Improving The Exynos 9810 Galaxy S9: Part 2 - Catching Up With The Snapdragon
by Andrei Frumusanu on April 20, 2018 9:00 AM EST- Posted in
- Mobile
- Samsung
- Smartphones
- Exynos 9810
- Exynos M3
- Galaxy S9
Scheduler mechanisms: WALT & PELT
Over the years, it seems Arm noticed the slow progress and now appears to be working more closely with Google in developing the Android common kernel, utilizing out-of-tree (meaning outside of the official Linux kernel) modifications that benefit performance and battery life of mobile devices. Qualcomm also has been a great contributor as WALT is now integrated into the Android common kernel, and there’s a lot of work going on from these parties as well as other SoC manufacturers to advance the platform in a way that benefits commercial devices a lot more.
Samsung LSI’s situation here seems very puzzling. The Exynos 9810 is the first flagship SoC to actually make use of EAS, and they are basing the BSP (Board support package) kernel off of the Android common kernel. The issue here is that instead of choosing to optimise the SoC through WALT, they chose to fall back to full PELT dictated task utilisation. That’s still fine in terms of core migrations, however they also chose to use a very vanilla schedutil CPU frequency driver. This meant that the frequency ramp-up of the Exynos 9810 CPUs could have the same characteristics as PELT, which means it would be also bring with it one of the existing disadvantages of PELT: a relatively slow ramp-up.
