Arm's New Cortex-A77 CPU Micro-architecture: Evolving Performance
by Andrei Frumusanu on May 27, 2019 12:01 AM ESTThe Cortex-A77 µarch: Added ALUs & Better Load/Stores
Having covered the front-end and middle-core, we move onto the back-end of the Cortex-A77 and investigate what kind of changes Arm has made to the execution units and data pipelines.
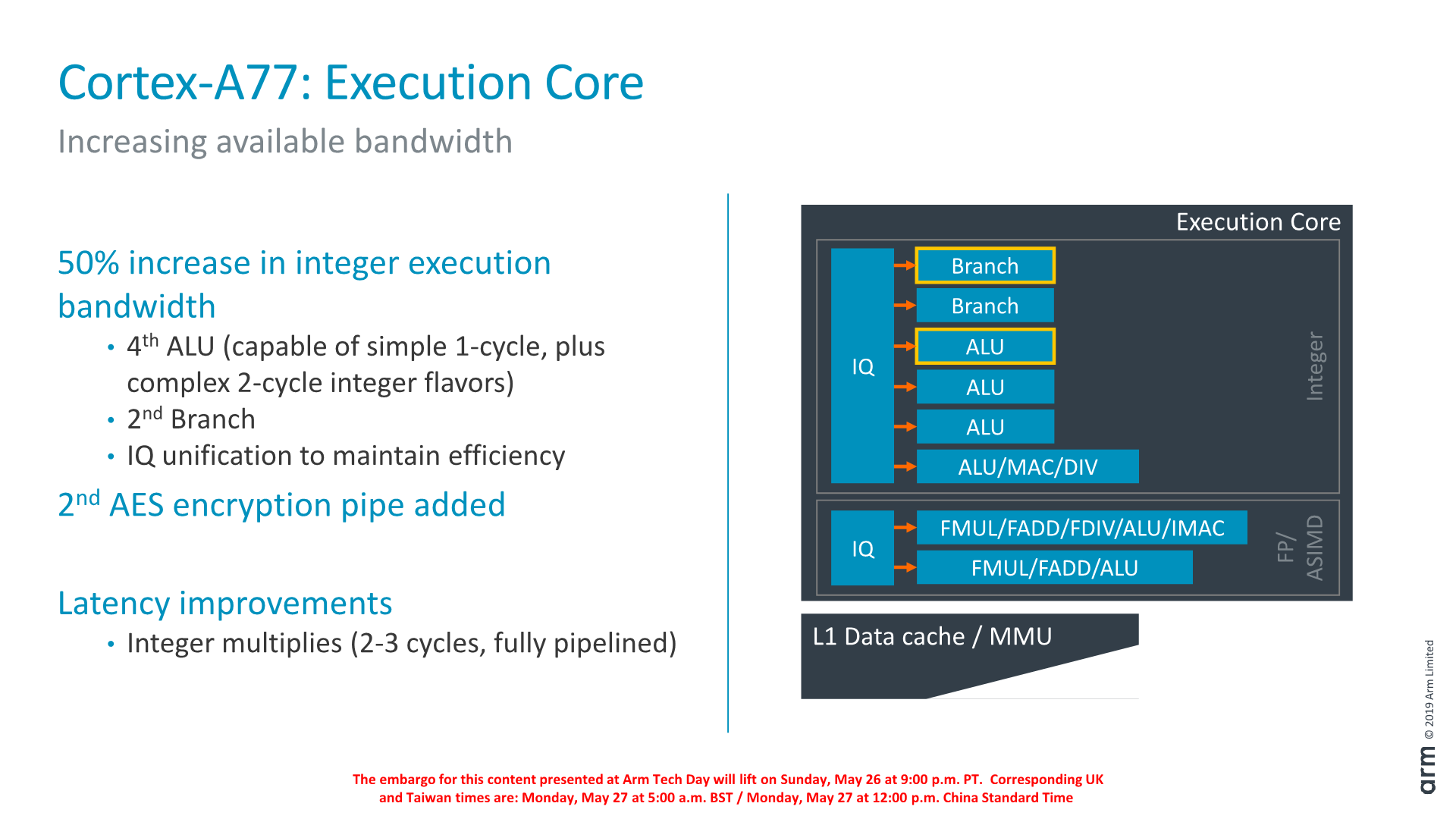
On the integer execution side of the core we’ve seen the addition of a second branch port, which goes along with the doubling of the branch-predictor bandwidth of the front-end.
We also see the addition on an additional integer ALU. This new unit goes half-way between a simple single-cycle ALU and the existing complex ALU pipeline: It naturally still has the ability of single-cycle ALU operations but also is able to support the more complex 2-cycle operations (Some shift combination instructions, logical instructions, move instructions, test/compare instructions). Arm says that the addition of this new pipeline saw a surprising amount of performance uplift: As the core gets wider, the back-end can become a bottleneck and this was a case of the execution units needing to grow along with the rest of the core.
A larger change in the execution core was the unification of the issue queues. Arm explains that this was done in order to maintain efficiency of the core with the added execution ports.
Finally, existing execution pipelines haven’t seen much changes. One latency improvement was the pipelining of the integer multiply unit on the complex ALU which allows it to achieve 2-3 cycle multiplications as opposed to 4.
Oddly enough, Arm didn’t make much mention of the floating-point / ASIMD pipelines for the Cortex-A77. Here it seems the A76’s “state-of-the-art” design was good enough for them to focus the efforts elsewhere on the core for this generation.

