The Mobile CPU Core-Count Debate: Analyzing The Real World
by Andrei Frumusanu on September 1, 2015 8:00 AM EST- Posted in
- Smartphones
- CPUs
- Mobile
- SoCs
S-Browser - AnandTech Article
We start off with some browser-based scenarios such as website loading and scrolling. Since our device is a Samsung one, this is a good opportunity to verify the differences between the stock browser and Chrome as we've in the past identified large performance discrepancies between the two applications.
To also give the readers an idea of the actions logged, I've also recorded recreations of the actions during logging. These are not the actual events represented in the data as I didn't want the recording to affect the CPU behaviour.
We start off by loading an article on AnandTech and quickly scrolling through it. It's mostly at the beginning of the events that we're seeing high computational load as the website is being loaded and rendered.
Starting off at a look of the little cluster behaviour:
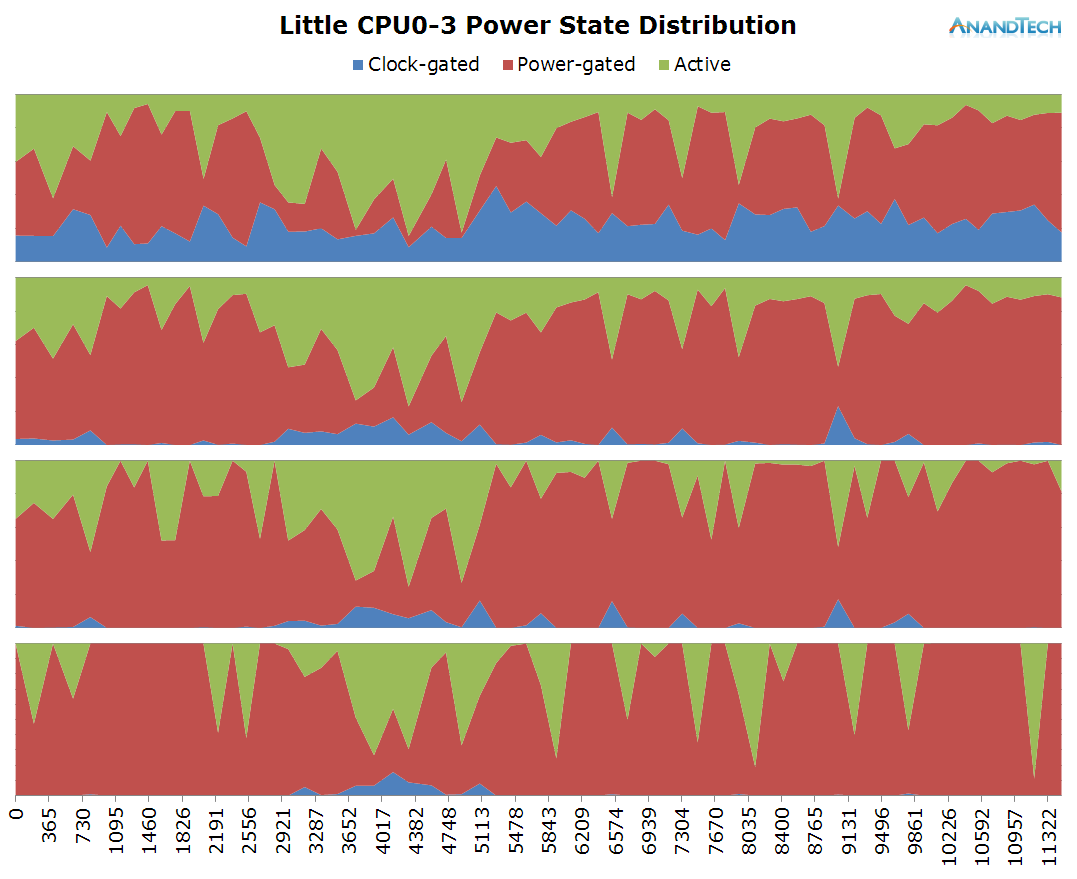
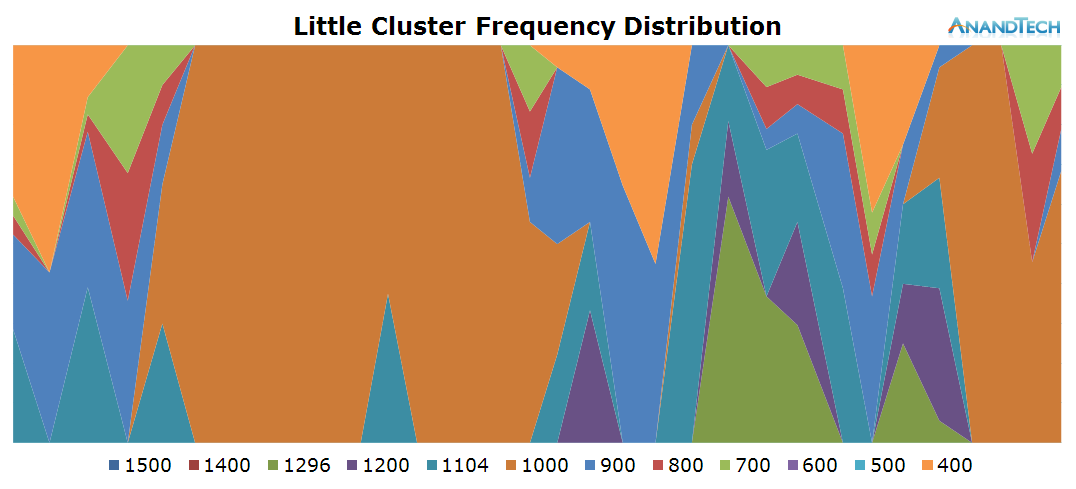

The time period of the data is 11.3s, as represented in the x-axis of the power state distribution chart. During the rendering of the page there doesn't seem to be any particular high load on the little cores in terms of threads, as we only see about 1 little thread use up around 20% of the CPU's capacity. Still this causes the cluster to remain at around the 1000MHz mark and causes the little cores to mostly stay in their active power state.
Once the website is loaded around the 6s mark, threads begin to migrate back to the little cores. Here we actually see them being used quite extensively as we see peaks of 70-80% usage. We actually have bursts where may seem like the total concurrent threads on the little cluster exceeds 4, but still nothing too dramatically overloaded.
Moving on to the big cluster:
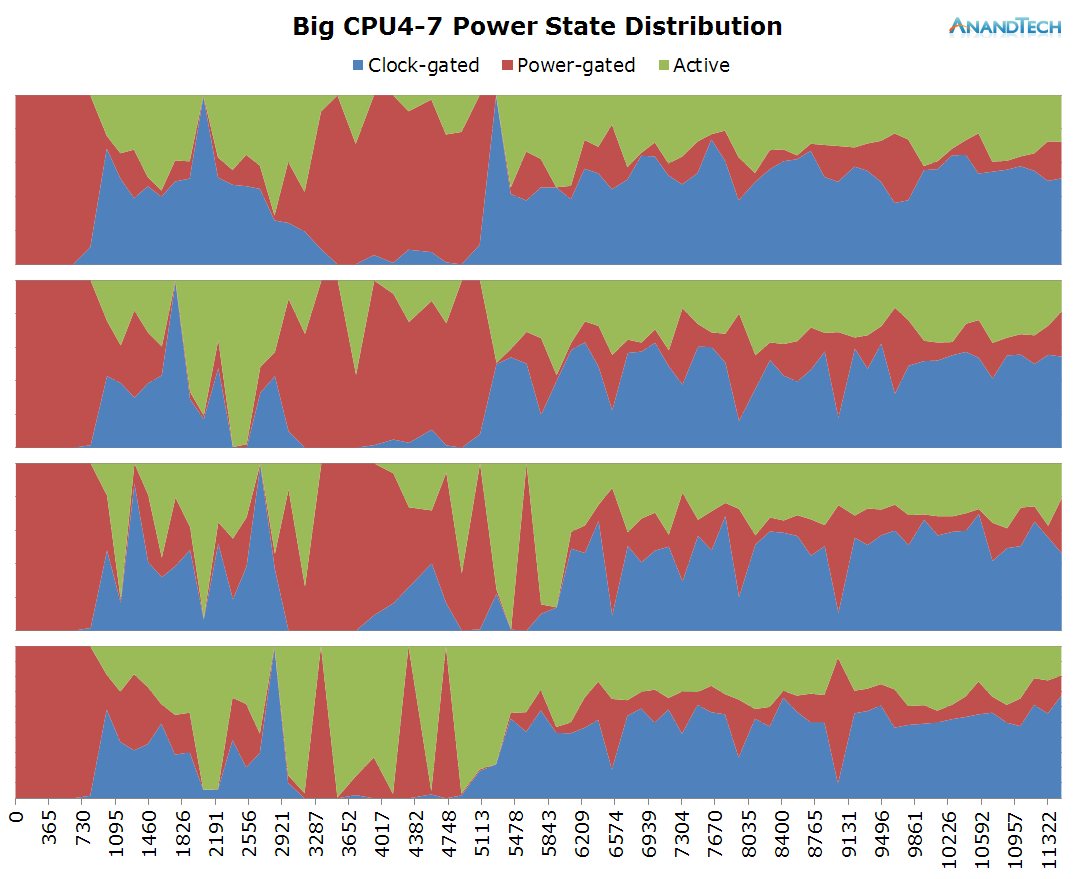
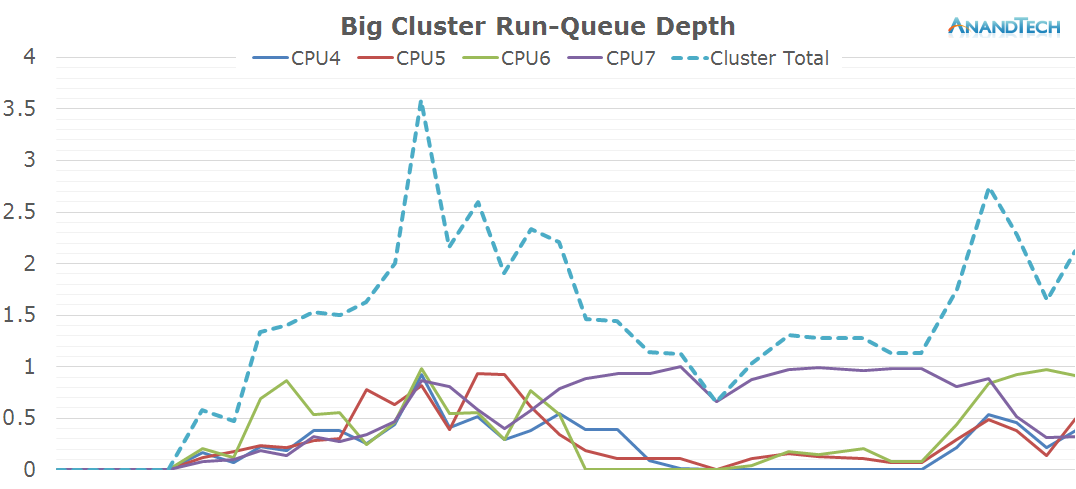
