Arteris Announces Ncore Cache-Coherent Interconnect
by Andrei Frumusanu on May 24, 2016 9:00 AM EST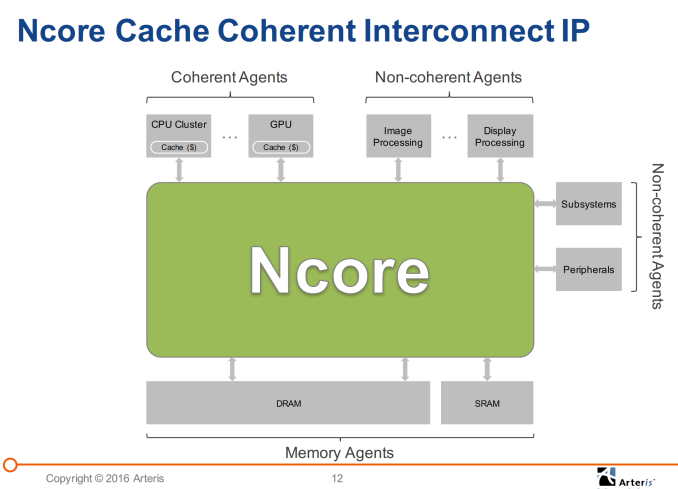
Arteris is a little mentioned company which we haven't had the opportunity to cover in the past, yet they provide IP for one of the most important parts of a modern SoCs: the various internal interconnects. Today's system-on-chips are compromised of dozens of different subsystems harbouring different kind of IP blocks which each have their specialised functions and purpose. Last year's deep dive review of the Exynos 7420 was an attempt at trying to show an example on how some of these subsystems work in union to enable various functions of today's smartphones.
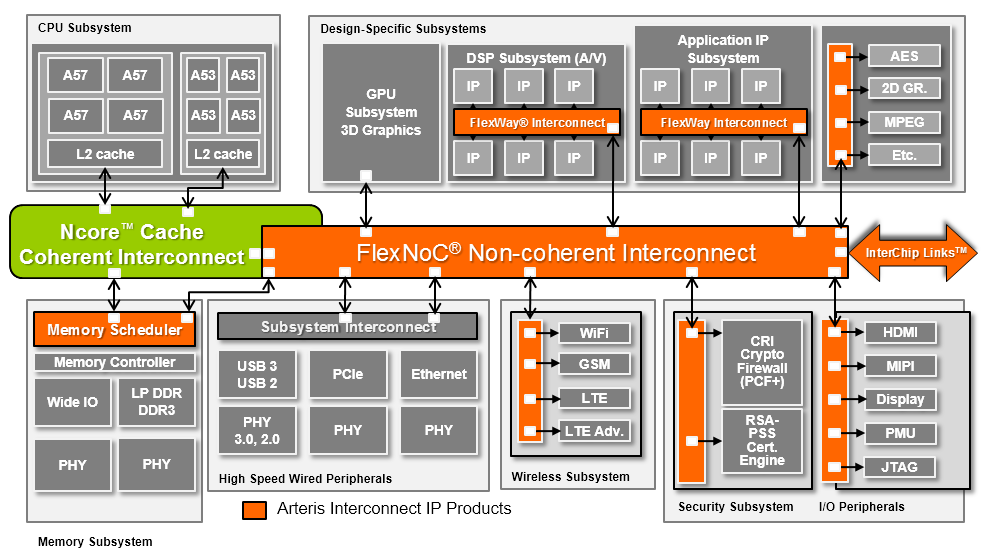
The section where I talk about the SoC's internal busses is one of the more interesting parts. Yet, at the same time, it's also one of the parts where we have the least amount of information on, as the interconnect is one of the IP blocks which remains largely transparent to the overlying SoC functionality and software. In fact, it's Arteris IP FlexNoC IP which powers most of these SoCs, at least for vendors like Samsung, HiSilicon, LG in the mobile space and many others such as MobilEye, Freescale or Renesas in sectors such as the automotive SoC space.
In recent years in particular we've been talking a lot about cache-coherency and the interconnects which enable this functionality in mobile SoCs. ARM has been especially at the forefront of the topic as big.LITTLE heterogeneous CPU systems rely on cache-coherency to enable all processors in a system to work simultaneously, so of course we've had some extensive coverage talking about the by now familiar ARM CCI products.
