Investigating NVIDIA's Jetson AGX: A Look at Xavier and Its Carmel Cores
by Andrei Frumusanu on January 4, 2019 11:00 AM EST- Posted in
- NVIDIA
- SoCs
- Xavier
- Automotive
- Jetson
- Jetson AGX
NVIDIA's Carmel CPU Core - SPEC2006 Rate
Something that we have a tough time testing on other platforms is the multi-threaded performance of CPUs. On mobile devices thermal constraints largely don’t allow these devices to showcase the true microarchitectural scaling characteristics of a platform, as it's not possible to maintain high clockspeeds. NVIDIA’s Jetson AGX dev kit doesn’t have these issues thanks to its oversized cooler, and this makes it a fantastic opportunity to test out Xavier's eight Carmel cores, as all are able to run at peak frequency without worries about thermals (in our test bench scenario).
SPEC2006 Rate uses the same workloads as the Speed benchmarks, with the only difference being that we’re launching more instances (processes) simultaneously.
Starting off with SPECin2006 rate:
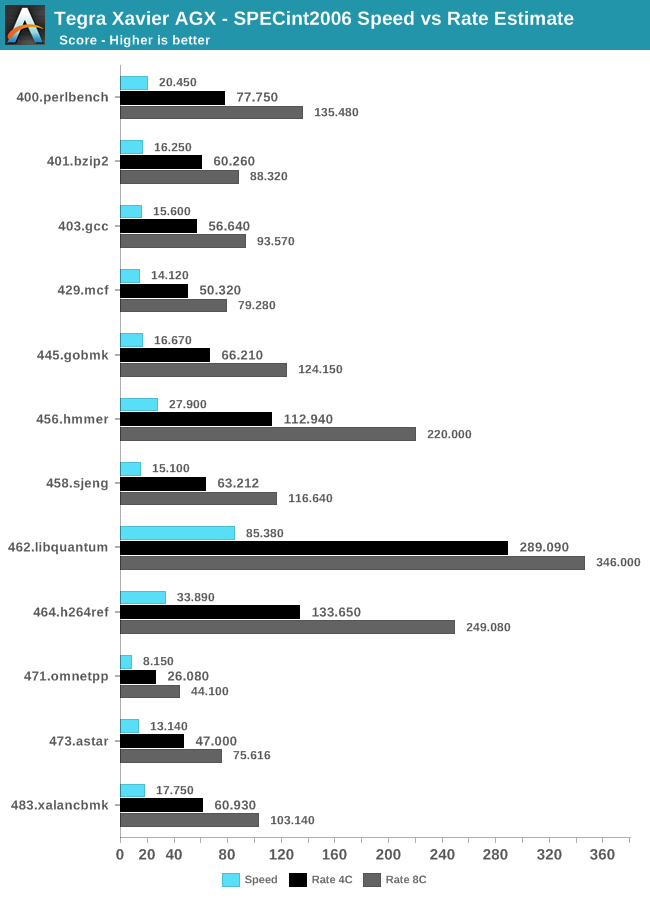
The way that SPEC2006 rate scores are calculated is that it measures the execution time of all instances and uses the same reference time scale as the Speed score- with the only difference here being is that the final score is multiplied by the amount of instances.
