Intel's Pentium 4 E: Prescott Arrives with Luggage
by Anand Lal Shimpi & Derek Wilson on February 1, 2004 3:06 PM EST- Posted in
- CPUs
Larger, Slower Cache
On the surface Prescott is nothing more than a 90nm Pentium 4 with twice the cache size, but we’ve hopefully been able to illustrate quite the contrary thus far. Despite all of the finesse Intel has exhibited with improving branch predictors, scheduling algorithms and new execution blocks they did exploit one of the easiest known ways to keep a long pipeline full – increase cache size.
With Prescott Intel debuted their highest density cache ever – each SRAM cell (the building blocks of cache) is now 43% smaller than the cells used in Northwood. What this means is that Intel can pack more cache into an even smaller area than if they had just shrunk the die on Prescott.
While Intel has conventionally increased L2 cache size, L1 cache has normally remained unchanged – armed with Intel’s highest density cache ever, Prescott gets a larger L1 cache as well as a larger L2.
The L1 Data cache has been doubled to a 16KB cache that is now 8-way set associative. Intel states that the access latency to the L1 Data cache is approximately the same as Northwood’s 8KB 4-way set associative cache, but the hit rate (probability of finding the data you’re looking for in cache) has gone up tremendously. The increase in hit rate is not only due to the increase in cache size, but also the increase in associativity.
Intel would not reveal (even after much pestering) the L1 cache access latency, so we were forced to use two utilities - Cachemem and ScienceMark to help determine if there was any appreciable increase in access latency to data in the L1.
| Cachemem L1 Latency | ScienceMark L1 Latency | |
|---|---|---|
Northwood |
1 cycle |
2 cycles |
Prescott |
4 cycles |
4 cycles |
Although Cachemem and ScienceMark don't produce identical results, they both agree on one thing: Prescott's L1 cache latency is increased by more than an insignificant amount. We will just have to wait for Intel to reveal the actual access latencies for L1 in order to confirm our findings here.
Although the size of Prescott’s Trace Cache remains unchanged, the Trace Cache in Prescott has been changed for the better thanks to some additional die budget the designers had.
The role of the Trace Cache is similar to that of a L1 Instruction cache: as instructions are sent down the pipeline, they are cached in the Trace Cache while data they are operating on is cached in the L1 Data cache. A Trace Cache is superior to a conventional instruction cache in that it caches data further down in the pipeline, so if there is a mispredicted branch or another issue that causes execution to start over again you don’t have to start back at Stage 1 of the pipeline – rather Stage 7 for example.
The Trace Cache accomplishes this by not caching instructions as they are sent to the CPU, but the decoded micro operations (µops) that result after sending them through the P4’s decoders. The point of decoding instructions into µops is to reduce their complexity, once again an attempt to reduce the amount of work that has to be done at any given time to boost clock speeds (AMD does this too). By caching instructions after they’ve already been decoded, any pipeline restarts will pick up after the instructions have already made it through the decoding stages, which will save countless clock cycles in the long run. Although Prescott has an incredibly long pipeline, every stage you can shave off during execution, whether through Branch Prediction or use of the Trace Cache, helps.
The problem with a Trace Cache is that it is very expensive to implement; achieving a hit rate similar to that of an instruction cache requires significantly more die area. The original Pentium 4 and even today’s Prescott can only cache approximately 12K µops (with a hit rate equivalent to an 8 – 16KB instruction cache). AMD has a significant advantage over Intel in this regard as they have had a massive 64KB instruction cache ever since Athlon. Today’s compilers that are P4 optimized are aware of the very small Trace Cache so they produce code that works around it as best as possible, but it’s still a limitation.
Another limitation of the Trace Cache is that because space is limited, not all µops can be encoded within it. For example, complicated instructions that would take a significant amount of space to encode within the Trace Cache are instead left to be sequenced from slower ROM that is located on the chip. Encoding logic for more complicated instructions can occupy precious die space that is already limited because of the complexity of the Trace Cache itself. With Prescott, Intel has allowed the Trace Cache to encode a few more types of µops inside the Trace Cache – instead of forcing the processor to sequence them from microcode ROM (a much slower process).