As heterogeneous systems become the norm and customer increasingly demand the functionality, it's a natural progression to try to expand the IP offerings to also offer a cache-coherent interconnect able to provide the same functionality as ARM's CCI (Cache Coherent Interconnect) and CCN (Cache Coherent Network) products.
Today's announcement revolves around Arteris' new Ncore Cache Coherent Interconnect. Arteris is in an interesting position here as they already have extensive experience with interconnects, so we're curious as to how their new IP is able to differentiate from ARM's offerings. Differentation is of course the key word here as this year in particular we've seen vendors start deploying their in-house designs, such as Samsung with their SCI (Samsung Coherent Interconnect) in the Exynos 8890 or MediaTek with the MCSI (MediaTek Coherent System Interconnect) in the Helio X20.

Ncore builds on the FlexNoC interconnect IP in that it relies on a lightweight switch-based fabric. In contrast, ARM's CCI is based on a crossbar architecture. One of the advantages of the former lies in the physical implementation of the interconnect as the packet-based network is able to use far less wires than an AXI-based crossbar. An 128-bit bidirectional AXI interface which is what we typically find requires 408 physical wires while the same data-width based on Arteris' internal protocol requires less at only 300 to 362 wires (depending on configuration).
The advantage of Ncore being largely based on FlexNoC means that vendors have large flexibility in terms of implementation configuration. When a vendor licenses Ncore, they also use a FlexNoC license. One example which Arteris presented is that the vendor can then implement a coherent interconnect "overlaying" a non-coherent interconnect, with the other possibility being to implement the two as two separate entities. It wasn't exactly clear what the exact differences between the two options are, but we're likely talking about actual physical layout of the interconnects.
Physical layout is definitely one of the aspects that Arteris seems to be confident on being able to differentiate from the competition as they promise better layout and routing flexibility when compared to other solutions. This allows vendors to achieve better overall SoC block layout and possibly enable gains in performance, power and most importantly, die area.
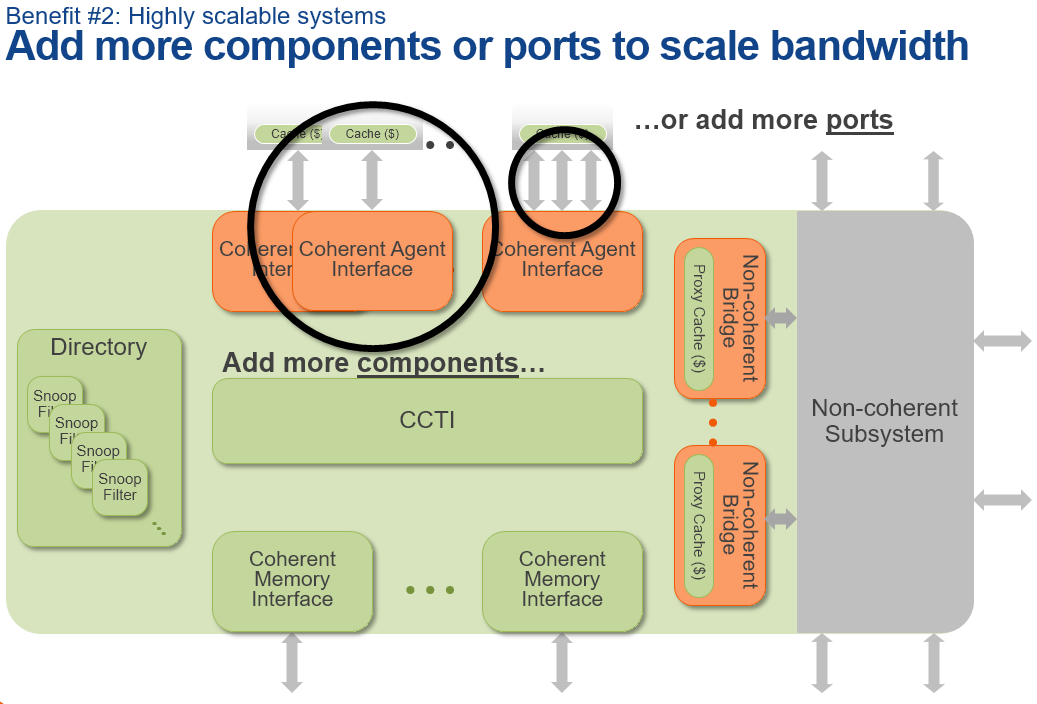
Ncore's components are composed of a few key blocks: On the interface side we have CAIs (Coherent Agent Interfaces) which connect to the desired IP block (agent) via "ports". Ports here refers to whatever interfaces the connecting agent offers, generally we'll be talking about AMBA ACE interfaces. For use-cases which were're familiar with and taking for an example ARM's CPU or GPU products this means 128-bit ACE interfaces. I asked how one would implement high-bandwidth agents such as ARM's Mimir GPU which can offer up to 4 ACE interfaces to the interconnect, and the solution is to simply use 4 ports to a single CAI. Multiported CAIs scale bandwidth into the CCTI with no associated bandwidth loss.
