The Toshiba/Kioxia BG4 1TB SSD Review: A Look At Your Next Laptop's SSD
by Billy Tallis on October 18, 2019 11:30 AM ESTWhole-Drive Fill
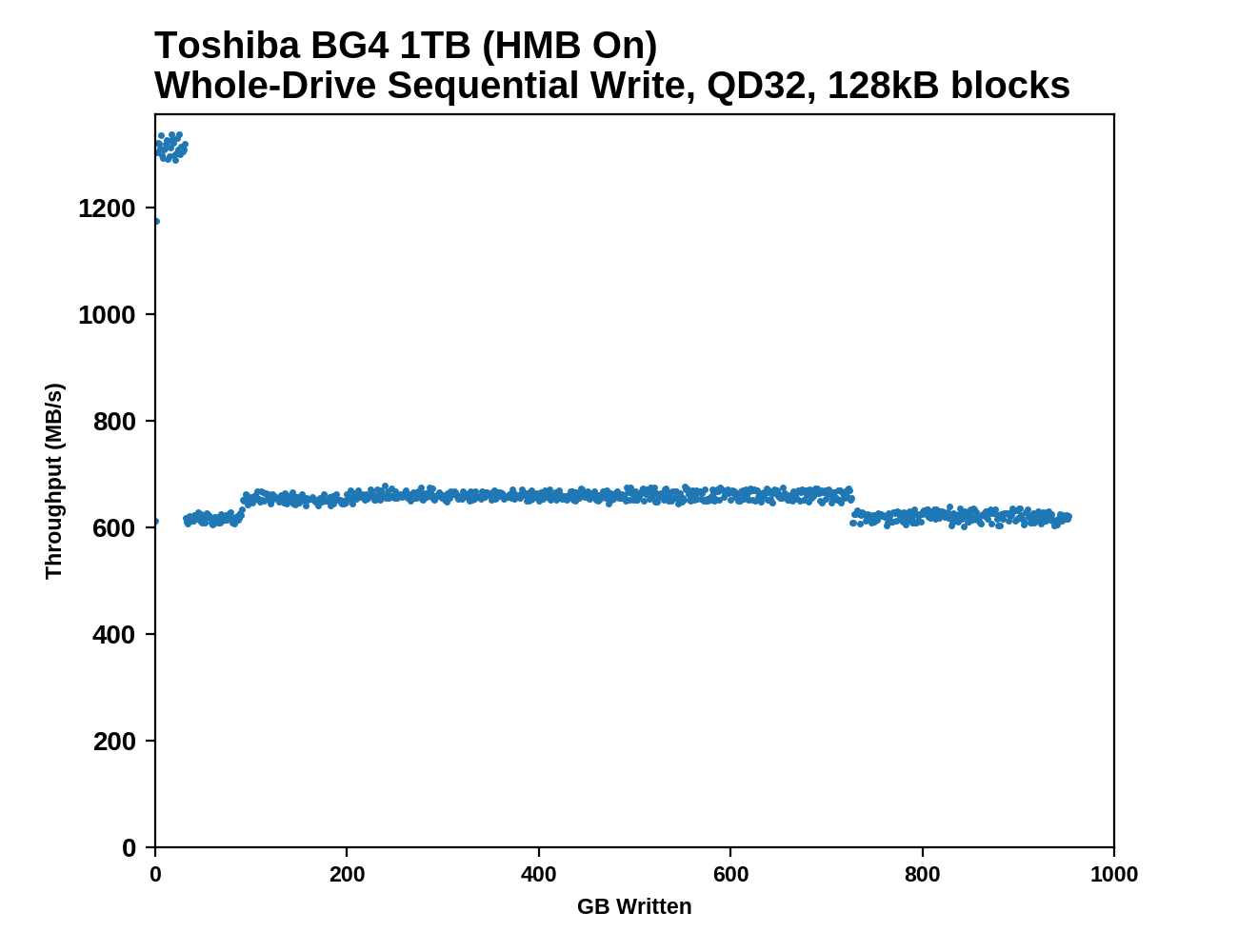
This test starts with a freshly-erased drive and fills it with 128kB sequential writes at queue depth 32, recording the write speed for each 1GB segment. This test is not representative of any ordinary client/consumer usage pattern, but it does allow us to observe transitions in the drive's behavior as it fills up. This can allow us to estimate the size of any SLC write cache, and get a sense for how much performance remains on the rare occasions where real-world usage keeps writing data after filling the cache.
