NVIDIA Gives Jetson AGX Xavier a Trim, Announces Nano-Sized Jetson Xavier NX
by Ryan Smith on November 6, 2019 1:00 PM EST- Posted in
- NVIDIA
- Xavier
- Jetson
- Edge Computing

Since it was launched earlier this decade, NVIDIA’s Jetson lineup of embedded system kits remains one of the odder success stories for the company. While NVIDIA’s overall Tegra SoC plans have gone in a very different direction than first planned, they’ve seen a lot of success with their system-level Jetson kits, as customers snatch them up both as dev kits and for use in commercial systems. Now in their third generation of Jetson systems, this afternoon NVIDIA is outlining their plans to diversify the family a bit more, announcing a physically smaller and cheaper version of their flagship Jetson Xavier kit, in the form of the Jetson Xavier NX.
Based on the same Xavier SoC that’s used in the titular Jetson AGX Xavier, the Jetson Xavier NX is designed to fill what NVIDIA sees as a need for both a cheaper Xavier option, as well as one smaller than the current 100mm x 87mm board. In fact the new Nano-sized board is quite literally that: the size of the existing Jetson (TX1) Nano, which was introduced earlier this year. Keeping the same form factor and pin compatibility, the Jetson Xavier NX sports the same 45mm x 70mm dimensions, making it a bit smaller than a credit card.

Compared to the full-sized Jetson AGX Xavier, NVIDIA is aiming the Jetson Xavier NX at customers who need to do edge inference in space-constrained use cases where the big Xavier won’t do. Since it’s based on the same Xavier SoC, the Jetson Xavier NX uses the same Volta GPU, and critically, the same NVDLA accelerator cores as the original. As a result, for inference tasks the Jetson Xavier NX should be significantly faster than the Jetson Nano and various Jetson TX2 products – curently NVIDIA's most widely used embedded Jetson – none of which have hardware comparable to NVIDIA’s dedicated deep learning accelerator cores.
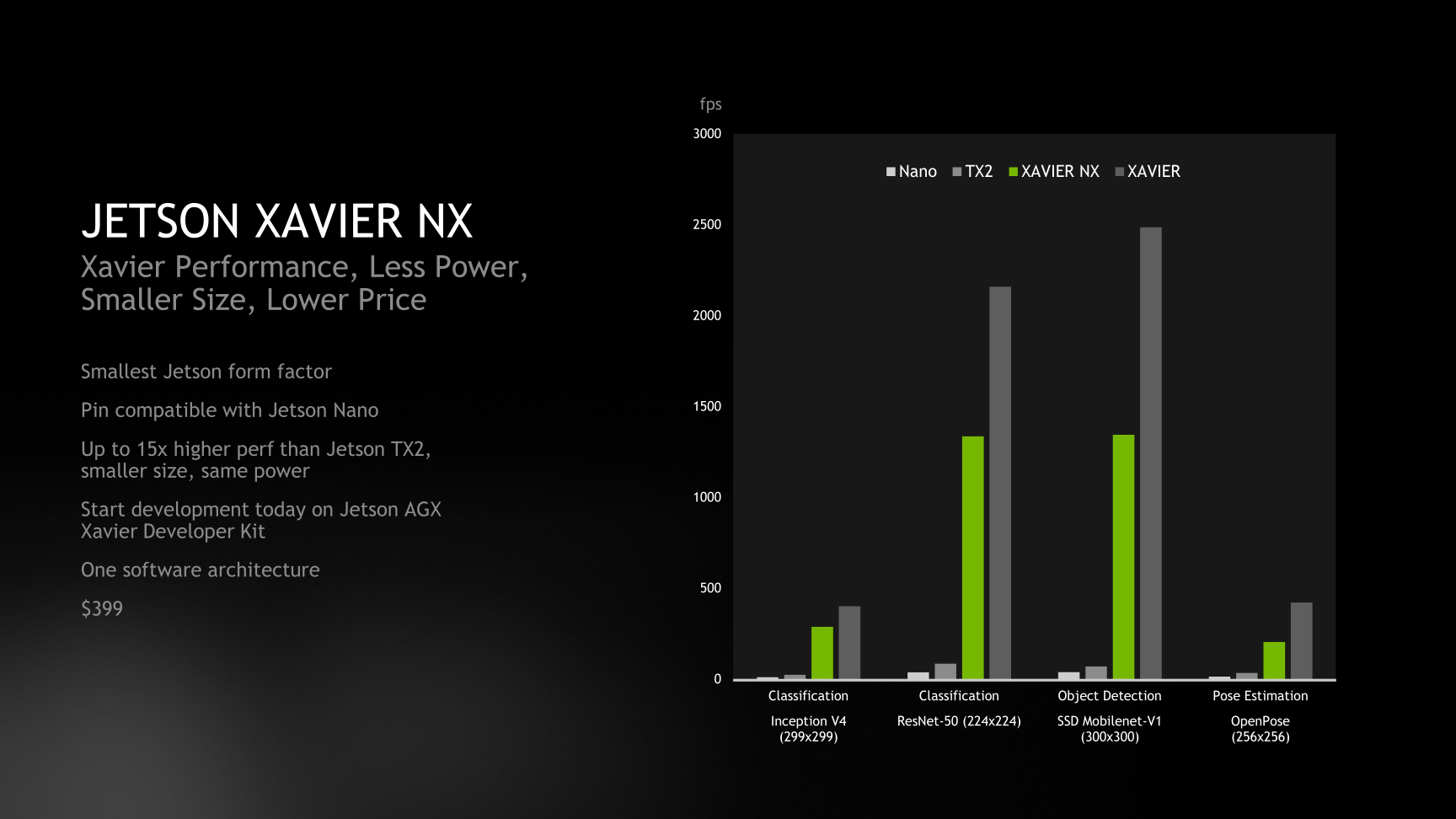
Not that Jetson Xavier NX is a wholesale replacement for Jetson AGX Xavier, however. The smaller Xavier board is taking a shave both in performance and in I/O for a mix of product segmentation, power consumption, and pin compatibility reasons. Notably, the Xavier SoC uses in the NX loses out on 2 CPU cores, 2 GPU SMs, and perhaps most important to heavy inference users, half of the chip’s memory bandwidth. As a result the Jetson Xavier NX should still be significantly ahead of Jetson TX1/TX2, but it will definitely trail the full-fledged Jetson AGX Xavier.
| NVIDIA Jetson Family Specifications | ||||||
| Xavier NX (15W) |
Xavier NX (10W) |
AGX Xavier | Jetson Nano | |||
| CPU | 4x/6x Carmel @ 1.4GHz or 2x Carmel @ 1.9GHz |
4x/ Carmel @ 1.2GHz or 2x Carmel @ 1.5GHz |
8x Carmel @ 2.26GHz |
4x Cortex-A57 @ 1.43GHz |
||
| GPU | Volta, 384 Cores @ 1100MHz |
Volta, 384 Cores @ 800MHz | Volta, 512 Cores @ 1377MHz |
Maxwell, 128 Cores @ 920MHz |
||
| Accelerators | 2x NVDLA | 2x NVDLA | N/A | |||
| Memory | 8GB LPDDR4X, 128-bit bus (51.2 GB/sec) |
16GB LPDDR4X, 256-bit bus (137 GB/sec) |
4GB LPDDR4, 64-bit bus (25.6 GB/sec) |
|||
| Storage | 16GB eMMC | 32GB eMMC | 16GB eMMC | |||
| AI Perf. | 21 TOPS | 14 TOPS | 32 TOPS | N/A | ||
| Dimensions | 45mm x 70mm | 100mm x 87mm | 45mm x 70mm | |||
| TDP | 15W | 10W | 30W | 10W | ||
| Price | $399 | $999 | $129 | |||
All told, for inference applications NVIDIA is touting 21 TOPS of performance at the card’s full power profile of 15 Watts. Alternatively, at 10 Watts – which happens to be the max power state for Jetson Nano – this drops down to 14 TOPS as clockspeeds are reduced and two more CPU cores are shut off.
Otherwise, the Jetson Xavier NX is designed to slot right in with the rest of the Jetson family, as well as NVIDIA’s hardware and software ecosystem. The embedded system board is being positioned purely for use in high-volume production systems, and accordingly, NVIDIA won’t be putting together a developer kit version of the NX. Since the current Jetson AGX Xavier will be sticking around, it will fill that role, and NVIDIA is offering software patches for developers who need to specifically test against Jetson Xavier NX performance levels.
The Jetson Xavier NX will be shipping from NVIDIA in March of 2020, with NVIDIA pricing the board at $399.