CAIs are offered in different classes depending on the supported agent protocol which can be ACE, CHI or any third-party protocols. There is a translation layer/wrapper which does the conversion from the external to the internal coherency. This seems very interesting as it allows Ncore large flexibility in terms of interoperability with other vendor's coherent systems, while for example ARM's product offerings are specialized and segregated into different categories depending on if they serve AMBA 4 ACE (CCI) or AMBA 5 CHI (CCN). CAIs are able to operate on their own clock and voltage plane for power management, and usually vendors chose to tie them to the clock and voltage plane of the connected agent / IP block.
The central CCTI (Cache Coherent Transport Interconnect)'s transport layer is based on a simplified FlexNoC which utilizes proprietary protocols and interfaces. Again, this is a switch based architecture with fully configurable topology based on the customer's needs. It's actually hard to talk about bandwidth achieved by the interconnect as Arteris claims that the internal data-widths are fully configurable by the customer in 64, 128, 256 and in the future 512b widths, but they assured that the IP has no issues to scale up to satisfly the bandwidth requirements of fully configured CAIs.
The Coherent Memory Interfaces, or CMI's, are relatively self-explanatory. CMIs act as master interfaces on the interconnect. CMIs are also able to employ multiple ports in order to increase the memory bandwidth or to allow for flexibility between frequency and interface data widths.
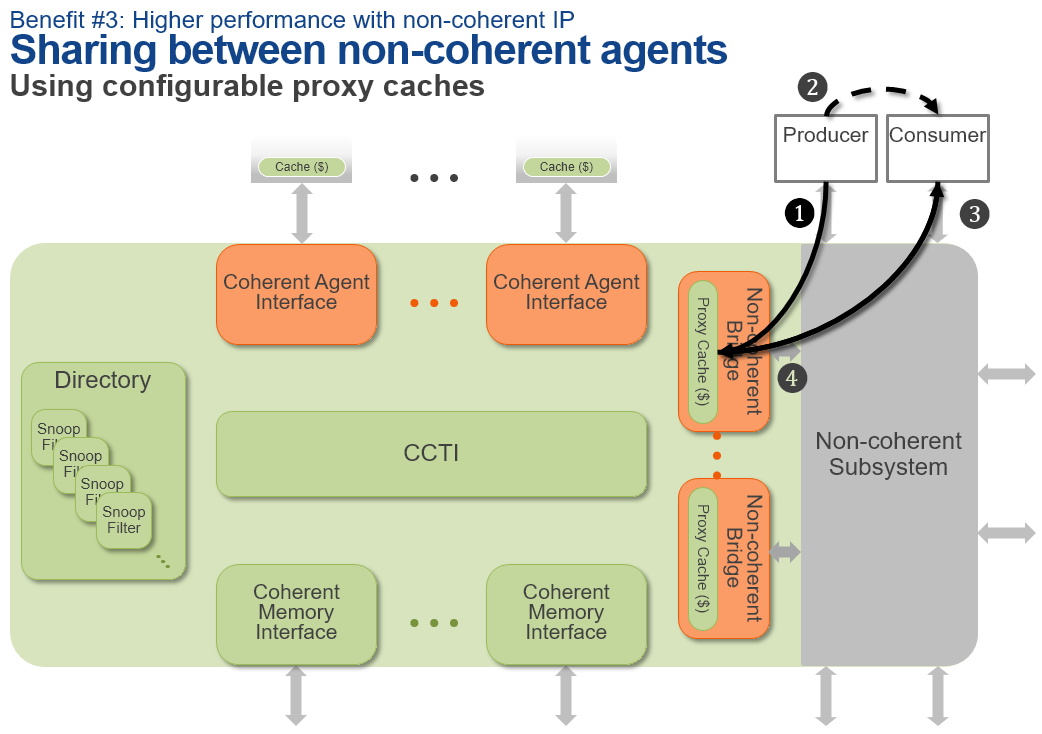
NCB's are Non-Coherent Bridges which are used to interface between the coherent system and non-coherent systems or agents. NCBs are able to convert non-coherent transations into IO-coherent transations. Non-coherent traffic can be aggregated, triaged and vectored into one or multiple NCBs from non-coherent interconnect, essentially allowing for traffic shaping.
