The Mobile CPU Core-Count Debate: Analyzing The Real World
by Andrei Frumusanu on September 1, 2015 8:00 AM EST- Posted in
- Smartphones
- CPUs
- Mobile
- SoCs
Hangouts Launch
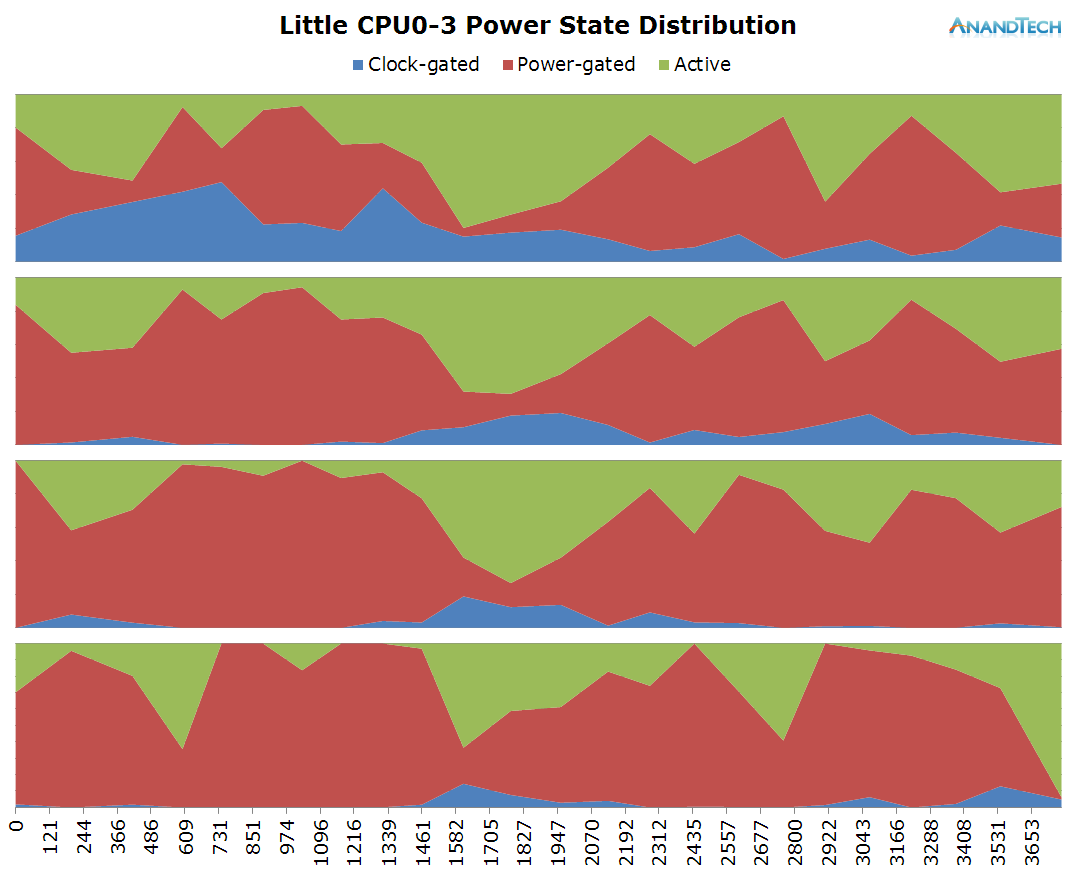
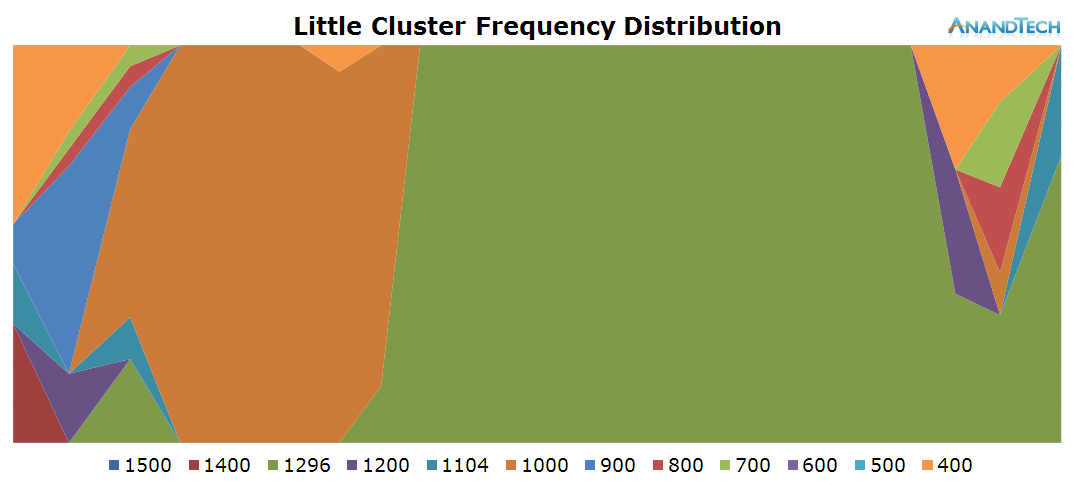
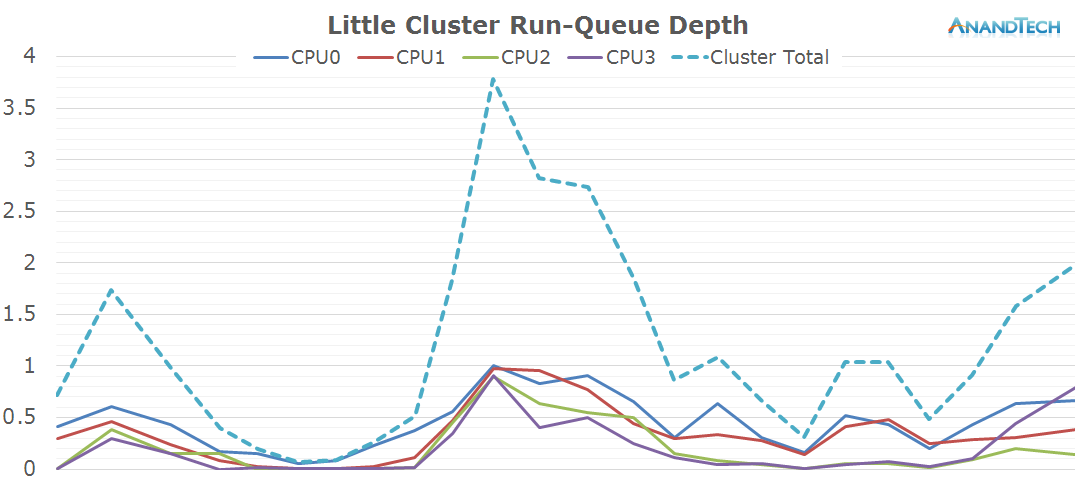
The duration of the test this time is only 3.6 seconds. During the initial application launch, we don't see much activity on the little cores. Cores 1-3 are