are going for considerably less.shing3232 - Tuesday, March 10, 2020 - link
it's gonna costly(die and power wise) to build a interconnect for 64C with good performance. by the time, it would lost its power/perf edge I suppose.Tabalan - Tuesday, March 10, 2020 - link
Scaling might not be optimal, but performance loses are to expected if you greatly reduce available cache. In the end, MT performance is still far ahead of competition.ballsystemlord - Thursday, March 12, 2020 - link
You have to remember that the competition is not 64 cores, but 64v cpus. The difference is 60% or more. The Arm Graviton2 is being placed into the best possible light by this comparision.ballsystemlord - Thursday, March 12, 2020 - link
I mean 60% for the cores that are actually 1 thread. As in, the performance boost by turning on SMT is 40% best case scenario.autarchprinceps - Sunday, October 25, 2020 - link
I have to disagree. You seem to forget that the arm chip is cheaper. It’s an additional win if it manages to integrate more cores and yet still achieve a comparable single threaded performance. It’s not unfair to compare two products with one seeming to have a stat advantage from the start, if it’s still cheaper or costs the same. Why should a customer care?zamroni - Thursday, March 12, 2020 - link
L caches uses sram which needs 6 transistors per bit.So, every 1MB needs all least 48 millions transistors without counting transistors for the controller
dianajmclean6 - Monday, March 23, 2020 - link
Six months ago I lost my job and after that I was fortunate enough to stumble upon a great website which literally saved me• I started working for them online and in a short time after I've started averaging 15k a month••• icash68.coMRallJ - Tuesday, March 10, 2020 - link
Comparisons made are to the whole core performance of Graviton to just thread performance of Xeon/EPYC. It's very problematic.Also TDP rating for the graviton is off by 50% based on what was reported at re:Invent.
Andrei Frumusanu - Tuesday, March 10, 2020 - link
I go over the core/SMT topic in the article, it's only a problem from a hardware comparison aspect, but it's very much the correct comparison from a cloud product offering comparison. The value proposition also does not change depending on core count, the instances are priced at similar tiers.