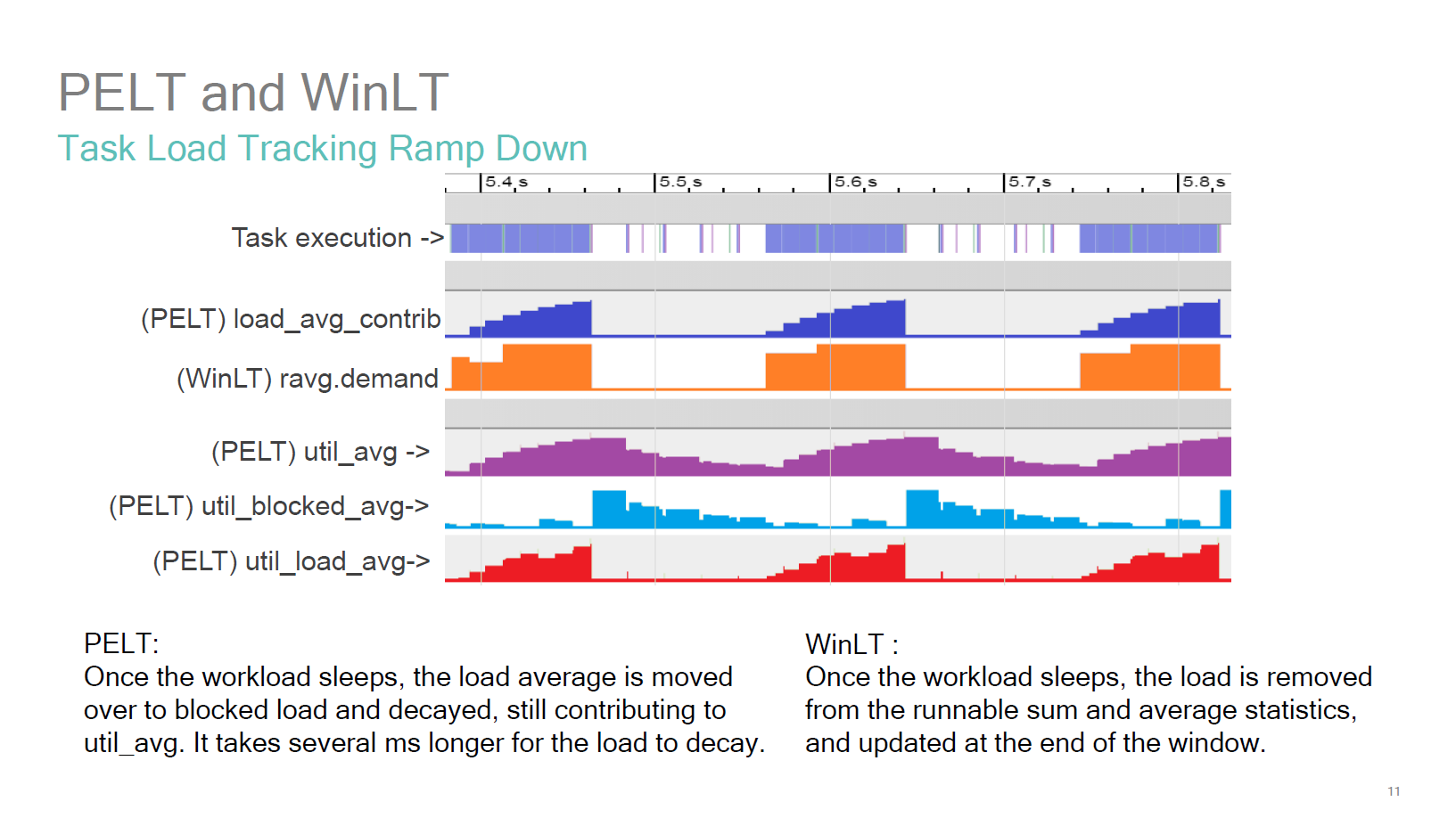
Source: BKK16-208: EAS
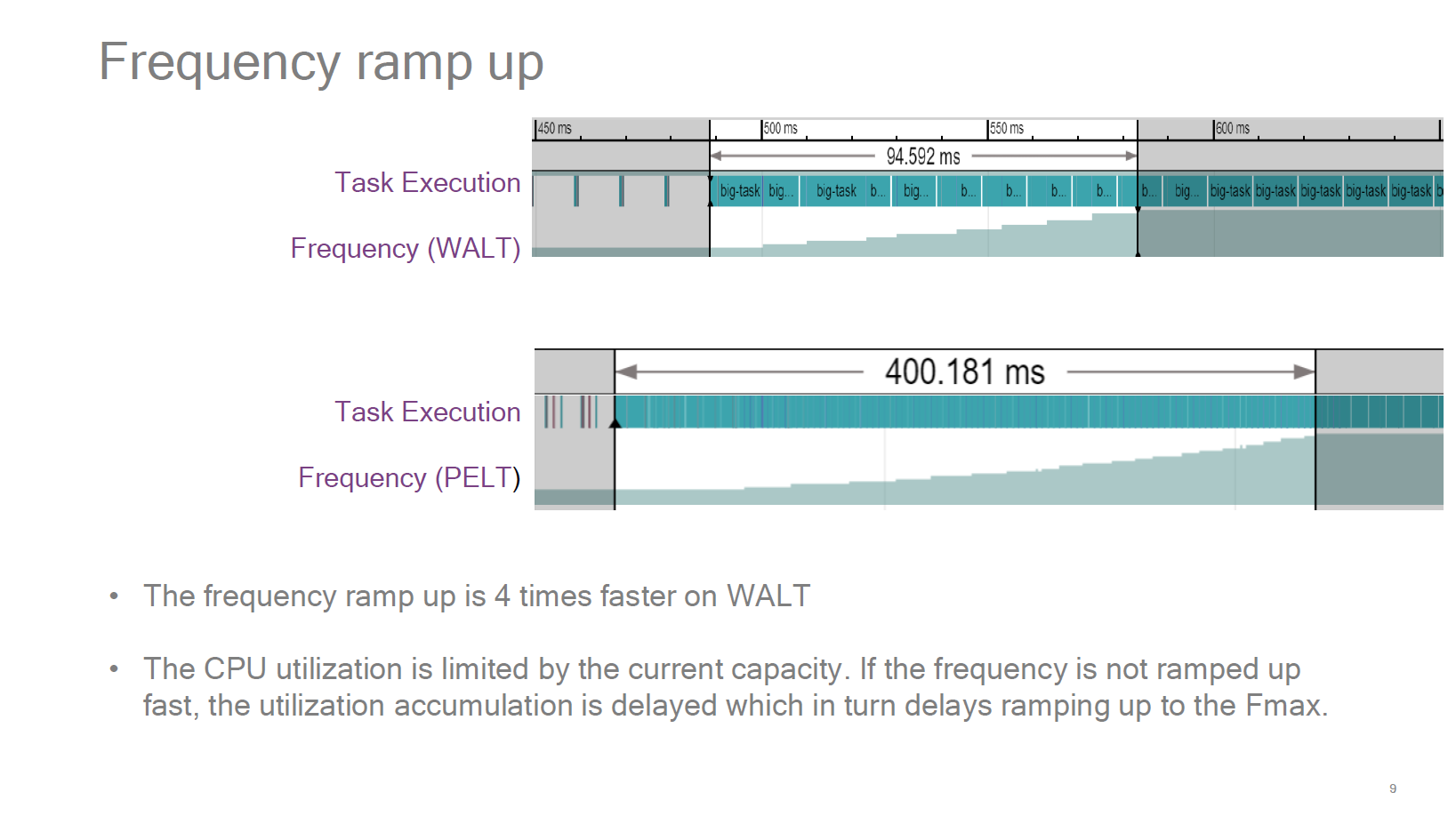
Source: WALT vs PELT : Redux – SFO17-307
One of the best resources on the issue actually comes from Qualcomm, as they had spearheaded the topic years ago. In the above presentation presented at Linaro Connect 2016 in Bangkok, we see the visual representation of the behaviour of PELT vs WinLT (which WALT was called at the time). The metrics to note here in the context of the Exynos 9810 are the util_avg (which is the default behaviour on the Galaxy S9) and the contrast to WALT’s ravg.demand and actual task execution. So out of all the possible options in terms of BSP configurations, Samsung seemed to have chosen the worst one for performance. And I do think this seems to have been a conscious choice as Samsung had made additional mechanisms to the both the scheduler (eHMP) and schedutil (freqvar) to counteract this very slow behaviour caused by PELT.
In trying to resolve this whole issue, instead of adding additional logic on top of everything I looked into fixing the issue at the source.
What was first tried is perhaps the most obvious route, and that's to enable WALT and see where that goes. While using WALT as a CPU utilisation signal for the Exynos S9 gave outstandingly good performance, it also very badly degraded battery life. I had a look at the Snapdragon 845 Galaxy S9’s scheduler, but here it seems Qualcomm diverges significantly from the Google common kernel which the Exynos is based on. This being