A unique feature of Ncore's NCB's are the ability for them to employ so-called proxy-caches which are able to provide pre-fetch, write-merging and ordering functionality. The caches are configurable to up to 1MB per NCB in 16-way associative spans. Arteris claims that this can be useful to offer better interoperability between blocks which can have different sizes and also offer power benefits for transactions which then no longer have to find their way all the way to DRAM. The most interesting aspect of the latter point also includes communication between two non-coherent agents which allows for a total bypass of system memory. Write-gathering can improve power by reducing the amount of main memory accesses.
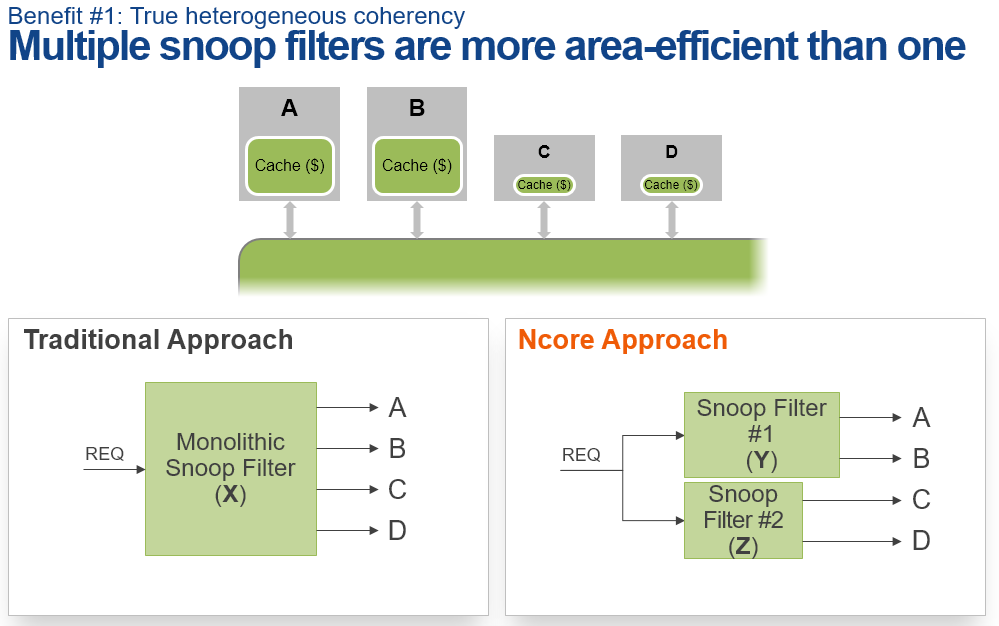
Finally we can talk about Ncore's approach to snoop filters. First of all, Ncore supports directory-based snoop filters. We've talked about and explained the importance of snoop filters in coherent interconnects when ARM introduced the CCI-500 and CCI-550. Arteris' implementation differentiates in that it makes use of multiple smaller snoop filters in place of a larger monolithic filter.
