AMD @ SC16: Radeon Open Compute Platform (ROCm) 1.3 Released, Boltzmann Comes to Fruition
by Ryan Smith on November 14, 2016 8:00 AM ESTKicking off this week is SC, the annual ACM/IEEE sponsored supercomputing conference in the United States. At this show last year, AMD announced the Boltzmann Initiative, their ambitious plan to overhaul their HPC software stack for GPUs. Recognizing that much of NVIDIA’s early and continued success has been due to the quality of the CUDA software ecosystem, AMD set out to create an ecosystem that could rival and even interact with CUDA, in hopes of closing the software gap between the two companies.
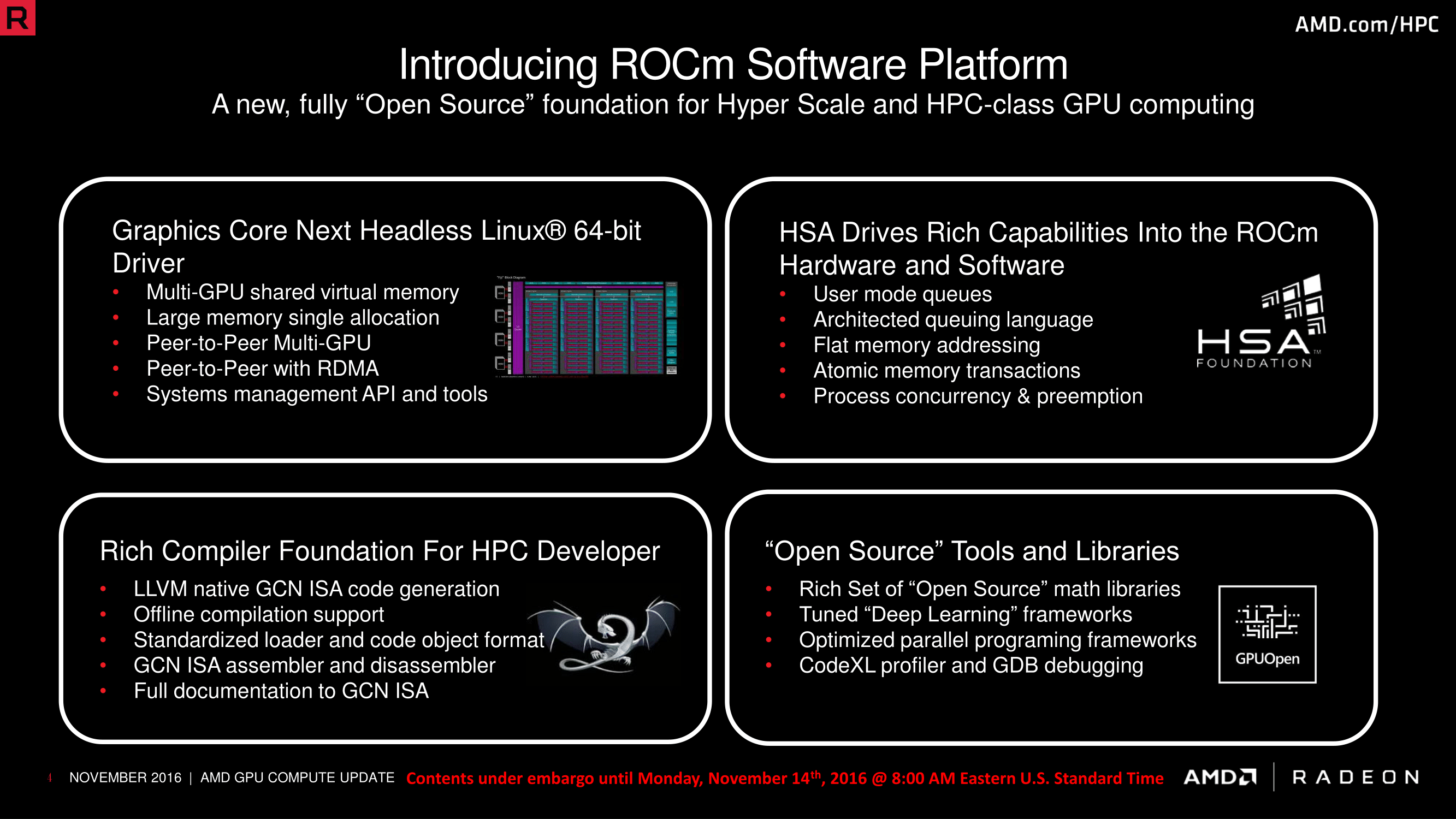
Now at SC16, the company is both updating participants on the current state of Boltzmann, along with providing the latest software update to the project. Now going under the name the Radeon Open Compute Platform – ROCm – AMD shipped the initial 1.0 version of the platform back in April of this year. That initial release however was, relative to the complete scope of Boltzmann, only the tip of the iceberg. A good deal of what AMD ultimately wanted to do with Boltzmann was not ready (or at least still in beta) with earlier ROCm releases, and it’s not a coincidence that ROCm 1.3, being announced today at the show, is much closer to completing the Boltzmann Initiative.