far too much work to port, I had another look at the Pixel 2’s kernel – which luckily was a lot nearer to Samsung’s. I ported all relevant patches which were also applied to the Pixel 2 devices, along with porting EAS to a January state of the 4.9-eas-dev branch. This improved WALT’s behaviour while keeping performance, however there was still significant battery life degradation compared to the previous configuration. I didn’t want to spend more time on this so I looked through other avenues.
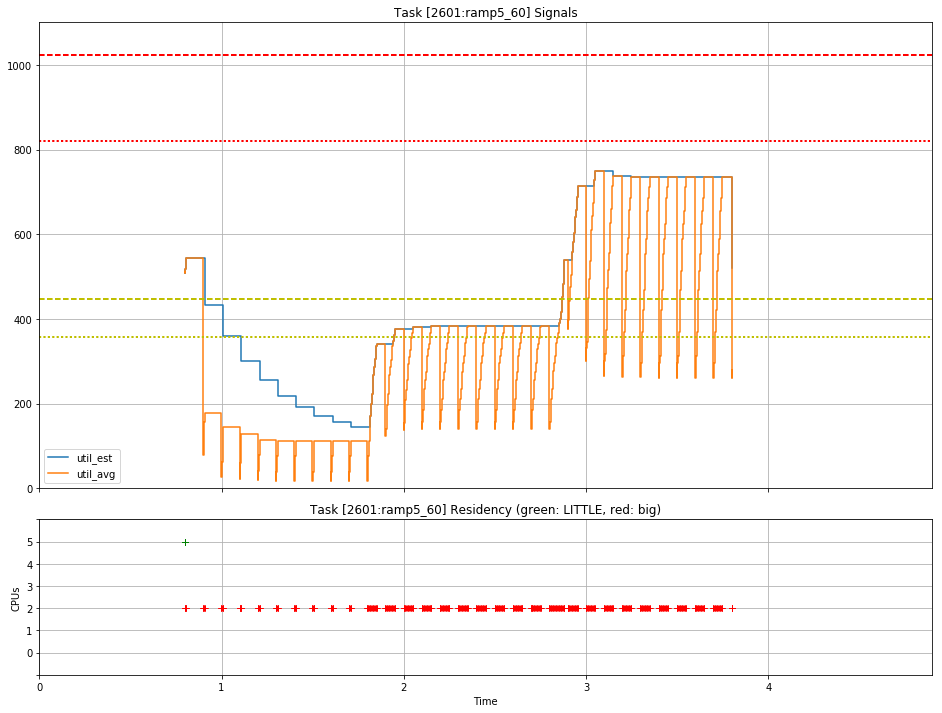
Source : LKML Estimate_Utilization (With UtilEst)
Looking through Arm's resources, it looks very much like the company is aware of the performance issues and is actively trying to improve the behaviour of PELT to more closely match that of WALT. One significant change is a new utilisation signal called util_est (Utilisation estimation) which is added on top of WALT and is meant to be used for CPU frequency selection. I backported the patch and immediately saw a significant improvement in responsiveness due to the higher CPU frequency state utilisation. Another simple way of improving PELT was reducing the ramp/decay timings, which incidentally also got an upstream patch very recently. I backported this as well to the kernel, and after testing a 8ms half-life setting for a bit and judging it to not be good for battery life, I settled on a 16ms settings, which is an improvement over the 32ms of the stock kernel and gives the best performance and battery compromise.