10 Comments
View All Comments
abufrejoval - Wednesday, November 6, 2019 - link
Values in the TDP row seem swapped.Yeah, that's a pretty cool upgrade for the Nano dev-board, even if it's still a little too pricey.
I prefer the µSD storage over 8GB eMMC, too and you can never have enough RAM, but...
It felt like they were selling the Nano almost at a loss, but with the Xaviers they seem to try making real money, when it's really about seeding the edge.
michael2k - Wednesday, November 6, 2019 - link
Well, I think the original Nano is seeding the edge. The Xavier is priced to stay solvent, and is supposed to be used as a drop in replacement once you've done your initial work with the NanoDemiurge - Wednesday, November 6, 2019 - link
Keep in mind, the listed price appears to be the cost for the SoM only as pictured.abufrejoval - Thursday, November 7, 2019 - link
The more I think about it, the more I see your point. Not sure I like it, though ;-)I guess it just strikes me as odd to see Nvidia as a volume hardware manufacturer: I'd expect these modules to be made by various OEMs like in the GPU world and then plenty of competition and differentiation as well as prices that are much less "cosmetic" (and overdone).
I guess it's time to check if the specs are open or even available for licensing and if OEM is intended or not.
Of course, volume prices could be anywhere.
mode_13h - Saturday, November 9, 2019 - link
Xavier is expensive because it's *huge*.techmar - Thursday, November 7, 2019 - link
The NX TDPs are mixed up in the table I think..ToTTenTranz - Thursday, November 7, 2019 - link
How can Xavier AGX ever reach 11 TFLOPs FP16?512 madd ALUs at 1377MHz and 2x FP16 rate results in 2.8 TFLOPs FP16.
Can the NVDLA be used for regular FP16 calculations?
mode_13h - Saturday, November 9, 2019 - link
Lol, that graph shows just what a turd the original Nano really is. Not that I'm surprised, in the least.mpottinger - Saturday, May 30, 2020 - link
Yeah I bought 2 of them because I was excited at initial launch.I guess for the price they are OK, but they are just sitting collecting dust because they are just too underpowered to do anything serious with, and a pain in the butt with power issues, etc.