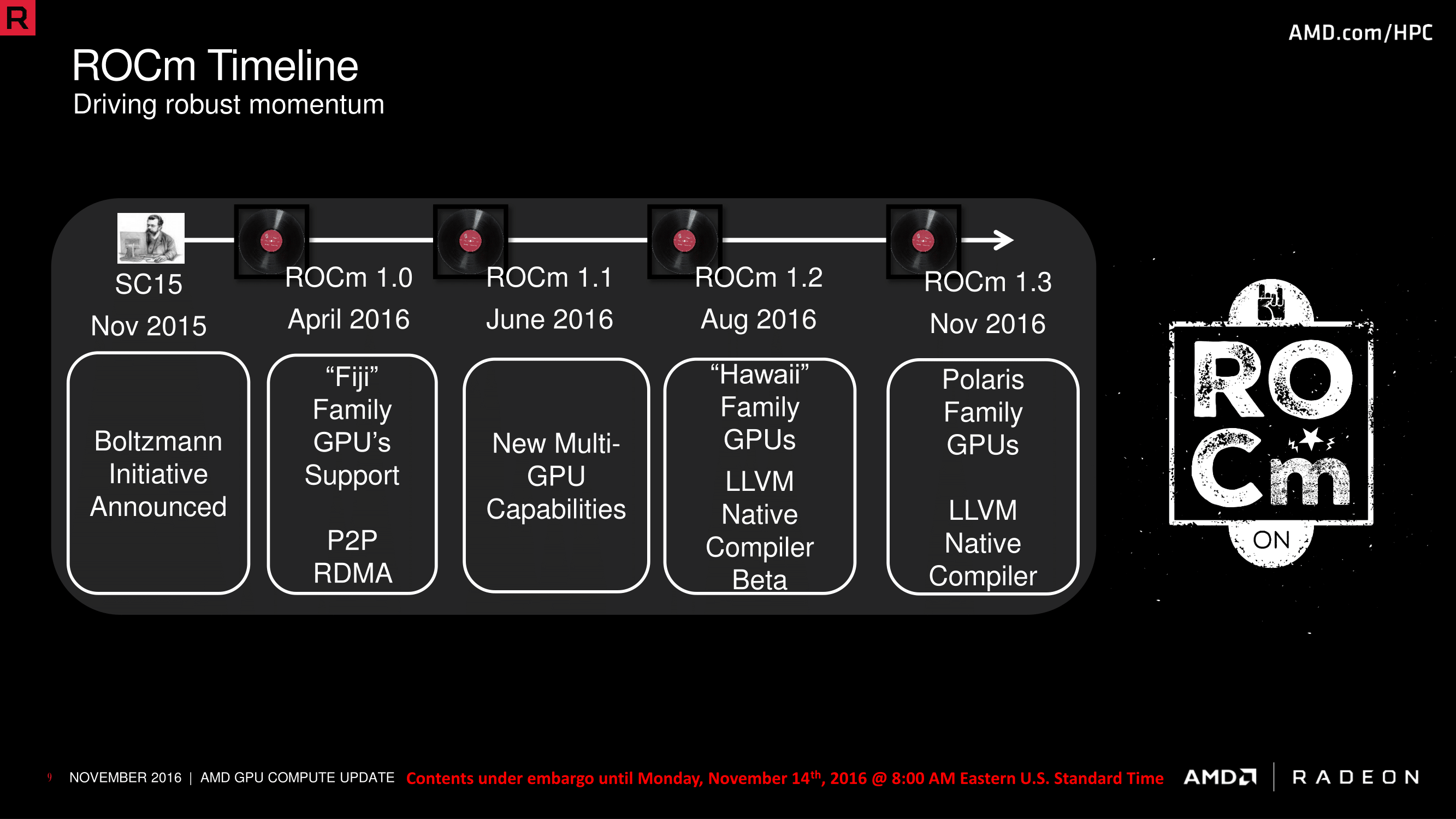
So where do things stand for AMD one year later with ROCm 1.3? Both the Heterogeneous Compute Compiler (HCC) and the Heterogeneous-compute Interface for Portability (HIP) have made significant progress. ROCm 1.3 introduces the shipping version of the native compiler, which as AMD previously discussed is based around LLVM. Of all of the parts of the Boltzmann plan, the native compiler is perhaps the most important part, as it and the associated driver/APIs/interfaces are the key to making HPC software work on AMD’s platform.