On the big cluster, we see an inversion of the run-queue graph. Where the little cores didn't have many threads placed on them, we see large activity on the big cluster. The initial web site rendering is clearly done by the big cluster, and it looks like all 4 cores have working threads on them. Once the rendering is done and we're just scrolling through the page, the load on the big cluster is mostly limited to 1 large thread.
What is interesting to see here is that even though it's mostly just 1 large thread that requires performance on the big cores, most of the other cores still have some sort of activity on them which causes them to not be able to fall back into their power-collapse state. As a result, we see them stay within the low-residency clock-gated state.
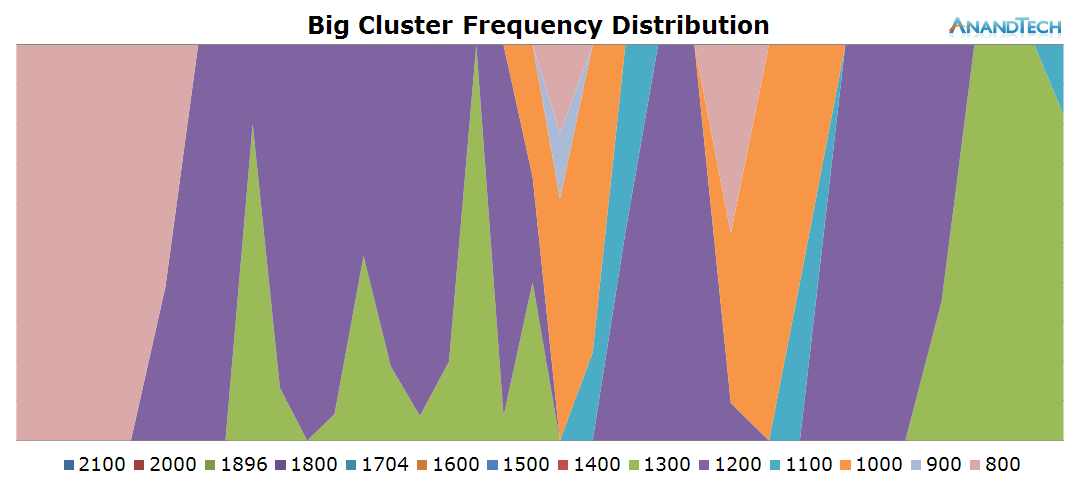
On the frequency side, the big cores scale up to 1300-1500 MHz while rendering the initial site and 1000-1200 while scrolling around the loaded page.