If you recall back to the branch predictor section of this review we talked about Prescott’s indirect branch predictor – to go hand in hand with that improvement, µops that involve indirect calls can now be encoded in the Trace Cache. The Pentium 4 also has a software prefetch instruction that developers can use to instruct the processor to pull data into its cache before it appears in the normal execution. This prefetch instruction can now be encoded in the Trace Cache as well. Both of these Trace Cache enhancements are designed to reduce latencies as much as possible, once again, something that is necessary because of the incredible pipeline length of Prescott.
Finally we have Prescott’s L2 cache: a full 1MB cache. Prescott’s L2 cache has caught up with the Athlon 64 FX, which it needs as it has no on-die memory controller and thus needs larger caches to hide memory latencies as much as possible. Unfortunately, the larger cache comes at the sacrifice of access latency – it now takes longer to get to the data in Prescott’s cache than it did on Northwood.
| Cachemem L2 Latency | ScienceMark L2 Latency | |
|---|---|---|
Northwood |
16 cycles |
16 cycles |
Prescott |
23 cycles |
23 cycles |
Both Cachemem and ScienceMark agree on Prescott having a ~23 cycle L2 cache - a 44% increase in access latency over Northwood. The only way for Prescott's slower L2 cache to overcome this increase in latency is by running at higher clock speeds than Northwood.
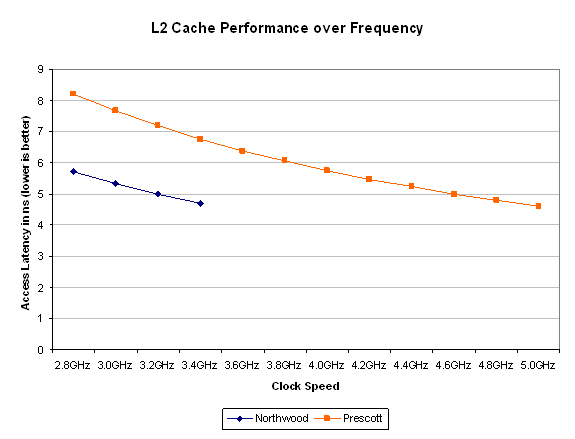
If our cache latency figures are correct, it will take a 4GHz Prescott to have a faster L2 cache than a 2.8GHz Northwood. It will take a 5GHz Prescott to match the latency of a 3.4GHz Northwood. Hopefully by then the added L2 cache size will be more useful as programs get larger, so we'd estimate that the Prescott's cache would begin to show an advantage around 4GHz.
Intel hasn’t changed any of the caching algorithms or the associativity of the L2 cache, so there are no tricks to reduce latency here – Prescott just has to pay the penalty.
For today’s applications, this increase in latency almost single handedly eats away any performance benefits that would be seen by the doubling of Prescott’s cache size. In the long run, as applications and the data they work on gets larger the cache size will begin to overshadow the increase in latency, but for now the L2 latency will do a good job of keeping Northwood faster than Prescott.








104 Comments
View All Comments
Jeff7181 - Thursday, March 11, 2004 - link
#98Yes, increasing the drive current means increasing the current that's flowing through the transistors, which does explain the heat increase.
watts = current x voltage
If we do the math, we can figure out how many amps the current Prescott runs on...
The 3.2 and 3.4 Ghz models have a spec of 103 watts, and the voltage is 1.385, so divide 103 by 1.385 and you get about 74.3 amps.
The 3.4 Ghz Northwood has a spec of 89 watts, and the voltage is 1.550, that's 57.4 amps.
That's a 30% increase in current, with only a 20% reduction in voltage. There's your extra heat. 103 watts vs. 89 watts... about a 16% increase in heat. We can take this a little further and say...
The Prescott at 3.4 Ghz produces 103 watts of heat, max. The Prescott at 3.0 Ghz produces 89 watts of heat, max. That means a 3.4 GHz Prescott runs on 74.3 amps, and the 3.0 GHz Prescott runs on 64.3 amps. So increasing the speed by 400 Mhz requires 10 more amps.
