The IBM POWER8 Review: Challenging the Intel Xeon
by Johan De Gelas on November 6, 2015 8:00 AM EST- Posted in
- IT Computing
- CPUs
- Enterprise
- Enterprise CPUs
- IBM
- POWER
- POWER8
"Per Core" Integer Performance: 7-Zip
The profile of a compression algorithm is somewhat similar to many server workloads: it can be hard to extract instruction level parallelism (ILP) and it's sensitive to memory parallelism and latency. The instruction mix is a bit different, but it's still somewhat similar to many server workloads. Testing single threaded is also a great way to check how well the turbo boost feature works in a CPU.
We ran this benchmark on the POWER8 a few months ago, but there are several reasons to do this again. First of all, we can now use GCC 4.9.2, which has specific support for POWER8 (-mcpu=power8). It is good to note that POWER8 is not a radical new design compared to POWER7. So we only expect modest gains from the compiler.
Secondly, last time we ran on top of PowerKVM, inside a virtual machine. Although that should not make a big difference either - as the benchmark runs almost completely (99%) in user modus and thus runs at 100% - it's still worthwhle to rule out the influence of the virtual machine.
So we recompiled the 7-Zip source code on every machine with the -O3 optimization with GCC 4.9.2.
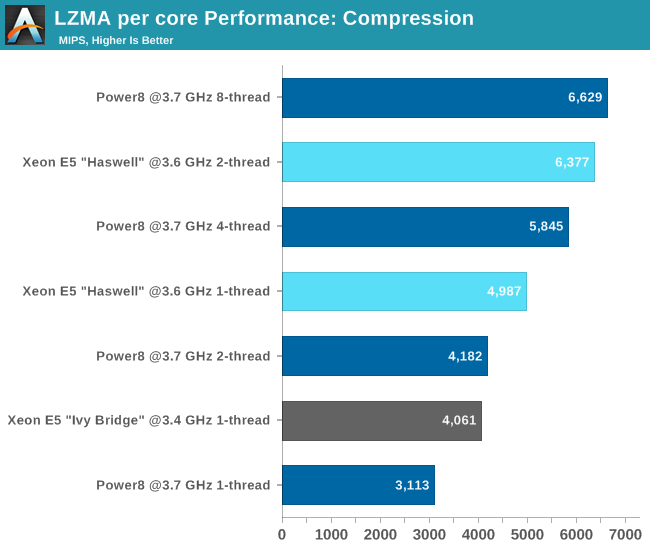
It is important to note that Intel is extremely aggressive with Turbo-boost on the Xeon E5-2699v3. Running code on one core causes the 2.3 GHz Xeon to boost to 3.6 GHz. As a result, the typical clockspeed advantage of the POWER8 was minimized to a measly 90 MHz, with the POWER8 CPUs boosting from 3.425 GHz to 3.690 GHz.
We found that the POWER8 needs more than one thread to deliver good performance: with one thread we only achieve 62% of the performance of a Haswell core at the same speed. Using the mcpu=power8 compiler flag did little more than boost the performance by 1-3%, which is within the margin of error of this benchmark. So your (occassional?) single threaded code will fare badly on POWER8.
Once you fire off 8 threads however, the POWER8 CPU outperforms the hyperthreaded Haswell core slightly (4%).
How about decompression which is even more (IPC) unfriendly to our brainiacs?
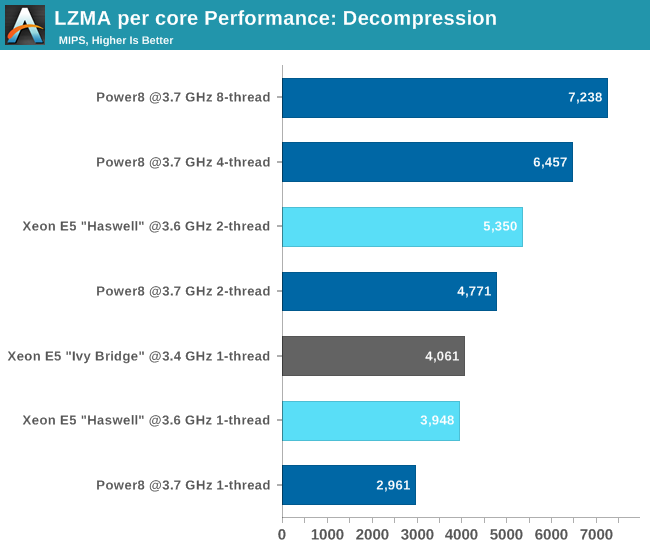
With a single thread, performance of a POWER8 core is about 25% slower than a Haswell core. The Haswell core is still clearly better in extracting Instruction Level Parallelism out of this ILP-unfriendly code. However, let there be no mistake about the integer crunching power of POWER8: it delivers 35% higher performance than the hyperthreaded Xeon E5, core per core, clock per clock (give or take a few MHz).
