Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM ESTExploring Parallel HPC
HPC benchmarking, just like server software benchmarking, requires a lot of research. We are definitely not HPC experts, so we will limit ourselves to one HPC benchmark.
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization on thousands of cores. NAMD is also part of SPEC CPU2006 FP.
To be fair, NAMD is mostly single precision. And, as you probably know, the Titan RTX was designed to excel at single precision workloads; so the NAMD benchmark is a good match for the Titan RTX. Especially now that the NAMD authors reveal that:
Performance is markedly improved when running on Pascal (P100) or newer CUDA-capable GPUs.
Still, it is an interesting benchmark as the NAMD binary is compiled with Intel ICC and optimized for AVX. For our testing, we used the "NAMD_2.13_Linux-x86_64-multicore" binary. This binary supports AVX instructions, but only the "special” AVX-512 instructions for the Intel Xeon Phi. Therefore, we also compiled an AVX-512 ICC optimized binary. This way we can really measure how well the AVX-512 crunching power of the Xeon compares to NVIDIA’s GPU acceleration.
We used the most popular benchmark load, apoa1 (Apolipoprotein A1). The results are expressed in simulated nanoseconds per wall-clock day. We measure at 500 steps.
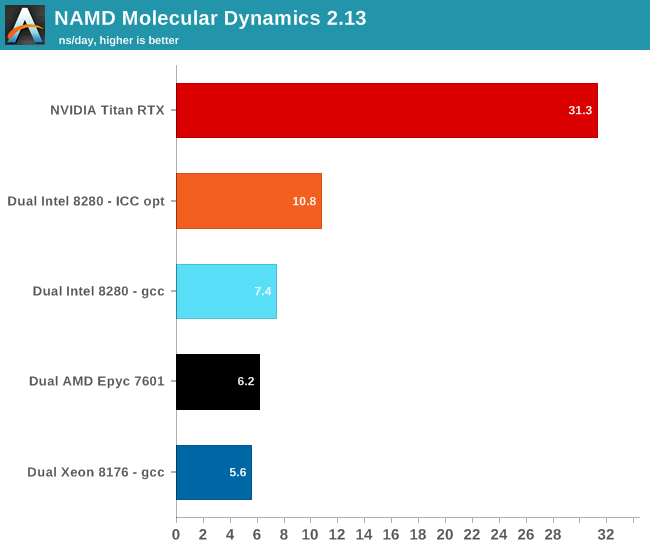
Using AVX-512 boosts performance in this benchmark by 46%. But again, this software runs so much faster on a GPU, which is of course understandable. At best, the Xeon has 28 cores running at 2.3 GHz. Each cycle 32 single precision floating operations can be done. All in all, the Xeon can do 2 TFLOPs (2.3 G*28*32). So a dual Xeon setup can do 4 TFLOPs at the most. The Titan RTX, on the other hand, can do 16 TFLOPs, or 4 times as much. The end result is that NAMD runs 3 times faster on the Titan than on the dual Intel Xeon.








56 Comments
View All Comments
tipoo - Monday, July 29, 2019 - link
Fyi, when on page 2 and clicking "convolutional, etc" for page 3, it brings me back to the homepageRyan Smith - Monday, July 29, 2019 - link
Fixed. Sorry about that.Eris_Floralia - Monday, July 29, 2019 - link
Johan's new piece in 14 months! Looking forward to your Rome review :)JohanAnandtech - Monday, July 29, 2019 - link
Just when you think nobody noticed you were gone. Great to come home again. :-)Eris_Floralia - Tuesday, July 30, 2019 - link
Your coverage on server processors are great!Can still well remember Nehalem, Barcelona, and especially Bulldozer aftermath articles
djayjp - Monday, July 29, 2019 - link
Not having a Tesla for such an article seems like a glaring omission.warreo - Monday, July 29, 2019 - link
Doubt Nvidia is sourcing AT these cards, so it's likely an issue of cost and availability. Titan is much cheaper than a Tesla, and I'm not even sure you can get V100's unless you're an enterprise customer ordering some (presumably large) minimum quantity.olafgarten - Monday, July 29, 2019 - link
It is available https://www.scan.co.uk/products/32gb-pny-nvidia-te...abufrejoval - Tuesday, July 30, 2019 - link
Those bottlenecks are over now and P100, V100 can be bought pretty freely, as well as RTX6000/8000 (Turings). Actually the "T100" is still missing and the closest siblings (RTX 6000/8000) might never get certified for rackmount servers, because they have active fans while the P100/V100 are designed to be cooled by server fans. I operate a handful of each and getting budget is typically the bigger hurdle than purchasing.SSNSeawolf - Monday, July 29, 2019 - link
I've been trying to find more information on Cascade Lake's AI/VNNI performance, but came up dry. Thanks, Johan. Eagerly putting this aside for my lunch reading today.