So a 3.6 GHz Prescott would run on 79.3 amps, which would create 109.8 watts...
and a 3.8 GHz Prescott would run on 84.3 amps, which would create 116.8 watts...
and a 4.0 GHz Prescott would run on 79.3 amps, which would create 123.7 watts...
and a 5.0 GHz Prescott would run on 104.3 amps, which would create 144.5 watts.
This is of course assuming they don't make core changes that require less current, and that they don't make core changes that require less voltage. It will be VERY interesting to see how they deal with this increased thermal output... considering it looks like the 2.8 Ghz Prescotts are maxing out at 50 degrees C with the retail heatsinks... and the thermal output of a 5 Ghz Prescott is about twice that, so, with the same heatsink as the 2.8... a 5 Ghz Prescott should run at about 100 degrees C, lol. 5 Ghz is a ways away though, 4 is much closer, but still, that's about a 75% increase in heat over the 2.8... so you're gonna be looking at full load temps around 80 degrees C unless Intel pulls something out of their hat.
On a side note...
Strained Silicon is supposed to reduce current leakage, and it does. But what I think Intel maybe didn't foresee is the 30% increase in current… or maybe they thought they could run on 1.0 – 1.2 volts.
See, voltage is electrical pressure, current is electrical volume. If you increase the volume of electricity moving through, but decrease the pressure, not as much current will leak. Think of it like a water hose. If you need a certain amount of water in a certain amount of time, you can increase the water pressure, and it will move faster so you'll have more water, but you might spring a leak in the hose... or you can just get a bigger hose and use less water pressure, which is basically what Intel did with Strained Silicon.
AMD’s approach with using SOI has been, dare I say, more successful. When you look at the specifications, the 3400+, 2.2 GHz has a maximum of 89 watts at 1.5 volts. When the PowerNow feature is used, it drops down to 2.0 GHz, and 1.4 volts, the wattage drops down to a cool 69 watts. When it drops down again to 1.8 GHz and 1.3 volts, the wattage drops to 50 watts. And finally when it drops down to 1.0 GHz and 1.1 volts, the wattage is a frigid 22 watts. Normally you would think that means for every 200 MHz increase, your wattage increases by 10 watts. However… the FX-53 runs at 2.4 GHz and it’s maximum wattage is also 89 watts. So it seems as though AMD may be estimating very high with these early processors if a 2.4 GHz chip has the same maximum heat dissipation of a 2.0 GHz chip. The only explanation I can come up with is that as they get more experience at manufacturing these chips, current leakage just gets better and better. We can only hope to see the same from Intel with the Prescott as they refine their Strained Silicon and 90nm process.
slashbinslashbash - Sunday, February 29, 2004 - link
Oh, and I think that the conspicuous silence by AT and everybody else on this subject only confirms that Intel indeed has something up its sleeve. They all say "Prescott has higher energy consumption" and "a larger transistor count" without even speculating as to what could create the wild disparity that we see with the transistor math.slashbinslashbash - Sunday, February 29, 2004 - link
#96: I'm no CPU designer, but it seems to me that the "add transistors to dissapate heat more evenly" argument doesn't make sense. Why not just have empty silicon if you need to spread things out? Adding actual transistors will also increase the amount of heat output, so the density of heat would stay the same.Lots of good speculation on Prescott/Yamhill here: http://www.chip-architect.com/
Regs - Tuesday, February 17, 2004 - link
Ah god, I'm sorry. This is suppose to be about the Prescott, and I just completely made a "fan boy" remark.Regs - Tuesday, February 17, 2004 - link
So it's pricey, runs hot, shows little improvement over the earlier northwoods, and did I mention pricey? The 3.4c is 415 dollars at newegg let alone what a 3.2 o 3.4E would cost.To us tech-gurus it comes down to common sense, but everybody knows marketing will always get the better of AMD. Intel well shovel "you're paying for the best performer", which is sadly true by a small margin if that for a huge price difference. And how people ignore the A64 completely just because 64-bit is not needed as of right now is just frustrating.
AMD made a remarkable achievement for making affordable technology while satisfying the need for higher performance.