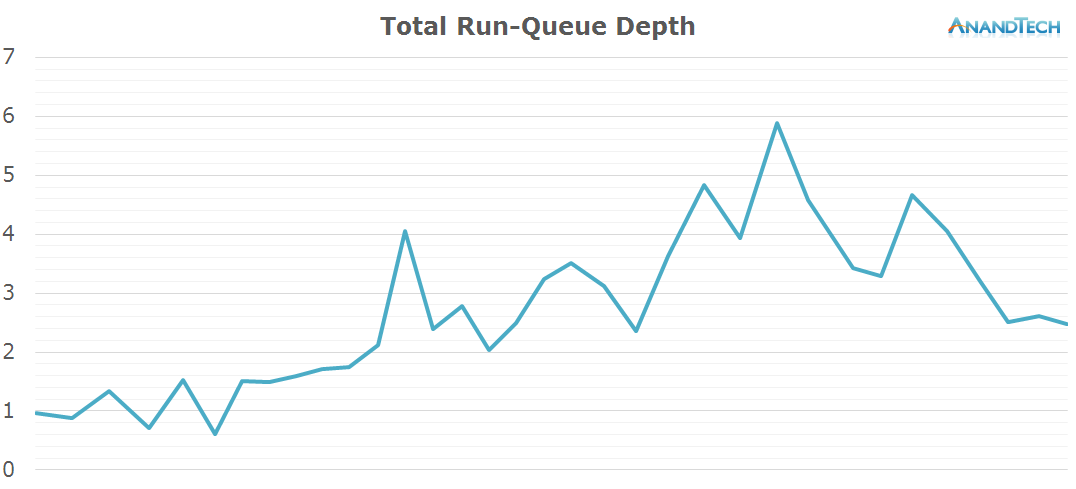
When looking at the total amount of threads on the system, we can see that the S-Browser makes good use of at least 4 CPU cores with some peaks of up to 5 threads. All in all, this is a scenario which doesn't necessarily makes use of 8 cores per-se, however the 4+4 setup of big.LITTLE SoCs does seem to be fully utilized for power management as the computational load shifts between the clusters depending on the needed performance.








157 Comments
View All Comments
modulusshift - Tuesday, September 1, 2015 - link
Heck yes. And of course I'm interested if anything like this is even remotely possible for Apple hardware, though likely it would require jailbreaks, at least.Andrei Frumusanu - Tuesday, September 1, 2015 - link
Unfortunately basically none of the metrics measured here would be possible to extract from an iOS device.TylerGrunter - Tuesday, September 1, 2015 - link
Add one more vote for the follow up with synthetics.I would also want to see how the multitasking compares with the Snapdragons as they use the different frequency and voltage planes per core instead of the big.LITTLE.
But I guess that would be better to see with the SD 820, as the 810 uses big.LITTLE. Consider it a request for when it comes!
tuxRoller - Wednesday, September 2, 2015 - link
Big.little can use multiple planes for either cluster. The issue is purely implementation, tmk.TylerGrunter - Wednesday, September 2, 2015 - link
big.LITTLE can be use different planes for each cluster but same for all cores in each cluster, Qualcomm SoCs can use different planes for each core, that's the difference and it's a big one.https://www.qualcomm.com/news/onq/2013/10/25/power...
I'm not sure that can be done in big.LITTLE.
tuxRoller - Friday, September 4, 2015 - link
I remember that but that doesn't say that big.LITTLE can't keep each core on its own power plane just that the implementations haven't.soccerballtux - Tuesday, September 1, 2015 - link
to balance everything out-- meh, that doesn't interest me. most of the time I'm concerned with battery life and every-day performance. Android isn't a huge gaming device so absolute performance doesn't interest me.porphyr - Tuesday, September 1, 2015 - link
Please do!ppi - Tuesday, September 1, 2015 - link
Go ahead. This is one of the most interesting performance digging on this site since the random-write speeds on SSDs.jospoortvliet - Friday, September 4, 2015 - link
Yes, this was an awesome and interesting read.