mostly power-gated and we see that there's little to no threads placed onto the cluster during that period. Once the app opened, we see the threads migrate back onto the little cluster. Here we see full use of all 4 CPU cores as each core has threads placed on it doing activity.
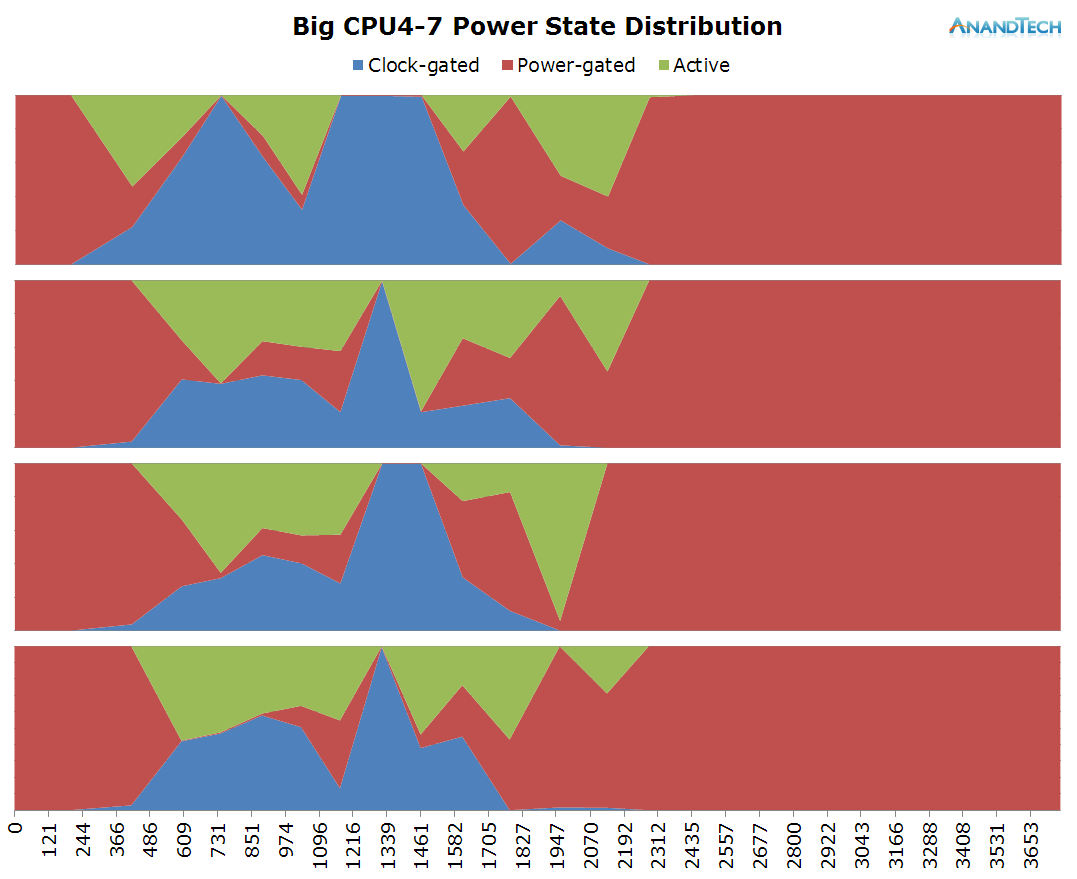
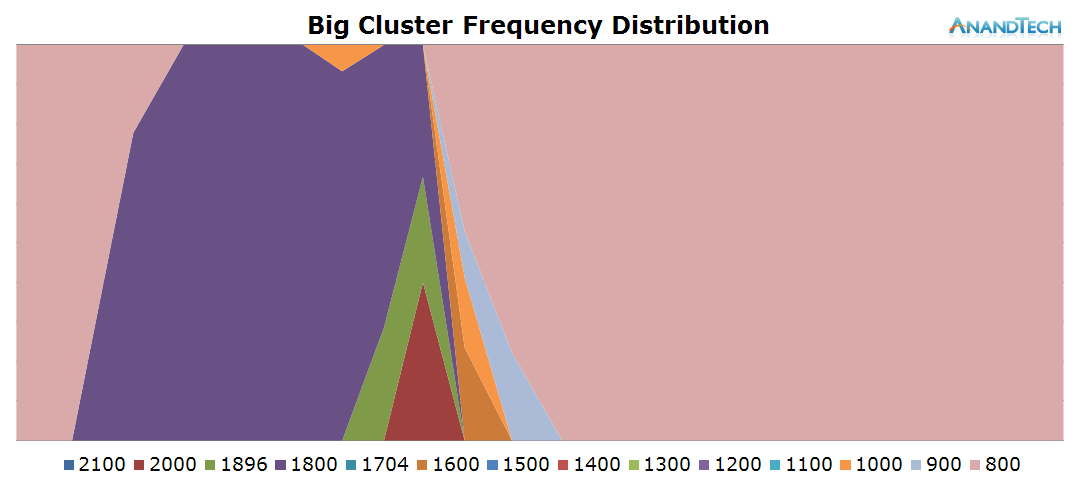
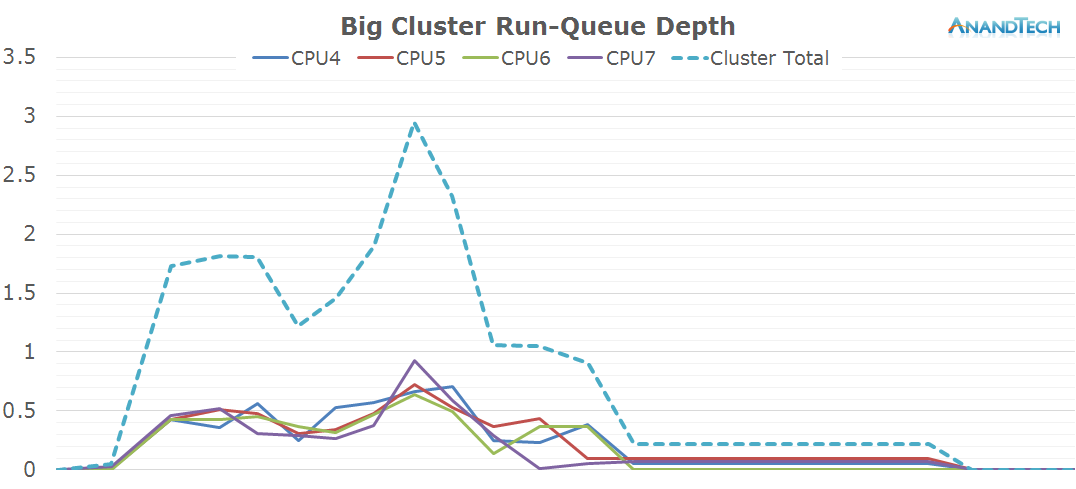
This is the perfect burst-scenario for the big cores. The application launch kicks in the cores into high gear as they reach the full 2.1GHz of the SoC. We see that all 4 cores are doing work and have thread placed on them. Because of the fine granularity of the load, we see the CPUs rarely enter the power-gating state in this burst period as the CPU Idle governor prefers the shallower WFI clock-gating state. As a reminder, on the Exynos 7420 this state is setup for target residency times of 500µS.