 |
|||||||||
The 1TB Toshiba/Kioxia BG4 appears to have a 32GB SLC write cache that's far slower than what high-end NVMe SSDs provide, but still well above 1GB/s. After the cache is full, write speed is cut in half but remains steady. As expected, the Host Memory Buffer feature has minimal impact on this purely sequential workload.
 |
|||||||||
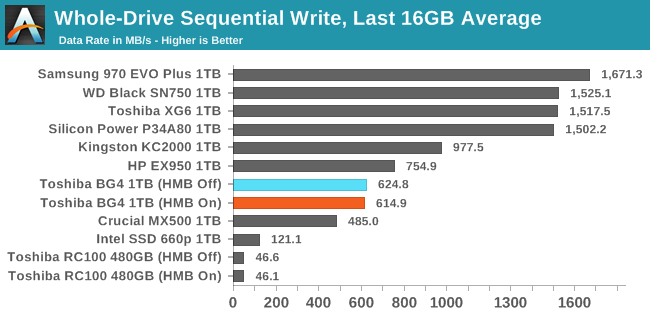
| Average Throughput for last 16 GB | Overall Average Throughput | ||||||||
After the SLC cache is full, the BG4's sequential write speed remains comfortably out of reach of SATA SSDs, but it doesn't come close to what high-end NVMe SSDs (including Toshiba's own XG series) provide. The BG3-based Toshiba RC100's write speed seriously tanked when the drive got close to full, but the 1TB BG4 doesn't suffer from that second major performance drop.
Working Set Size
Most mainstream SSDs have enough DRAM to store the entire mapping table that translates logical block addresses into physical flash memory addresses. DRAMless drives only have small buffers to cache a portion of this mapping information. Some NVMe SSDs (the BG4 included) support the Host Memory Buffer feature and can borrow a piece of the host system's DRAM for this cache rather needing lots of on-controller memory.
When accessing a logical block whose mapping is not cached, the drive needs to read the mapping from the full table stored on the flash memory before it can read the user data stored at that logical block. This adds extra latency to read operations and in the worst case may double random read latency.
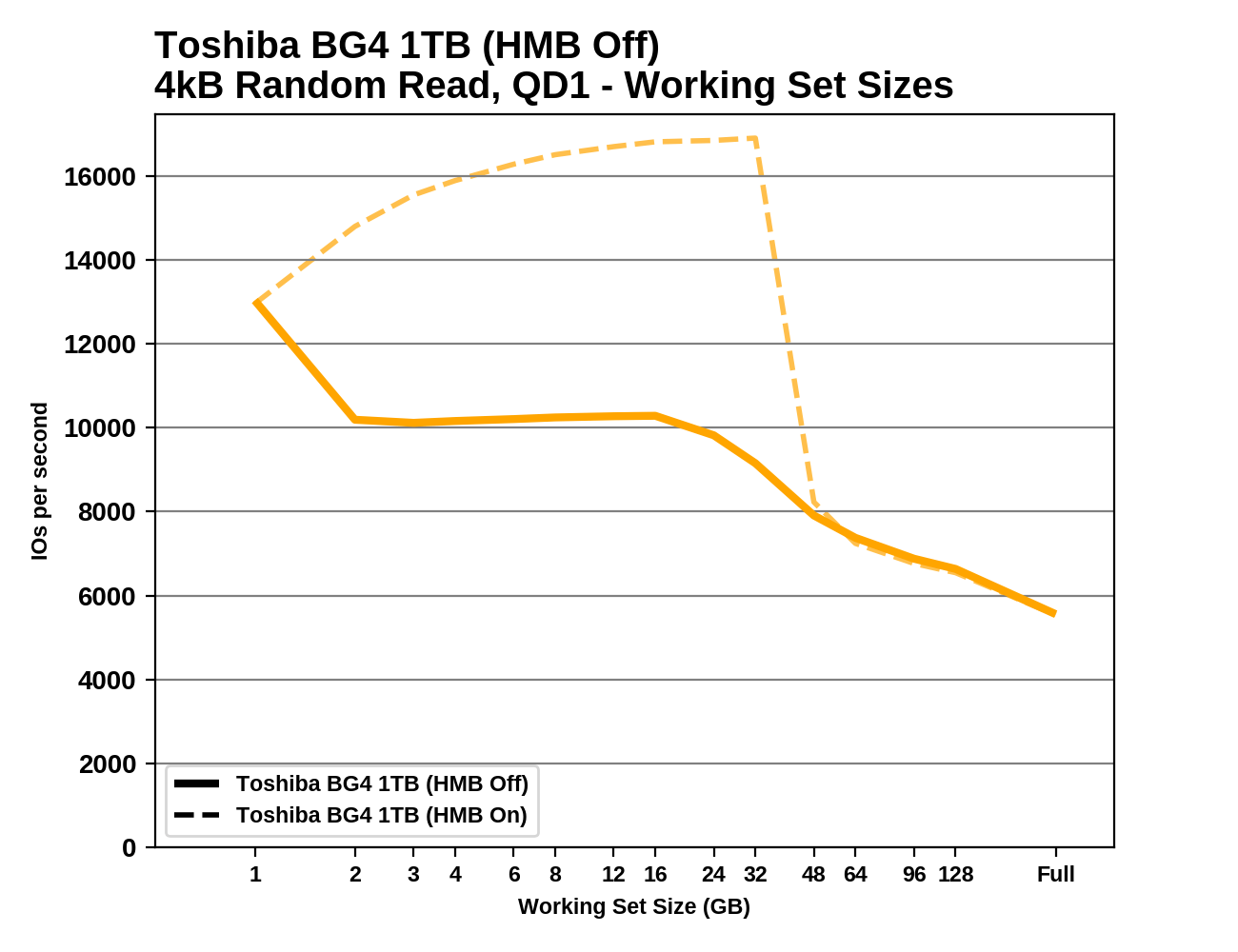
We can see the effects of the size of any mapping buffer by performing random reads from different sized portions of the drive. When performing random reads from a small slice of the drive, we expect the mappings to all fit in the cache, and when performing random reads from the entire drive, we expect mostly cache misses.
When performing this test on mainstream drives with a full-sized DRAM cache, we expect performance to be generally constant regardless of the working set size, or for performance to drop only slightly as the working set size increases.
 |
|||||||||
HMB has no effect on the BG4's random read performance for working set sizes larger than about 32GB. For smaller working sets, HMB provides a big performance boost. Oddly, the performance of the BG4 gets better through the early part of this test, until the working set size gets too big. With HMB off, the BG4 seems to have enough on-controller memory to handle a 1GB working set. As compared with the older BG3-based Toshiba RC100, the BG4 seems to use a slightly larger HMB, and it gets a bigger performance boost from that extra buffer.