ROCm 1.3 also introduces several new features to the platform as a whole. Of particular note here, AMD has enabled support for 16bit floating point and integer formats within the platform. As regular readers may recall, AMD has offered native support for 16bit formats since GCN 1.3 (Tonga/Fiji), so this functionality is finally being exposed on ROCm. It should be noted however that this is not the same as packed 16bit formats, which allow for AMD’s 32bit ALUs to process two 16bit instructions at once, gaining FLOPS versus using 32bit instructions. Instead, the immediate purpose of this is to allow developers to leverage the space-saving aspects of 16bit data formats, reducing memory and register pressure by using smaller data types when lower precision is suitable, and cutting down on the number of instructions as well by avoiding unnecessary conversions.

Meanwhile, though AMD won’t comment on it, with the launch of the Playstation 4 Pro, we now know that AMD has an architecture supporting packed 16bit formats. Consequently, it’s widely expected that the next iteration of AMD’s dGPUs, Vega (incorporating GFX IP 9), will support these packed formats. In which case by exposing 16bit data types and instructions now, AMD is laying the groundwork for what will be following in 2017.
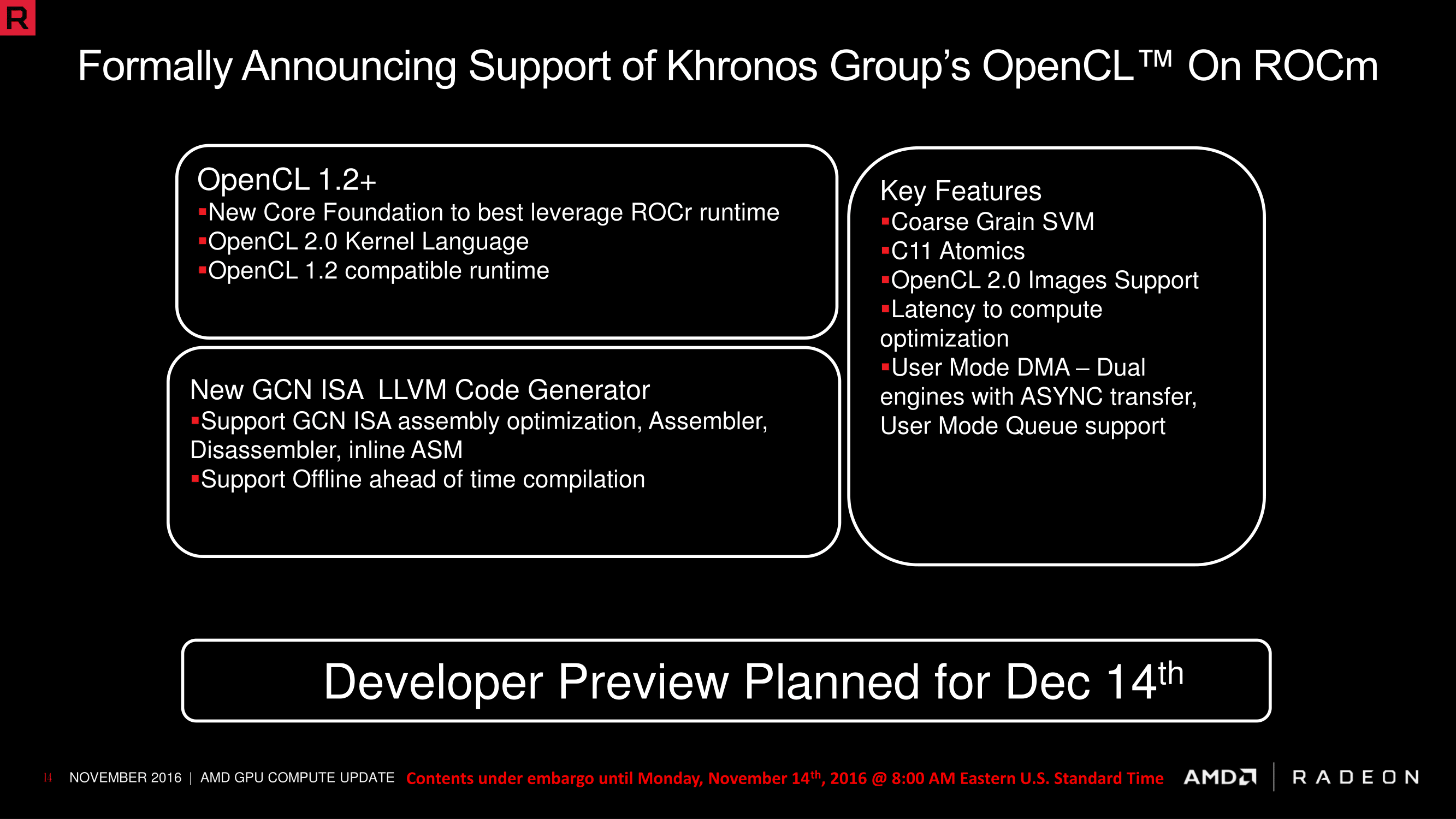
Moving on, AMD has now added “OpenCL 1.2+” support to ROCm. AMD’s history with OpenCL has been long and somewhat tortured – AMD’s bet on OpenCL has not been well rewarded – so this one caught my eye. The oddly named “1.2+” support reflects the fact that AMD isn’t implementing a full OpenCL 2.0 stack on top of ROCm, but rather they’re targeting existing OpenCL 1.x users. The end result is that ROCm’s OpenCL support is based around the 1.2 stack, but that it supports a select subset of the OpenCL 2.0 kernel language. The OpenCL runtime itself radically changed with 2.0, due to the introduction of SPIR-V, so how AMD is going about supporting OpenCL is important. They are essentially offering OpenCL 1.x users a souped up version of OpenCL 1.x, backporting several 2.0 features while retaining the 1.2 runtime. It’s a logical choice to offer a path forward to their existing OpenCL customers, and consistent with AMD’s previous sentiment on OpenCL. AMD’s future is in HCC and C++, not OpenCL.