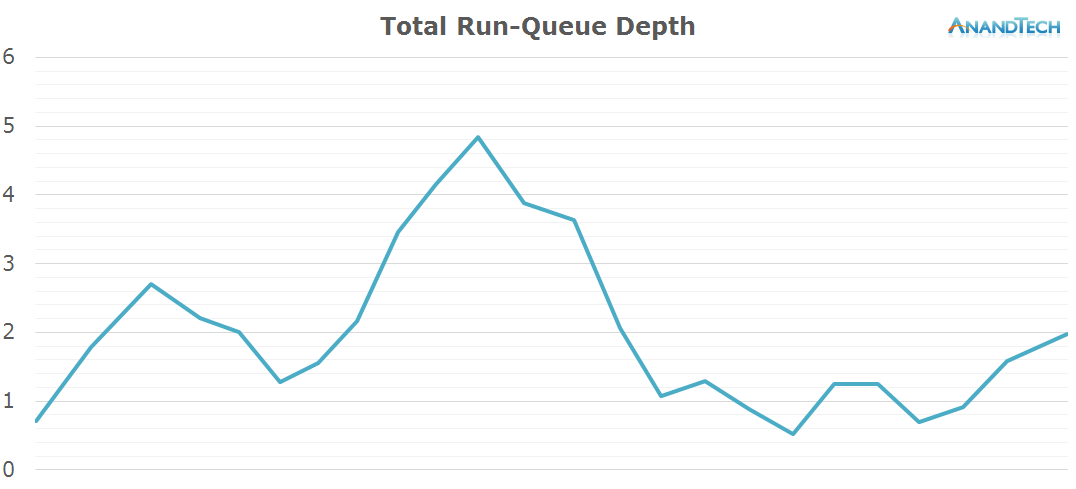
In general, the workload is optimized towards 4-core CPUs. Because 4x4 big.LITTLE SoCs in a sense can be seen as 4-core designs, we don't see an issue here. On the other hand, symmetric 8-core designs here would see very little benefit from the additional cores.








157 Comments
View All Comments
rstuart - Tuesday, September 1, 2015 - link
Wow, excellent article. Colour me impressed that the developers use 4 cores effectively more times than not. It was not what I was expecting. Nor did I realise how much of the video processing task was offloaded to the GPU. In fact it's so good I suspect there will be more than a few electrical engineers poring over this in order to understand how well their software brethren make use of the hardware they provide.Filiprino - Tuesday, September 1, 2015 - link
Are you sure the Galaxy S6 employs the CFS scheduler? Should not it be the GTS scheduler?Andrei Frumusanu - Tuesday, September 1, 2015 - link
GTS is just an extension on top of CFS.Filiprino - Wednesday, September 2, 2015 - link
Well, yes. But it's not the same saying CFS or GTS. I think it should be noted that the phone is using GTS whose run queues work like in CFS.Andrei Frumusanu - Saturday, September 5, 2015 - link
GTS doesn't touch runqueues. GTS's modification to the CFS scheduler are relatively minor, it's still very much CFS at the core.AySz88 - Tuesday, September 1, 2015 - link
A technical note regarding "...scaling up higher in frequency has a quadratically detrimental effect on power efficiency as we need higher operating voltages..." - note that power consumption *already* goes up quadratically as voltage squared, BEFORE including the frequency change (i.e. P = k*f*v*v). So if you're also scaling up voltage while increasing frequency, you get a horrific blowing-up-in-your-face CUBIC relationship between power and frequency.ThreeDee912 - Tuesday, September 1, 2015 - link
Being in the Apple camp, I do know Apple also highly encourages developers to use multithreading as much as possible with their Grand Central Dispatch API, and has implemented things like App Nap and timer coalescing to help with the "race-to-idle" in OS X. I'm guessing Apple is likely taking this into account when designing their ARM CPUs as well. The thing is, unlike OS X, iOS and their A-series CPUs are mostly a black box of unknowns, other than whatever APIs they let developers use.jjj - Wednesday, September 2, 2015 - link
For web browsing i do wish you would look at heavier sites, worst case scenario since that's when the device stumbles and look at desktop versions.Would be nice to have a total run-queue depth graph normalized for core perf and clocks ( so converted in total perf expressed in w/e unit you like) to see what total perf would be needed (and mix of cores) with an ideal scheduler - pretty hard to do it in a reasonable way but it would be an interesting metric. After all the current total is a bit misleading by combining small and big , it shows facts but ppl can draw the wrong conclusions, like 4 cores is enough or 8 is not. Many commenters seem to jump to certain conclusions because of it too.