TrogdorJW - Wednesday, February 4, 2004 - link
What does it mean to increase the transistor drive current by 10-20%? Does that mean that they need to run, say, 1.1 to 1.2 Amps instead of 1.0 Amps? (I know that's not what the processors use; I'm just using those numbers because they're easy to work with.) If that's correct, then it would certainly account for some of the heat increase.Initially, I read about strained silicon and thought that the idea was that it would take less power to run the chips at the same speed. The atoms are further apart, electrons flow more easily... doesn't that mean that strained silicon should make things run cooler? (I'll be honest - the electromagnetic physics course I had to take in college was *NOT* my favorite course. Talk about a HARD class....)
PrinceGaz - Wednesday, February 4, 2004 - link
I think Intel's heat problems are in part down to the Strained-Silicon technology they've introduced with the 90nm process as much as anything else. If as it says it increases the transistor drive-current by 10-20% then thats 10-20% more power and therefore heat being generated by each transistor for a given voltage.AMD however has opted to go for SOI now and that reduces leakage-current (waste) from the transistors, which means less heat is generated by them.
Intel is expected to introduce SOI with their 65nm process in 2005 and that should help reduce their heat problem a bit, and AMD will no doubt adopt Strained-Silicon around about the same time which will raise the amount of heat in their chips making them both about even again.
The difference now is that Intel implemented the heat-increasing performance improvement first, while AMD implemented the heat-decreasing one first.
TrogdorJW - Wednesday, February 4, 2004 - link
Aceshardware has some information on the transistors as well, on the bottom of page one of their review: http://www.aceshardware.com/read.jsp?id=60000315Of course, they also end up concluding the same things as me: the changes that Intel has really told us about don't seem like they should really be using up the 45 million added transistors. (A Northwood with 1 MB of L2 would be an 80 million transistor CPU.)
Intel did make numerous small changes to the processor, so I guess that it is possible that they could have used up all of the extra transistors. Who knows?
One other thing that isn't really being talked about anywhere is transistor density. In the past, shrinking the transistor size always ended up making chips run cooler. It appears that this may not be the case with 90nm processes and beyond. If Intel had stuck with a straight Northwood core and simply moved to 90nm, then the CPU die size would be something like half of what it currently is. So instead of 112 mm2, it would be 60 mm2 or something.
With all of the heat being generated in such a small area, maybe they had to add transistors and size just to spread out the heat dissipation? It's a weird argument, but it *could* be true. When AMD releases 90nm chips and we see how hot they get, we'll probably gain more insight into this. If AMD's chips run slightly hotter, then 90nm will have marked a transition to a new set of problems in processor die shrinks.
Pumpkinierre - Wednesday, February 4, 2004 - link
The only other explanation is that prescott is dual core. Really if the stages get smaller as the pipeline gets deeper then the transistor count should stay the same. So a dual core with double the cache should be 2xNorthwood= 110 million transistors- still 15 million unaccounted for and available for other things. Other people are saying that the 31 stage pipeline cant be right as the processor's power would be much weaker than the observed performance cf. equivalent (20 stage pipe) Northwood, despite the tweaks. It seems to perform well on the hyperthreaded enabled software and dual cpu may explain the slowness of the cache like duallies where one cpu has to keep tabs on the other. It also explains the heat for which a size reduction on a single core should augur less heat in contrast to Prescott's > 100 Watts.Pumpkinierre - Tuesday, February 3, 2004 - link
That's it. Prescott is already 64bit enabled. They have'nt bothered to switch them off as no intel mobo BIOS detects the 64bit extensions anyway. That's where the extra heat is coming from. I mean Northwood is ~130MM2 (55million transistors) and Prescott is close in size 112mm2 but 125million transistors - so approximately the same size but far greater transistor density so more heat. Even with the extra cache it should have been around 80 million and thus heat would have been at Northwood levels. The extra transistors still seem excessive for x86-64. So it might even be IA-64. Sckt 478 might not be pinned enough but 775 should do it. Here's my prediction then: ** 64bit WILL be available when Sckt LBGA 775 Prescott cpus come out in April with the new Grantsdale and Alderwood mobos **. And thats what is going on display in coupla of weeks time. How to check it, maybe write some assembler using X86-64 or IA-64 commands and see if they work.