AMD has made good progress on the HIP front as well. HIP itself as it 1.0, and to demonstrate their progress, AMD is touting how easy it was to port the CAFFE deep learning framework from CUDA to HIP. Using the HIPify Tools for automatic conversion, AMD was able to translate 99.6% of the code automatically. This is admittedly less than 100% – AMD has been upfront before that they may always be playing catch-up and won’t necessarily be able to replicate NVIDIA driver features 1-for-1 – but it’s significant progress. Ultimately AMD was able to finish the feature-complete port in less than 4 days for a 55K line project. And words can’t stress how important this is for AMD; they need CUDA interoperability to be able to break into what has become a $240mil/quarter business for NVIDIA, so successful ports with HIP are critical to becoming a viable alternative. Further adding to AMD’s success with CAFFE, the HIPified version of the framework is already faster than the OpenCL version, never mind the fact that the OpenCL version had to be created practically from scratch.
Meanwhile ROCm 1.3 also includes some new hardware functionality as well. AMD Polaris hardware is now supported, including both the Radeon RX 400 series and the Radeon Pro WX series. In the grand scheme of things AMD’s Polaris parts aren’t all that great for HPC due to a lack of total throughput – interestingly, I’m told the Radeon R9 Nano has been the big winner here due to its combination of throughput and best perf-per-watt for a Fiji-based part – and adding Polaris is more about opening the door to developers. Prior to this only Fiji and Hawaii GPUs were supported, so with the addition of Polaris support developers can develop and test against their local machines, and then deploy for production use on Hawaii/Fiji HPC gear.
