The Last Bout of ‘03 – NVIDIA’s GeForce FX 5700 Ultra
by Derek Wilson on October 23, 2003 9:30 AM EST- Posted in
- GPUs
Architecture
There was a great deal of talk about why architectural decisions were made, but we will concern ourselves more with what exists rather than why this path was chosen. Every architecture will have its advantages and disadvantages, but understanding what lies beneath is a necessary part of the equation for developers to create efficient code for any architecture.
The first thing of note is NVIDIA's confirmation that 3dcenter.de did a very good job of wading through the patents that cover the NV3x architecture. We will be going into the block diagram of the shader/texture core in this description, but we won't be able to take quite as technical a look at the architecture as 3dcenter. Right now, we are more interested in bringing you the scoop on how the NV36 gets its speed.
For our architecture coverage, we will jump right into the block diagram of the Shader/Texture core on NV35:
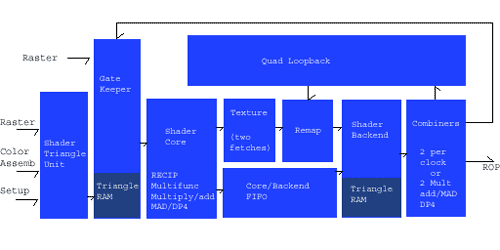
As we can see from this diagram, the architecture is very complex. The shader/texture core works by operating on "quads" at a time (in a SIMD manner). These quads enter the pipeline via the gatekeeper which handles managing which ones need to go through the pipe next. This includes quads that have come back for a second pass through the shader.
What happens in the center of this pipeline is dependent upon the shader code running or the texturing operations being done on the current set of quads. There are a certain few restrictions on what can be going on in here that go beyond simply the precision of the data. For instance, NV35 has a max of 32 registers (less if higher precision is used), the core texture unit is able to put (at most) two textures on a quad every clock cycle, the shader and combiners cannot all read the same register at the same time, along with limits on the number of triangles and quads that can be in flight at a time. These things have made it necessary for developers to pay more attention to what they are doing with their code than just writing code that produces the desired mathematic result. Of course, NVIDIA is going to try to make this less of a task through their compiler technology (which we will get to in a second).
Let us examine why the 5700 Ultra is able to pull out the performance increases we will be exploring shortly. Looking in the combiner stage of the block diagram, we can see that we are able to either have two combiners per clock or complete two math operations per clock. This was the same as NV31, with a very important exception: pre-NV35 architectures implement the combiner in fx12 (12 bit integer), NV35, NV36, and NV38 all have combiners that operate in full fp32 precision mode. This allows two more floating point operations to be done per clock cycle and is a very large factor in the increase in performance we have seen when we step up from NV30 to NV35 and from NV31 to NV36. In the end, the 5700 Ultra is a reflection of the performance delta between NV30 and NV38 for the midrange cards.
If you want to take a deeper look at this technology, the previously mentioned 3dcenter article is a good place to start. From here, we will touch on NVIDIA's Unified Compiler technology and explain how NVIDIA plans on making code run as efficiently as possible on their hardware with less hand optimization.








114 Comments
View All Comments
XPgeek - Tuesday, October 28, 2003 - link
Today I purchased this eVGA GF FX 5700 Ultra. i have no complaints of image quality. i am using the 52.16 betas, and Battlefiled 1942 and its XPacks run great, as do the rest of my games. The only issue i have is its length. in my case, the power connector nestles right up to one of my hard drives. but it does fit. barely.To re-itterate, this is a very nice card. no, i havent tested a 9600Pro / XT myself, but o well. no i dont work for AT or any other reviewing site. and no im not biased. i actually went to Best Buy to get a 9600 Pro, but saw the 5700U instead. so i wont get HL2 for free. o well, i'll just buy it when it comes out.
Anonymous User - Monday, October 27, 2003 - link
you misspelled comparing 110, doh! rofl you sux!Anonymous User - Monday, October 27, 2003 - link
106, if you read the review and don't get the impression that it's a rushed and shoddy job, well then you're just not a particularly smart or insightful person. which is ok, no one said you had to be. again, i'm camparing this to the old AT from 2,3,4 years ago. read some of the older reviews, and you'll see what i mean. or maybe you won't, whatever.Anonymous User - Monday, October 27, 2003 - link
that'd be earth 106. and you? thanks 108.Anonymous User - Monday, October 27, 2003 - link
#104 you mispelled the word fuck.Anonymous User - Monday, October 27, 2003 - link
...nvidia sucks.Anonymous User - Monday, October 27, 2003 - link
#104, you're officially an idiot. AT didn't spend "much time"? What planet are you living on.Anonymous User - Monday, October 27, 2003 - link
Firingsquad has a decent image quality article up today. You can draw your own conclusion from the screen shots.Anonymous User - Monday, October 27, 2003 - link
why does anandtech use these anonymous forums? it just encourages all of this nonsense. wtf are you yelling at eachother fanboy-this and fanboy-that? grow the fuk up.that said, i think anyone who has been a fan of AT (like myself) must be concerned with the recent nature of the graphics card reviews. i'm an owner of both nvidia and ati cards, and am too damn old to be a fanboy (maybe i'm a fanman). ATs recent reviews have been rubbish. I understand about trying to get info out in a timely fashion, but these reviews read like they were written the night before they were due (so to speak). i mean, if i were grading these as college papers or something, AT would get a D at best. i'm mostly comparing this to previous AT work, not other websites. i'm still an AT fan, i'm not goin anywhere.
for some reason, the problems seem to be with the graphic card reviews more than anythng else. maybe because this is the most competetive market, and they have to pump it out ASAP.. it just feels like they're not giving much time to their reviews.
the posters that have done the metrics on the review seem to have the right idea. specifically, it looks most like a tie to me, with 5700ultra being best in opengl situations, and 9600xt being best in other situations (ok, maybe that's not a tie :)
the "TKO" conclusion certainly is baffling.
Anonymous User - Sunday, October 26, 2003 - link
Stop acting like a fanboy #102, you look stupider by the second. Oh, and I'd like to see you try to keep my mouth shut. Ahhh, too bad, the little geek has no control over the situation. lol