The IBM POWER8 Review: Challenging the Intel Xeon
by Johan De Gelas on November 6, 2015 8:00 AM EST- Posted in
- IT Computing
- CPUs
- Enterprise
- Enterprise CPUs
- IBM
- POWER
- POWER8
The L4-cache and Memory Subsystem
Each POWER8 memory controller has access to four "Custom DIMMs" or CDIMMs. Each CDIMMs is in fact a "Centaur" chip and 40 to 80 DRAM chips. The Centaur chip contains the DDR3 interfaces, the memory management logic and a 16 MB L4-cache.
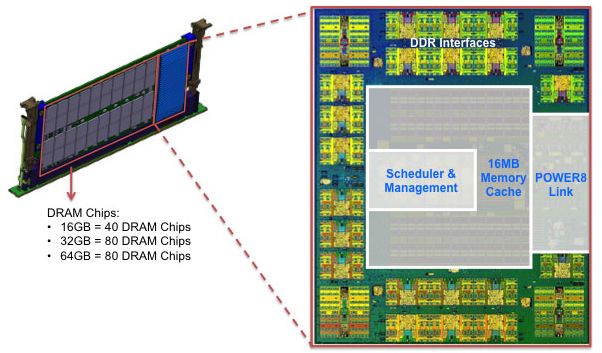
The 16 MB L4-cache is eDRAM technology like the on-die L3-cache. Let us see how the CDIMMs look in reality.

Considering that 4Gb DRAM chips were available in mid 2013, the 1600 MHz 2Gb DRAM chips used here look a bit outdated. Otherwise the (much) more expensive 64GB CDIMMs use the current 4Gb DRAM chips. The S822L has 16 slots and can thus use up to 1TB (64GB x 16) in DIMMs.

Considering that many Xeon E5 servers are limited to 768 GB, 1 TB is more than competitive. Some Xeon E5 servers can reach 1.5 TB with 64 GB LR-DIMMs but not every server supports this rather expensive memory technology. It is very easy to service the CDIMMs: a gentle push on the two sides will allow you to slide them out. The black pieces of plastic between the CDIMMS are just place-holders that protect the underlying memory slots. For our testing we had CDIMMs installed in 8 of our system's 16 slots.
The Centaur chip acts as a 16MB L4-cache to save memory accesses and thus energy, but it needs quite a bit of power (10-20 W) itself and as a result is covered by heatsink. CDIMMs have ECC enabled (8+1 for ECC) and have also an extra spare DRAM chip. As result, a CDIMM has 10 DRAM chips while offering capacity of 8 chips.

That makes the DRAM subsystem of the S822L much more similar to the E7 memory subsystem with the "Scalable memory interconnect" and "Jordan Creek" memory buffer technology than to the typical Xeon E5 servers.








146 Comments
View All Comments
usernametaken76 - Thursday, November 12, 2015 - link
Technically this is not true. IBM had a working version of AIX running on PS/2 systems as late as the 1.3 release. Unfortunately support was withdrawn and future releases of AIX were not compiled for x86 compatible processors. One can still find a copy of this release if one knows where to look. It's completely useless to anyone but a museum or curious hobbyist, but it's out there.zenip - Friday, November 13, 2015 - link
...>--click here-Steven Perron - Monday, November 23, 2015 - link
Hello Johan,I was reading this article, and I found it interesting. Since I am a developer for the IBM XL compiler, the comparisons between GCC and XL were particularly interesting. I tried to reproduce the results you are seeing for the LZMA benchmark. My results were similar, but not exactly the same.
When I compared GCC 4.9.1 (I know a slightly different version that you) to XL 13.1.2 (I assume this is the version you used), I saw XL consistently ahead of GCC, even when I used -O3 for both compilers.
I'm still interested in trying to reproduce your results, so I can see what XL can do better, so I have a couple questions on areas that could be different.
1) What version of the XL compiler did you use? I assumed 13.1.2, but it is worth double checking.
2) Which version of the 7-zip software did you use? I picked up p7zip 15.09.
3) Also, I noticed when the Power 8 machine was running at full capacity (for me that was 192 threads on a 24 core machine), the results would fluctuate a bit. How many runs did you do for each configuration? Were the results stable?
4) Did you try XL at the less aggressive and more stable options like "-O3" or "-O3 -qhot"?
Thanks for you time.
Toyevo - Wednesday, November 25, 2015 - link
Other than the ridiculous price of CDIMMs the power efficiency just doesn't look healthy. For data centers leasing their hardware like Amazon AWS, Google AppEngine, Azure, Rackspace, etc, clients who pay for hardware yet fail to use their allocation significantly help the bottom line of those companies by reduced overheads. For others high usage is a mandatory part of the ROI equation during its period as an operating asset, thus power consumption is a real cost. Even with our small cluster of 12 nodes the power efficiency is a real consideration, let alone companies standardizing toward IBM and utilising 100s or 1000s of nodes that are arguably less efficient.Perhaps you could devise some sort of theoretical total cost of ownership breakdown for these articles. My biggest question after all of this is, which one gets the most work done with the lowest overheads. Don't get me wrong though, I commend you and AnandTech on the detail you already provide.
AstroGuardian - Tuesday, December 8, 2015 - link
It's good to have someone challenging Intel, since AMD crap their pants on regular basisdba - Monday, July 25, 2016 - link
Dear Johan:Can you extrapolate how much faster the Sparc S7 will be in your Cluster Benchmarking,
if the 2 on Die Infiniband ports are Activated, 5, 10, 20% ???
Thank You, dennis b.