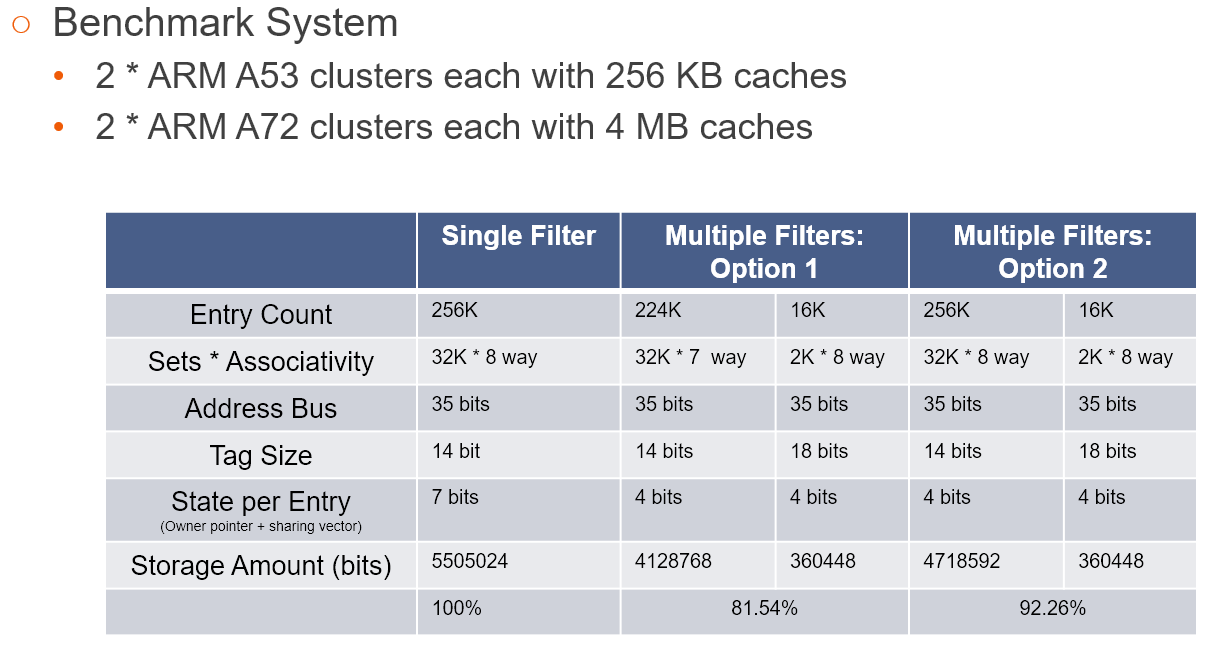
Advantages of the multiple snoop filter approach lies in the reduction of die size thanks to a reduced need for storage, or in other words, SRAM, on the part of the the physical implementation. In an example detailing a 2x A72 with 4MB and an 2x A53 with 256KB cache system the advantage is around 8% if you keep the same set-associativity as the single filter option. The directory is also able to have multiple ports allowing for higher bandwidth which could improve performance of the system.
The same CPU configuration with one agent for an IO coherent GPU, one NCB with 16KB proxy cache on a TSMC 16FF+ process with SVT (standard transistor Vthreshold) libraries running at 1GHz target frequency is said to take up approximately 1.1mm². The metric doesn't include any non-coherent interconnect and is subject to a SoC's floorplan and physical design constraints.
| Arteris Ncore Configuration Capabilities | ||||||
| Fully Coherent CAIs |
IO Coherent CAIs |
NCBs |
CMIs |
Directory Ports |
Snoop Filters |
|
| Version 1.5 (Relased) | 1-8 | 0-4 | 0-4 | 1-6 | 1-4 | 1-6 |
| Architecture Goals | 1-64 | 0-32 | 0-32 | 1-32 | 1-32 | 1-? |
Arteris sees Ncore continue to evolve in terms of its architectural capabilities with each new release. The latest version 1.5 of the IP which is being released this month is able to scale up to 8 fully coherent CAIs, 4 IO coherent CAIs, 4 NCBs and 6 CMIs with up to 6 snoop filters and 4 ports to the directory.
Overall Arteris' Ncore Cache Coherent Interconnect continues FlexNoC's design philosophy by enabling vendors able to use a scalable and configurable solution which offers both high performance and low power at a high area efficiency. Ncore's main advantage seems to be on the physical implementation side as Arteris promises much better layout flexibility and area efficiency. Today's SoC interconnects can take up large amounts of a chip's overall die area and recent manufacturing nodes have shown that wire scaling hasn't kept up with transistor scaling, making this an increasingly important design property that vendors have to account for, and Ncore seems to address these needs.