Because of these significant changes in the way the scheduler is fed utilisation statistics, the existing tuning from Samsung obviously weren’t valid anymore. I adapted most of them to the best I could, which basically involves just disabling most of them as they were no longer needed. Also I significantly changed the EAS capacity and cost tables, as I do not think that the way Samsung populated the table is correct or representative of actual power usage, which is very unfortunate. Incidentally, this last bit was one of the reasons that performance changed when I limited the CPU frequency in part 1, as it shifted the whole capacity table and changed the scheduler heuristic.
But of course, what most of you are here for is not how this was done but rather the hard data on the effects of my experimenting, so let's dive into the results.








76 Comments
View All Comments
zepi - Friday, April 20, 2018 - link
Andrei, how come you are still with Anandtech and not working for one of the big smartphone manufacturers, Qualcomm or maybe ARM?zepi - Friday, April 20, 2018 - link
Excellent piece, like always btw.tipoo - Friday, April 20, 2018 - link
(smartphone manufacturers, please don't take him too! :P )Manch - Friday, April 20, 2018 - link
AndreiTechMorawka - Friday, April 20, 2018 - link
We need good writers, he's fine where he's at. He can always do consulting like Anand did. This is a great investigative piece and i'm glad Anandtech has linux guru's who can make their own OS through a patchwork of kernal modifications.RaduR - Tuesday, April 24, 2018 - link
Andrei was working for ImgTech if i'm not mistaking. Unfortunately since Apple move ImgTech without MIPS I dont't think will ever come out with a SOC.Real one not just on paper.
So unfortunate that MIPS+PowerVR was never to become a successful competition to ARM.
juicytuna - Friday, April 20, 2018 - link
Great stuff. Reads like a job application to the S.LSI BSP team.fishjunk - Friday, April 20, 2018 - link
Excellent investigation. Samsung designed the M3 core with wider decode, lower frequency, and potentially better integration with its own hardware yet still could not match the performance and efficiency of ARM A75. Why did they not do their internal testing of A75 before deciding to go with M3?eastcoast_pete - Friday, April 20, 2018 - link
My strong guess is that Samsung has the same idea that Apple has for its future MacBooks - Intel outside. In mobile systems (phones), well executed hardware and software designs of wide and deep cores (Apple: yes, Samsung: not really) can offer great peak performance but have to throttle heavily due to thermal and power constraints. Same core designs in a laptop with good heat management and a much larger battery, those restraints are loosened significantly. Samsung's attempt failed mostly due to their typical report card - hardware: A- or B+, software: D or F.That being said, Apple's drive towards in-house chips plus the ongoing Windows 10 on Snapdragon 835/845 initiative by Qualcomm and MS doesn't augur well for Intel's almost-monopoly in the ultraportable laptop and 2-in-1 market, especially once Samsung & Co. get their act together.
serendip - Friday, April 20, 2018 - link
I used to share your optimism on ARM muscling into Intel territory but now I'm not so sure. Snapdragon Win10 PCs have been announced but nobody's buying them - this really does smell like WinRT and Surface RT all over again. Microsoft, Qualcomm and PC OEMs are adopting a wait and see approach when they should be going all-out on ARM.