On the part of the load/store units, we still find two units, however Arm has added two additional dedicated store ports to the units, which in effect doubles the issue bandwidth. In effect this means the L/S units are 4-wide with 2 address generation µOps and 2 store data µOps.
The issue queues themselves again have been unified and Arm has increased the capacity by 25% in order to expose more memory-level parallelism.

Data prefetching is incredibly important in order to hide memory latency of a system: Shaving off cycles by avoiding to having to wait for data can be a big performance boost. I tried to cover the Cortex-A76’s new prefetchers and contrast it against other CPUs in the industry in our review of the Galaxy S10. What stood out for Arm is that the A76’s new prefetchers were outstandingly performant and were able to deal with some very complex patterns. In fact the A76 did far better than any other tested microarchitecture, which is quite a feat.
For the A77, Arm improved the prefetchers and added in even new additional prefetching engines to improve this even further. Arm is quite tight-lipped about the details here, but we’re promised increased pattern coverages and better prefetching accuracy. One such change is claimed to be “increased maximum distance”, which means the prefetchers will recognize repeated access patterns over larger virtual memory distances.
One new functional addition in the A77 is so called “system-aware prefetching”. Here Arm is trying to solve the issue of having to use a single IP in loads of different systems; some systems might have better or worse memory characteristics such as latency than others. In order to deal with this variance between memory subsystems, the new prefetchers will change the behaviour and aggressiveness based on how the current system is behaving.
A thought of mine would be that this could signify some interesting performance improvements under some DVFS conditions – where the prefetchers will alter their behaviour based on the current memory frequency.
Another aspect of this new system-awareness is more knowledge of the cache pressure of the DSU’s L3 cache. In case that other CPU cores would be highly active, the core’s prefetchers would see this and scale down its aggressiveness in order to possibly avoid thrashing the shared cache needlessly, increasing overall system performance.








108 Comments
View All Comments
abufrejoval - Monday, May 27, 2019 - link
While extending all that prefetching seems such a great thing for performance, it also expands the attack surface of side-channel attacks. So I wonder if the public awareness came to late in the game for this design for the team to review or even correct for that.SaberKOG91 - Monday, May 27, 2019 - link
And I suppose we should stop using branch prediction too because anything speculative is inherently insecure? /sWe've known about prefetch side-channel attacks for quite awhile now, as well as developed techniques to mitigate many of them. Do you really think ARM are so unaware of these issues?
rahvin - Tuesday, May 28, 2019 - link
Although side-channel attacks have been known about for a long time, the first viable attack wasn't developed until last year and there has been a steady stream of additional viable attacks since the first. In fact it's arguable that the severity of the attacks is going up with each discovery.They called it Spectre for a reason, they figured it was going to haunt computer design for the foreseeable future. Side channel attacks are here to stay and they aren't done finding new ones. Though we can't abandon speculative execution, any company that didn't take into account this attack method in future designs was foolish.
SaberKOG91 - Wednesday, May 29, 2019 - link
I don't disagree with any of your statements. I was annoyed by their ignorant attitude towards the importance of speculative features of modern CPU design. We need them for the sake of performance and there shouldn't need to be a steep trade-off between security and performance in order to keep these features. It's clear that AMD were able to design a more secure core that isn't affected by many of the side-channel attacks that Intel are vulnerable to, without a huge performance tradeoff. I doubt that ARM would willingly repeat these mistakes now that these attacks are known.rocky12345 - Wednesday, July 3, 2019 - link
Just a question I guess wasn't Spectre just what they called it when they found that someone could exploit the CPU like that. Up until then and I do not think there has been any real attacks that came out of this yet. My point is what if they did not make Spectre public and just fixed it behind closed doors. Then neither us or the attackers would have been clued in to it all. Also then there would not have been all these other finds for maybe attacks as well since then. I guess what I am saying sometimes us the public do not need to know some of these things because it just might also inform the low life's that like to do these exploits. Just my 2 cents worth and opinion on it all.syxbit - Monday, May 27, 2019 - link
I know you brought up Apple multiple times, but I really wish it got brought up even more. Every Q&A with ARM should say "Hey, stop boasting until you catch up to Apple"It's frustrating as an Android user to have seriously inferior SoCs....
Nozuka - Monday, May 27, 2019 - link
Even more frustrating to have one of these SoCs, but nothing actually uses its power...Unless you count bragging rights
Wilco1 - Monday, May 27, 2019 - link
Define inferior. Phone SoCs are not just about maximum single threaded performance. And Apple users found out the performance cannot be sustained by batteries...Android users get better power efficiency and lower cost phones due to lower die size of SoCs. As Andrei has shown, simply chasing high benchmark scores (like Samsung did with their custom cores) does not seem to work out so well.
syxbit - Monday, May 27, 2019 - link
Lower cost phones?Flagships from Google and Samsung cost the same as an iPhone, and the iPhone trounces them in performance.
Wilco1 - Monday, May 27, 2019 - link
There are plenty high-end Android phones which cost about half of an equivalent iPhone. Eg. OnePlus 7 Pro is $699 with 256GB flash vs $1249 for a similar spec Xs Max.