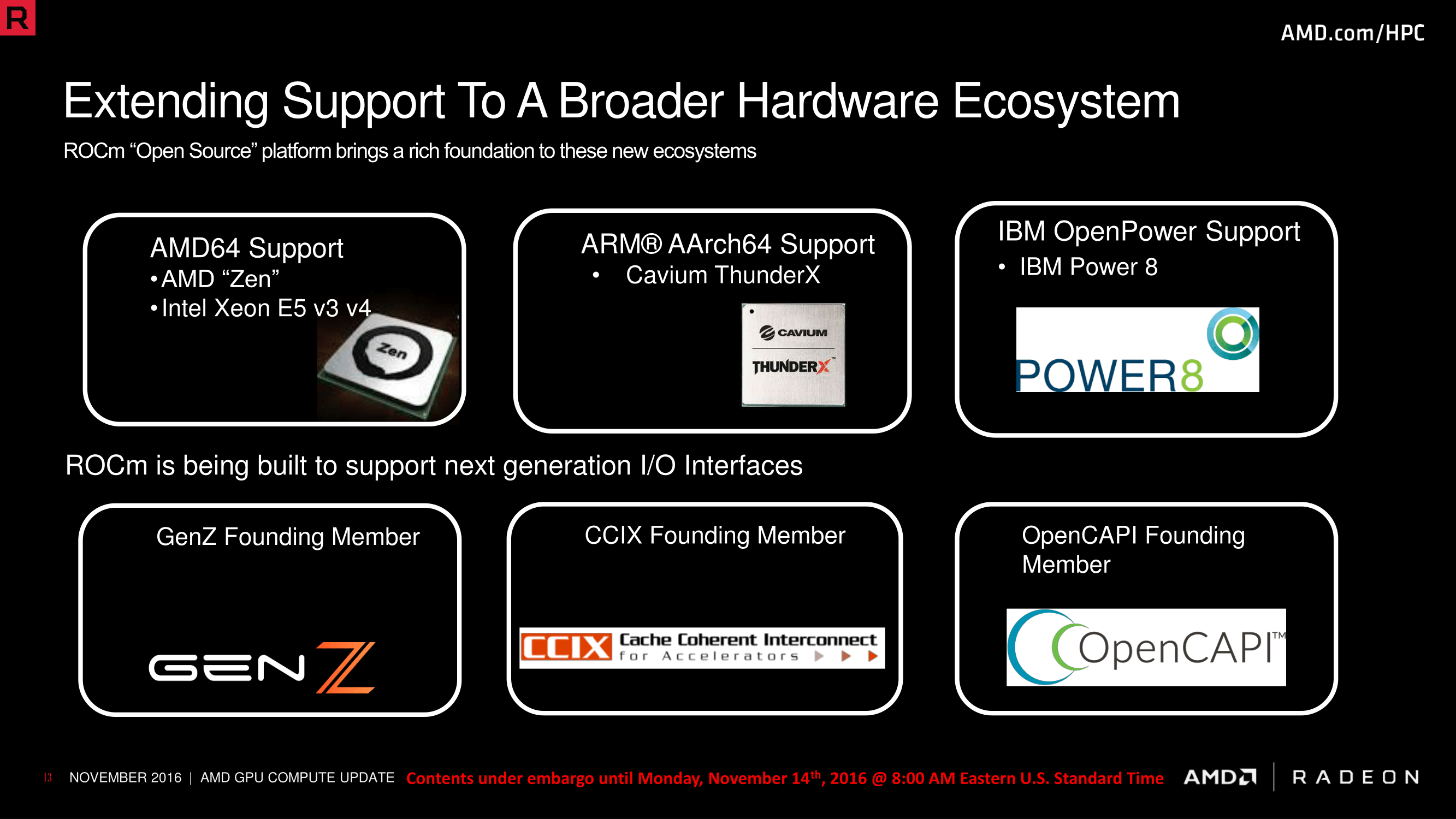
AMD is also using SC16 to further outline their platform support plans. Along with x86 support – including of course, Zen – AMD is also going to be supporting ARMv8 AArch64, and IBM POWER8. The former is an interesting choice since ARM in the server space has to date been mostly about microservers and other forms of high density computing, while adding POWER8 support is a logical step to take in order be able to play in the same hardware space that NVIDIA does as part of OpenPOWER’s “anyone but Intel” consortium. The addition of POWER8 support also offers an interesting sign of where AMD might go in the future; along with POWER8, they are also supporting the OpenCAPI interface that future POWER CPUs will use. Could this mean that AMD will offer HPC-class GPUs with more than just PCIe support in the future?