Would be nice to see the tests for each cluster with the other cluster shut down, ideally with perf and power measured too. Would help address some objections in the comments.
In the Hangouts launch test conclusion you say that more than 4 cores wouldn't be needed but that doesn't seem accurate outside the high end since if all the cores were small. assuming the small cores would be 2-3 times lower perf, then above 1.5 run-queue depth on the big cores might require more than 4 small cores if we had no big ones. Same goes for some other tests
A SoC with 3 types of cores , 2 of them big ,even bigger than A72 , and a bunch of medium and small does seem to make sense, with a proper scheduler and thermal management ofc. For midrange 2+4 should do and it wouldn't increase the cost too much vs 8 small ones, depending a bit on cache size - lets say on 16ff A53 bellow 0.5mm2 , A72 1.15mm2 and cache maybe close to 1.7 mm2 per 1MB. so a very rough approximation would be 2-3mm2 penalty depending if the dual A72 has 1 or 2MB L2. a lot more if the dual A72 forces them to add a second memory chan but even then it's worth the cost, 1-2$ more for the OEM would be worth it given the gain in single threaded perf and the marketing benefits
When looking at perf and battery in the real world multitasking is always present in some way. in benchmarks, never is. So why not try that too, something you encounter in daily usage. a couple of extra threads from other things should matter enough - maybe on Samsung devices you could test in split screen mode too, since it's something ppl do use and actually like.
For games it would be interesting to plot GPU clocks and power or temps as well as maybe FPS. Was expecting games to use the small cores more to allow for more TDP to go to the GPU and the games you tested do seem to do just that. Maybe you could look at a bunch of games from that perspective. Then again, it would be nice if AT would just start testing real games instead of synthetic nonsense that has minimal value and relevance
A look at image processing done on CPU+GPU would be interesting.
The way Android scales on many cores is encouraging for glasses where every cubic mm matters and batteries got to be tiny. Do hope the rumored Mercury core for wearables at 50-150mW is real and shows up soon.
Oh and i do support looking at how AT's battery of benchmarks is behaving but a better solution would be to transition away from synthetic, no idea why it takes so long in mobile when we had the PC precedent and nobody needs an explanation as to why synthetic benchmarks are far from ideal.
Anyway, great to see some effort in actually understanding mobile, as opposed to dubious synthetic benchmarks and empty assumptions that have been dominating this scene.AT should hire a few more people to help you out and increase the frequency of such articles since there are lots of things to explore and nobody is doing it.
tuxRoller - Wednesday, September 2, 2015 - link
Linux had largely been guided towards massively multiprocess workloads. If they didn't do this well then they wouldn't do anything well.The scheduler should be getting a lot better soon. It APPEARS that, after a long long long long time, things are moving forward on the combined scheduler (cfs), cpuidle, and cpufreq (dvfs) front. That's necessary in order to proper scheduling of tasks, especially across an aSMP soc.
One thing to keep in mind is that these oems often carry out of tree patches that they believe help their hardware. Often these patches are of, ahem, suspect quality, and pretty much always perform their task with some noticeable drawbacks. The upstream solution is (almost?) always "better".
Iow, things should only get better.
toyotabedzrock - Wednesday, September 2, 2015 - link
Is Chrome rendering pages it expects you to visit on the little cores?You should test with Chrome DEV as well.