9 Comments
View All Comments
Pissedoffyouth - Tuesday, May 24, 2016 - link
Welcome back AndreiAndrei Frumusanu - Tuesday, May 24, 2016 - link
I was never gone... just very busy with some large articles.plopke - Tuesday, May 24, 2016 - link
oooe the teasing !xakor - Tuesday, May 24, 2016 - link
You incorrectly typed the mischosen word "comprised". I'd go for "composed", it's a much better word and has strong connections with design.Yojimbo - Tuesday, May 24, 2016 - link
From merriam-webster.com:"comprise
transitive verb
1
: to include especially within a particular scope <civilization as Lenin used the term would then certainly have comprised the changes that are now associated in our minds with “developed” rather than “developing” states — Times Literary Supplement>
2
: to be made up of <a vast installation, comprising fifty buildings — Jane Jacobs>
3
: compose, constitute <a misconception as to what comprises a literary generation — William Styron> <about 8 percent of our military forces are comprised of women — Jimmy Carter>
Although it has been in use since the late 18th century, sense 3 is still attacked as wrong. Why it has been singled out is not clear, but until comparatively recent times it was found chiefly in scientific or technical writing rather than belles lettres. Our current evidence shows a slight shift in usage: sense 3 is somewhat more frequent in recent literary use than the earlier senses. You should be aware, however, that if you use sense 3 you may be subject to criticism for doing so, and you may want to choose a safer synonym such as compose or make up."
I can guess why it's been singled out. People who spend their time thinking about such things probably find it more elegant to have one word exclusively used in one direction and another used in the opposing direction. In that way, it's similar to the 'further' and 'farther' push that was going on some years back. But since English doesn't have a language arbiter and we go by authoritative usage, it's not really correct to say the word 'comprised' in place of 'composed' in the article (it's been changed to 'composed' now, apparently) is "mischosen", as 'comprised' has apparently been used that way in scientific and technical writing for over 200 years.
Meteor2 - Tuesday, May 24, 2016 - link
I've learnt something new today.BurntMyBacon - Wednesday, May 25, 2016 - link
Good Stuff :')webdoctors - Tuesday, May 24, 2016 - link
This comment in no way implies any specific issue or deficiency with this product/manufacturer/review/article.Its annoying when companies pitch their IP as this perfect macro block that will just drop in and seamlessly work with your product. Than the MBA guys close the deal and force the internal engineers to try to integrate the POS with the rest of the system, increasing risk to schedule, costs, performance and power. Ironic because those are all the very things they're using as the reasons for not doing these things in house.
You get the IP and than you find out the assumptions used for the pretty slides are bogus, they used benchmarks with hilarious configurations. You dig deeper and find out the architecture can only handle X number of requests outstanding, or they can't handle responses out of order, or they consider misses after hits to also be hits even though the data has been prefetched, or the coherence algorithm serializes atomic instructions that should've been parallizable or requires serialization of request lookups to ensure proper ordering.
Even when the architecture is fine on paper, you find out they won't have a simulator for you to use until the quarter before your project tapes out, and you won't get the actual block the month until tapeout! Than once you get the block, you see they messed up and its not passing the basic verif checks and when you go back to get them to fix it, they're dragging their heels because they're trying to sell their next generation to the next set of suckers.
But I'm sure this advertisement will be different. /s
zirk65 - Wednesday, May 25, 2016 - link
The part about things looking fine on paper, but necessary details being missing made me think of how similar things are from the Warranty Repair perspective. Here is a short summary of my experience when a new Vendor is added to the 25+ already serviced by a couple of Technicians:Management sign Service Agreement with Vendor. Vendor supply barebones docs/software/tools. Technicians notice 16 devices have appeared for repair, all marked URGENT.
Barebone docs don't cover any of the devices. Emails to Vendor for docs gets reply next day saying already provided. More emails to/from, incoming calls reiterating URGENT status, "Skype" training days, conference calls, meetings, Vendor then supplies part of necessary docs/software, emails again, more "Skype" training, angry incoming calls, Vendor supplies more docs/software, repair completed.
Then of course, there are the other 25+ Vendors devices being repaired while the above is taking place.
It would have been great to be involved during the proposal stage with Vendors, but then it would take away time from Technicians in the short term.