I chose to run the rate benchmarks with both 4 and 8 instances to showcase the particularity of NVIDIA’s Carmel CPU core configuration. Here we see the four core run perform roughly as expected, however the eight core run scores are a bit less than you’d expect. To showcase this better, let’s compare the scaling factor in relation to the single-core Speed results:
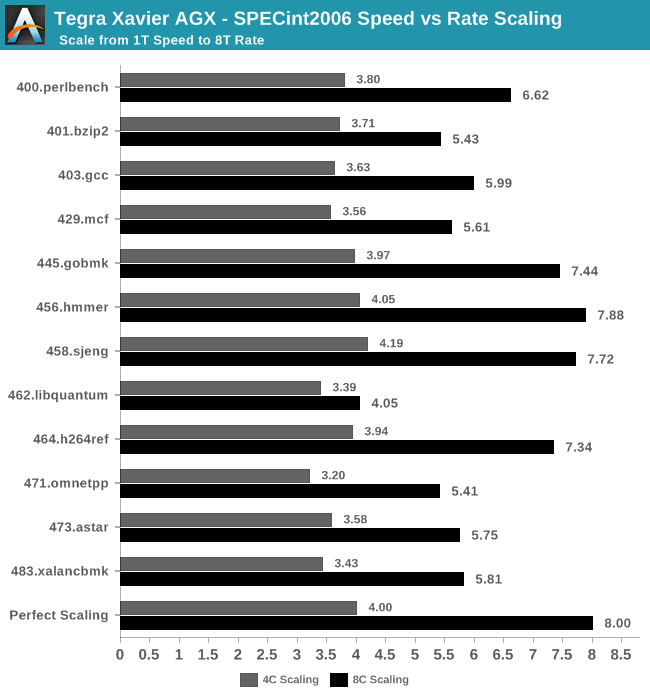
The majority of the 4C workloads scaling near the optimal 4x factor that we’d come to expect, with only a few exceptions having a little worse performance scaling figures. The 8C workloads however showcase significantly worse performance scaling factors, and it’s here where things get interesting:
Because Xavier’s CPU complex consists of four CPU clusters, each with a pair of Carmel cores and 2MB L2 cache shared among each pair, we have a scenario where the CPU cores can be resource constrained. In fact, by default what the kernel scheduler on the AGX does is to try to populate one core within all clusters first, before it schedules anything on the secondary cores within a cluster.
In effect what this means that in the 4C rate scenarios, each core within a cluster essentially has exclusive use of the 2MB L2 cache, while on the 8C rate workloads, the L2 cache has to be actively shared among the two cores, resulting in resource contention and worse performance per core.
The only workloads that aren’t nearly as affected by this, are the workloads which are largely execution unit bound and put less stress on the data plane of the CPU complex, this can be seen in the great scaling of some workloads such as 456.hmmer for example. On the opposite end, workloads such as 462.libquantum suffer dramatically under this kind of CPU setup, and the CPU cores are severely bandwidth starved and can’t process things any faster than if there were just one core per cluster active.
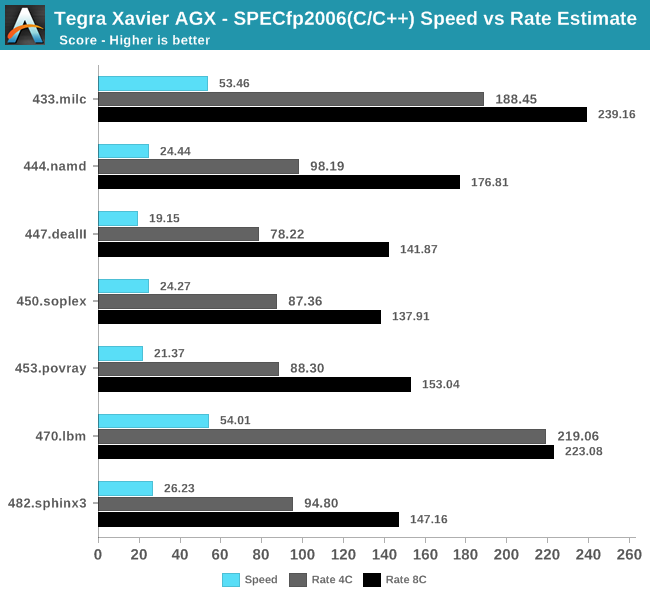
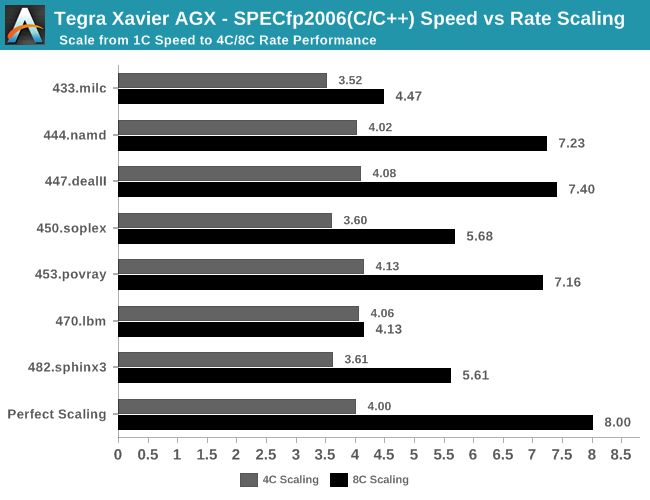
The same analysis can be applied to the floating point rate benchmarks: Some of the less memory sensitive workloads don’t have all that much issue in scaling well with core counts, however others such as 433.milc and 470.lbm again showcase quite bad performance figures when run on all cores on the system.
