The IBM POWER8 Review: Challenging the Intel Xeon
by Johan De Gelas on November 6, 2015 8:00 AM EST- Posted in
- IT Computing
- CPUs
- Enterprise
- Enterprise CPUs
- IBM
- POWER
- POWER8
"Per Core" Integer Performance: 7-Zip
The profile of a compression algorithm is somewhat similar to many server workloads: it can be hard to extract instruction level parallelism (ILP) and it's sensitive to memory parallelism and latency. The instruction mix is a bit different, but it's still somewhat similar to many server workloads. Testing single threaded is also a great way to check how well the turbo boost feature works in a CPU.
We ran this benchmark on the POWER8 a few months ago, but there are several reasons to do this again. First of all, we can now use GCC 4.9.2, which has specific support for POWER8 (-mcpu=power8). It is good to note that POWER8 is not a radical new design compared to POWER7. So we only expect modest gains from the compiler.
Secondly, last time we ran on top of PowerKVM, inside a virtual machine. Although that should not make a big difference either - as the benchmark runs almost completely (99%) in user modus and thus runs at 100% - it's still worthwhle to rule out the influence of the virtual machine.
So we recompiled the 7-Zip source code on every machine with the -O3 optimization with GCC 4.9.2.
It is important to note that Intel is extremely aggressive with Turbo-boost on the Xeon E5-2699v3. Running code on one core causes the 2.3 GHz Xeon to boost to 3.6 GHz. As a result, the typical clockspeed advantage of the POWER8 was minimized to a measly 90 MHz, with the POWER8 CPUs boosting from 3.425 GHz to 3.690 GHz.
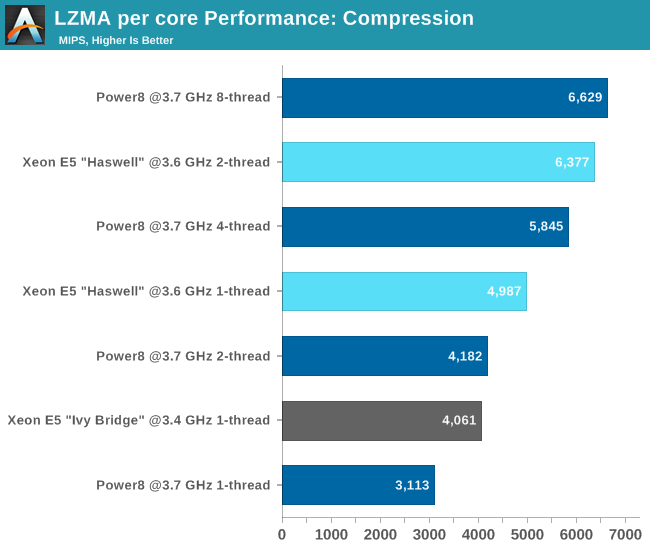
We found that the POWER8 needs more than one thread to deliver good performance: with one thread we only achieve 62% of the performance of a Haswell core at the same speed. Using the mcpu=power8 compiler flag did little more than boost the performance by 1-3%, which is within the margin of error of this benchmark. So your (occassional?) single threaded code will fare badly on POWER8.
Once you fire off 8 threads however, the POWER8 CPU outperforms the hyperthreaded Haswell core slightly (4%).
How about decompression which is even more (IPC) unfriendly to our brainiacs?
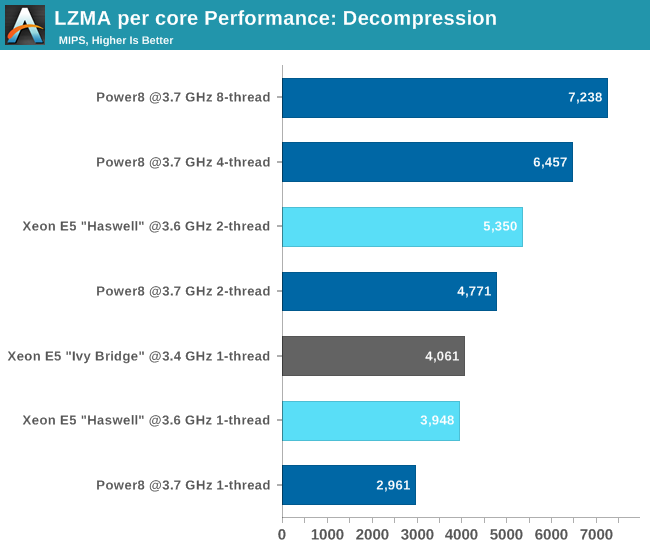
With a single thread, performance of a POWER8 core is about 25% slower than a Haswell core. The Haswell core is still clearly better in extracting Instruction Level Parallelism out of this ILP-unfriendly code. However, let there be no mistake about the integer crunching power of POWER8: it delivers 35% higher performance than the hyperthreaded Xeon E5, core per core, clock per clock (give or take a few MHz).
Compression depends more on the datacache and OoO engine. It is remarkable that the Haswell core with its smaller L1-datacache does a lot better than the POWER8. The many unpredictable branches of the decompression code underutilize these very wide modern cores, and as a result the SMT-8 capable POWER8 outperforms the dual-threaded (SMT-2) Haswell. Notice that running two threads instead one thread on the POWER8 offers 61% better performance. Running 8 threads delivers 2.4x higher performance, a clear indication that the POWER8 CPU has a very wide integer execution engine, but can only deliver if enough threads are active.








146 Comments
View All Comments
LemmingOverlord - Friday, November 6, 2015 - link
Mate... Bite your tongue! Johan is THE man when it comes to Datacenter-class hardware. Obviously he doesn't get the same exposure as teh personal technology guys, but he is definitely one of the best reviewers out there (inside and outside AT).joegee - Friday, November 6, 2015 - link
He's been doing class A work since Ace's Hardware (maybe before, I found him on Ace's though.) He is a cut above the rest.nismotigerwvu - Friday, November 6, 2015 - link
Johan,I think you had a typo on the first sentence of the 3rd paragraph on page 1.
"After seeing the reader interestin POWER8 in that previous article..."
Nice read overall and if I hadn't just had my morning cup of coffee I would have missed it too.
Ryan Smith - Friday, November 6, 2015 - link
Good catch. Thanks!Essence_of_War - Friday, November 6, 2015 - link
That performance per watt, it is REALLY hard to keep up with the Xeons there!III-V - Friday, November 6, 2015 - link
IBM's L1 data cache has a 3-cycle access time, and is twice as large (64KB) as Intel's, and I think I remember it accounting for something like half the power consumption of the core.Essence_of_War - Friday, November 6, 2015 - link
Whoa, neat bit of trivia!JohanAnandtech - Saturday, November 7, 2015 - link
Interesting. Got a link/doc to back that up? I have not found such detailed architectural info.Henriok - Friday, November 6, 2015 - link
Very nice to see tests of non-x86 hardware. It's interesting too se a test of the S822L when IBM just launched two even more price competitive machines, designed and built by Wistron and Tyan, as pure OpenPOWER machines: the S812LC and S822LC. These can't run AIX, and are substantially cheaper than the IBM designed machines. They might lack some features, but they would probably fit nicely in this test. And they are sporting the single chip 12 core version of the POWER8 processor (with cores disabled).DanNeely - Friday, November 6, 2015 - link
"The server is powered by two redundant high quality Emerson 1400W PSUs."The sticker on the PSU is only 80+ (no color). Unless the hotswap support comes with a substantial penalty (if so why); this design looks to be well behind the state of the art. With data centers often being power/hvac limited these days, using a relatively low efficiency PSU in an otherwise very high end system seems bizarre to me.