Wrapping things up, while ROCm 1.3 brings AMD much closer to fulfilling the original vision of the Boltzmann Initiative, the company still has some work to do and is offering a brief look at their future software plans. Now that AMD has the core platform sorted out, they’re going to be increasing their investment in major libraries and frameworks used by many HPC applications. This includes fundmental math libraries like BLAS and FFT, but also major frameworks like AMBER and the aforementioned CAFFE. Along with presenting a sane, developer-friendly language, one of CUDA’s other great strengths has been libraries/frameworks, so this is where AMD will be catching up next. And while AMD isn’t laying out any specific dates on the hardware or software side, the way the stars are aligning right now, I’m not going to be too surprised if they’ll be ready to finally fully tackle NVIDIA with the 1-2-3 punch of ROCm, optimized software libraries, and Vega GPU hardware by the time we’re reporting on SC17 at this time next year.






Source: AMD








11 Comments
View All Comments
OEMG - Monday, November 14, 2016 - link
So AMD's going full steam ahead with their rebel branding. Not sure how would that appeal to HPC types. dose quotes on "Open Source" and "Deep Learning" though...Anyway I'm sure many will be glad to see someone jumping in on better and more open tooling. There's also potential for other vendors and tinkerers to generate code for their ISA, even for games if that's the same one they use for their consumer cards.
nathanddrews - Monday, November 14, 2016 - link
Given the number of Che Guevara T-shirts I saw last time I was in the bay area, I think AMD's marketing team did their research quite well.ddriver - Monday, November 14, 2016 - link
So why is "open source" in quotation marks? Looks like "not really open source"?And on a side note, it is a good thing that AMD is making a lot of SOFTWARE improvements lately, however I kinda wish it was more than damage control due to the lack on the HARDWARE side.
prisonerX - Monday, November 14, 2016 - link
Going by their usage in the rest of the text, the quotes seem to emphasize the fact that the words refer to a proper noun. Their lawyers probably made them do it to stop some suit happy class action lawyer inferring all sorts of things from the words. The hazards of being a public company.The_Countess - Monday, November 14, 2016 - link
they are preparing their software stacks for the arrival of the new hardware (Vega en Zen) to make sure the new hardware comes out swinging when it's released.at least that's my optimistic reasoning.
wumpus - Monday, November 14, 2016 - link
"Support only non-packed float16"? All my understanding of OpenCL (mostly read with an eye on Nvidia capability, since that's what I currently have) implies that OpenCL tends to be highly biased toward aligned reads (meaning that non-packed shorts are weird, special cased oddities). Granted this is more a nvidia thing (nvidia can do reads to arbitrary registers of 32 aligned values, AMD reads 256 bytes and can assign them to arbitrary ports (although I'm sure they need to be aligned, but smaller values allow more choices)).It sounds harder to *not* support packed16 than to support it. This is certainly an exaggeration, but I doubt that fixing this is all that hard. I still have to wonder where all the money for this is coming from, AMD hasn't even been selling video cards lately.
Bigos - Monday, November 14, 2016 - link
Here "packed" means something different from C packed structs (structs without any padding). It is more akin SSE when you execute things on vectors of two 16-bit FPs instead of scalars (which are then executed natively as 64-vectors of 2-vectors, but that's beyond the point).It is most apparent from FP16 throughput, which is most often 2x FP32 throughput for packed FP16 and 1x FP32 throughput for unpacked.
ddriver - Monday, November 14, 2016 - link
aka scalar vs vectorhowever, "FP16 throughput, which is most often 2x FP32" - that's not really true, in many instances FP16 is actually slower than FP32, believe it or not, which begs the question, why even bother, when you can do as much and even more in higher precision. And several uarchs don't, they promote it to FP32 implicitly.
ddriver - Monday, November 14, 2016 - link
On a gtx 1080 FP16 is actually twice as slow as the already severely crippled FP64. "Stupid" would be a compliment to anyone running FP16 number crunching on that hardware.TeXWiller - Monday, November 14, 2016 - link
There is nothing particularly surprising with the ARM support. ARM architecture with the coming new vector extensions will become a part of the European and Japanese exascale efforts.