Overall, NVIDIA's design choices for Xavier’s CPU cluster are quite peculiar. It’s possible that NVIDIA either sees a majority of workloads targeted on the AGX to not be an issue in terms of their scaling, or actual use of the platform in automotive use-cases we would see each core in a cluster operating in lock-step with each other, theoretically eliminating possible resource contention issues on the level of the shared L2 cache.
I didn’t get to measure full power figures for all rate benchmarks, but in general the power of an additional core within a separate cluster will scale near linearly with the power figures of the previously discussed single-core Speed runs, meaning the 4-core rate benchmarks showcase active power usage of around ~12-15W. Because performance doesn’t scale linearly with the additional secondary cluster cores, the power increase was also more limited. Here I saw up to a total system power consumption of up to ~31W for workloads such as 456.hmmer (~22W active), while more bottlenecked workloads ran around ~21-25W for the total platform (~12-16W active).








51 Comments
View All Comments
syxbit - Friday, January 4, 2019 - link
I wish Nvidia hadn't abandoned the mobile space. They could have brought some much needed competition :( :(.Despoiler - Friday, January 4, 2019 - link
The only design that was competitive was the one selected by Google for one generation. 4 ARM cores + a 5th core for power management was a huge failure when everyone can do PM within the ARM SOC. It was only cost competitive in other words.syxbit - Friday, January 4, 2019 - link
The Tegra X1 was a great chip when released.The Shield TV still uses it, and it's an excellent (though now old) chip.
Alistair - Friday, January 4, 2019 - link
And that's not a mobile device. Perf/W for Xavier is also really poor vs. the newest Huawei silicon also.BenSkywalker - Friday, January 4, 2019 - link
The Switch is mobile. When the x1 debuted *four* years ago it obliterated the best from Apple, roughly 50%-100% faster on the gpu side. So yes, if we give the other soc manufacturers four years and a four process step advantage, they can edge out Tegra.Qualcomm's lawyers should take a bow on nVidia not being still present in the mobile market, certainly not the laughable "competition" they had on the technology side.
"Having a hard time seeing a path forward"... That was a cringe worthy line. Why not benchmark direct x on an iPhone and then say the same about the Ax line? Let's take a deep learning/ai platform and benchmark it using antiquated pc desktop applications and then act like there are fundamental design issues... ?
TheinsanegamerN - Friday, January 4, 2019 - link
The tegra X1 doesnt run anywhere near full speed when the device is not plugged into a power source. The Switch also has a fan. It's pretty easy to "obliterate" the competition when you are using a different form factor. I mean, the core I7 with iris pro 580 GPU obliterates the tegra X1, so the X1 must not be very good right?The X1 was WAY too power hungry to use in anything other then a dedicated gaming device with a dedicated cooling system. When restricted down to tablet TDPs, the X1's performance drops like a lead rock.
So, yeah, maybe with another 4 years nvidia could make the tegra work in a proper laptop. Meanwhile, Apple has ALREADY done that with the A12 SoC, and that works in a passive tablet. Nvidia was never able to make their SoC work in a similar system.
Alistair - Saturday, January 5, 2019 - link
Are you replying to my comment? Xavier is new for 2018 and so is Huawei's Kirin 980. We are talking about Xavier, not X1. And Apple's tablet GPU for 2015 equaled nVidia's in perf. The iPad Pro's A9X equalled the Tegra x1 in GPU performance while surpassing it in CPU performance, and at a lower power draw...Alistair - Saturday, January 5, 2019 - link
I think you were conveniently comparing the 2014 iPad's vs. the 2015 X1, instead of the 2015 iPad Pro vs. the X1.Samus - Saturday, January 5, 2019 - link
^^thisniva - Friday, January 4, 2019 - link
Why are there video ads automatically playing on each one of the Anandtech pages? I know you guys are trying to monetize but you've crossed lines that make it annoying for your users to keep visiting the site.