31 Comments
View All Comments
intelati - Friday, October 18, 2019 - link
That last image is absolutely ridiculous. You get good performing 1TB of SSD storage on a postage stand.Jesus H Christ.
MaxUserName - Friday, October 18, 2019 - link
No, BG4 have too poor performance:https://www.storagereview.com/toshiba_bg4_nvme_ssd...
Ratman6161 - Friday, October 18, 2019 - link
I took a quick look at your link but quit looking when I saw they were testing SQL Server as one of their tests and with 15,000 virtual users. Completely useless use case. Even if you are are a software developer running a local copy of SQL Server, you won't be testing 15K users. So its performance somewhat pales in comparison to many full size m.2 SSD's. There are trade-offs to every component and in a laptop, particularly a thin and light laptop, those trade-offs usually have to favor saving space and power efficiency. It accomplishes those two goals on its own plus the smaller size may enable a larger battery in some systems. so what if your 2 TB 970 Evo outperforms it. The people buying the systems where this would be used won't care. It seems pretty ideally suited to its target audience.Tams80 - Friday, October 18, 2019 - link
I second that being a silly review.This is, as the article here states multiple times, for space-constrained devices. The BG4 more than meets the needs of these. As a bonus to us as customers, it means manufacturers are less likely to solder down the SSDs, so we can actually replace/upgrade them.
0ldman79 - Wednesday, November 13, 2019 - link
We're looking at a review right now.It's not as fast as NVME but it's faster than SATA on most benchmarks.
It's a quarter size of most NVME drives.
svan1971 - Saturday, October 19, 2019 - link
Lord, learn how to spell stamp, amen.wenart - Sunday, October 20, 2019 - link
Does Jesus have a second name?Jambe - Thursday, October 24, 2019 - link
Hieronymus, obviously.ToTTenTranz - Friday, October 18, 2019 - link
The Smach-Z uses a 2230 M.2 NVMe slot.Just saying.
Kishoreshack - Friday, October 18, 2019 - link
Excellent reviewdeep dive into the ssd we will get in our laptops
I just hope these form factors become common
&
are adopted for every laptop