AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked
by Johan De Gelas on August 7, 2019 7:00 PM ESTMemory Subsystem: Bandwidth
As we have reported before, measuring the full bandwidth potential with John McCalpin's Stream bandwidth benchmark has become a matter of extreme tuning, requiring a very deep understanding of the platform.
If we used our previous binaries, both the first and second generation EPYC could not get past 200-210 GB/s. It gave the impression of running into a "bandwidth wall", despite the fact that we now had 8-channel DDR4-3200. So we used the results that Intel and AMD best binaries produce using AVX-512 (Intel) and AVX-2 (AMD).
The results are expressed in gigabytes per second.
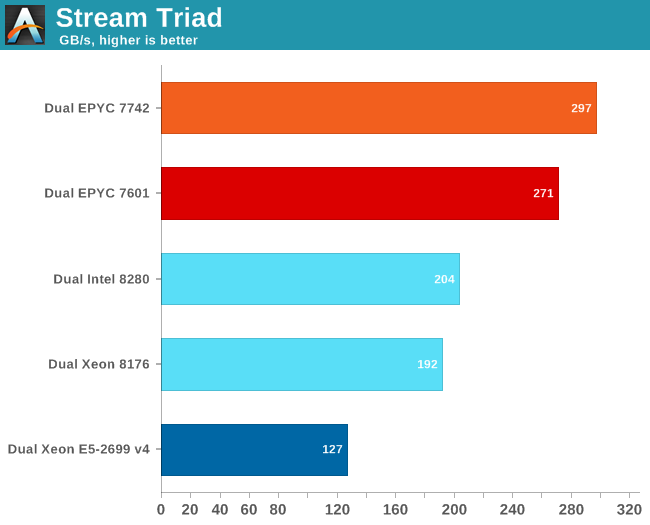
AMD can reach even higher numbers with the setting "number of nodes per socket" (NPS) set to 4. With 4 nodes per socket, AMD reports up to 353 GB/s. NPS4 will cause the CCX to only access the memory controllers with the lowest latency at the central IO Hub chip.
Those numbers only matter to a small niche of carefully AVX(-256/512) optimized HPC applications. AMD claims a 45% advantage compared to the best (28-core) Intel SKUs. We have every reason to believe them but it is only relevant to a niche.
For the rest of the enterprise world (probably 95+%), memory latency has much larger impact than peak bandwidth.








180 Comments
View All Comments
negusp - Wednesday, August 7, 2019 - link
hard F in the chat for intelpancakes - Wednesday, August 7, 2019 - link
F in chat for wallets of people running Windows serverazfacea - Wednesday, August 7, 2019 - link
windows server in 2019 LULdiehardmacfan - Wednesday, August 7, 2019 - link
on-prem Windows Server is probably at an all time high in 2019?azfacea - Thursday, August 8, 2019 - link
desperate for a comeback huh? cool hold your 10% tight and gloat about upcoming bfloat16diehardmacfan - Thursday, August 8, 2019 - link
Sorry, who is desperate for a comeback? Bring up a floating point format when called out on the ridiculous notion that Windows Server isn't still a large part of the marketplace? say whamkaibear - Thursday, August 8, 2019 - link
Just hopping in to say that I am an IT manager for a major employer in the UK and of our 1800 servers more than 80% of them are Windows... this is not a trend which I see changing any time soon.Deshi! - Thursday, August 8, 2019 - link
I work as an application engineer for a major global finance company that develops and hosts banking and e-commerce software used by banks and major shopping outlets. 90% of all our servers are either Linux or AIX mainly running websphere or standalone Java instances. We only have a handful of Windows servers, mainly for stuff like active directory and Outlook/ SharePoint. So yeah allot of it depends on the use case, but allot of the big boys do use Linux or AIX. It's cheaper and performs better for these use cases.cyberguyz - Thursday, August 8, 2019 - link
I guess we all have to ask ourselves, who are the customers that would benefit most from a 64-core, 128 gen 4 PCIe processors? SMB or huge customers that would shell out many millions of $$$ for their middleware & backend systems? @Deshi! I or one of my L3 colleagues an L3 engineer contacted by your global finance company to fix Websphere problems some years back ;)FreckledTrout - Thursday, August 8, 2019 - link
@cyberguz, Who would benefit from these high core servers? Any company running VM's so pretty much every large company. This goes doubly for cloud providers.