Compression depends more on the datacache and OoO engine. It is remarkable that the Haswell core with its smaller L1-datacache does a lot better than the POWER8. The many unpredictable branches of the decompression code underutilize these very wide modern cores, and as a result the SMT-8 capable POWER8 outperforms the dual-threaded (SMT-2) Haswell. Notice that running two threads instead one thread on the POWER8 offers 61% better performance. Running 8 threads delivers 2.4x higher performance, a clear indication that the POWER8 CPU has a very wide integer execution engine, but can only deliver if enough threads are active.








146 Comments
View All Comments
hissatsu - Friday, November 6, 2015 - link
You might want to look more closely. Thought it's a bit blurry, I'm almost certain that's the 80+ Platinum logo, which has no color.DanNeely - Friday, November 6, 2015 - link
That's possible; it looks like there's something at the bottom of the logo. Google image search shows 80+ platinum as a lighter silver/gray than 80+ silver; white is only the original standard.Shezal - Friday, November 6, 2015 - link
Just look up the part number. It's a Platinum :)The12pAc - Thursday, November 19, 2015 - link
I have a S814, it's Platinum.johnnycanadian - Friday, November 6, 2015 - link
Oh yum! THIS is what I still love about AT: non-mainstream previews / reviews. REALLY looking forward to more like this. I only wish SGI still built workstation-level machines. :-(mapesdhs - Tuesday, November 10, 2015 - link
Indeed, but it'd need a hefty change in direction at SGI to get back into workstations again, so very unlikely for the forseeable future. They certainly have the required base tech (NUMALink6, MPI offload, etc.), namely lots of sockets/cores/RAM coupled with GPUs for really heavy tasks (big data, GIS, medical, etc.), ie. a theoretical scalable, shared-memory workstation. But the market isn't interested in advanced performance solutions like this atm, and the margin on standard 2/4-socket systems isn't worthwhile, it'd be much cheaper to buy a generic Dell or HP (plus, it's only above this no. of sockets that their own unique tech comes into play). Pity, as the equivalent of a UV 30/300 workstation would be sweet (if expensive), though for virtually all of the tasks discussed in this article, shared memory tech isn't relevant anyway. The notion of connectable, scalable, shared memory workstations based on NV gfx, PCIe and newer multi-core MIPS CPUs was apparently brought up at SGI way back before the Rackable merger, but didn't go anywhere (not viable given the financial situation at the time). It's a neat concept, eg. imagine being able to connect two or more separate ordinary 2/4-socket XEON workstations together (each fitted with, say, a couple of M6000s) to form a single combined system with one OS instance and resources pool, allowing users to combine & split setups as required to match workloads, but it's a notion whose time has not yet come.
Of course, what's missing entirely is the notion of advanced but costly custom gfx, but again there's no market for that atm either, at least not publicly. Maybe behind the scenes NV makes custom stuff the way SGI used to for relevant customers (DoD, Lockheed, etc.), but SGI's products always had some kind of commercially available equivalent from which the custom builds were derived (IRx gfx), whereas atm there's no such thing as a Quadro with 30000 cores and 100GB RAM that costs $50K and slides into more than one PCIe slot which anyone can buy if they have the moolah. :D
Most of all though, even if the demand existed and the tech could be built, it'd never work unless SGI stopped using its pricing-is-secret reseller sales model. They should have adopted a direct sales setup long ago, order on the site, pricing configurator, etc., but that never happened, even though the lack of such an option killed a lot of sales. Less of an issue with the sort of products they sell atm, but a better sales model would be essential if they were to ever try to sell workstations again, and that'd need a huge PR/sales management clearout to be viable.
Pity IBM couldn't pay NV to make custom gfx, that'd be interesting, but then IBM quit the workstation market aswell.
Ian.
mostlyharmless - Friday, November 6, 2015 - link
"There is definitely a market for such hugely expensive and robust server systems as high end RISC machines are good for about 50.000 servers. "Rounding error?
DanNeely - Friday, November 6, 2015 - link
50k clients would be my guess.FunBunny2 - Friday, November 6, 2015 - link
(dot) versus (comma) most likely. Euro centric versus 'Murcan centric.DanNeely - Friday, November 6, 2015 - link
If that was the case, a plain 50 would be much more appropriate.