The Intel 6th Gen Skylake Review: Core i7-6700K and i5-6600K Tested
by Ian Cutress on August 5, 2015 8:00 AM ESTThe Skylake CPU Architecture
As with any new Intel architecture, the devil is in the details. Previously at AnandTech we have been able to provide deep dives into what exactly is going on in the belly of the beast, although the launch of Skylake has posed a fair share of problems.
Nominally we rely on a certain amount of openness from the processor/SoC manufacturer in providing low level details that we can verify and/or explain. In the past, this information has typically been provided in advance of the launch by way of several meetings/consultations with discussions talking to the engineers. There are some things we can probe, but others are like a black box. The black box nature of some elements, such as Qualcomm’s Adreno graphics, means that it will remain a mystery until Pandora’s box is opened.
In the lead up to the launch of Intel’s Skylake platform, architecture details have been both thin on the ground and thin in the air, even when it comes down to fundamental details about the EU counts of the integrated graphics, or explanations regarding the change in processor naming scheme. In almost all circumstances, we’ve been told to wait until Intel’s Developer Forum in mid-August for the main reason that the launch today is not the full stack Skylake launch, which will take place later in the quarter. Both Ryan and I will be at IDF taking fastidious notes and asking questions for everyone, but at this point in time a good portion of our analysis comes from information provided by sources other than Intel, and while we trust it, we can't fully verify it as we normally would.
As a result, the details on the following few pages have been formed through investigation, discussion and collaboration outside the normal channels, and may be updated as more information is discovered or confirmed. Some of this information is mirrored in our other coverage in order to offer a complete picture in each article as well. After IDF we plan to put together a more detailed architecture piece as a fundamental block in analyzing our end results.
The CPU
As bad as it sounds, the best image of the underlying processor architecture is the block diagram:
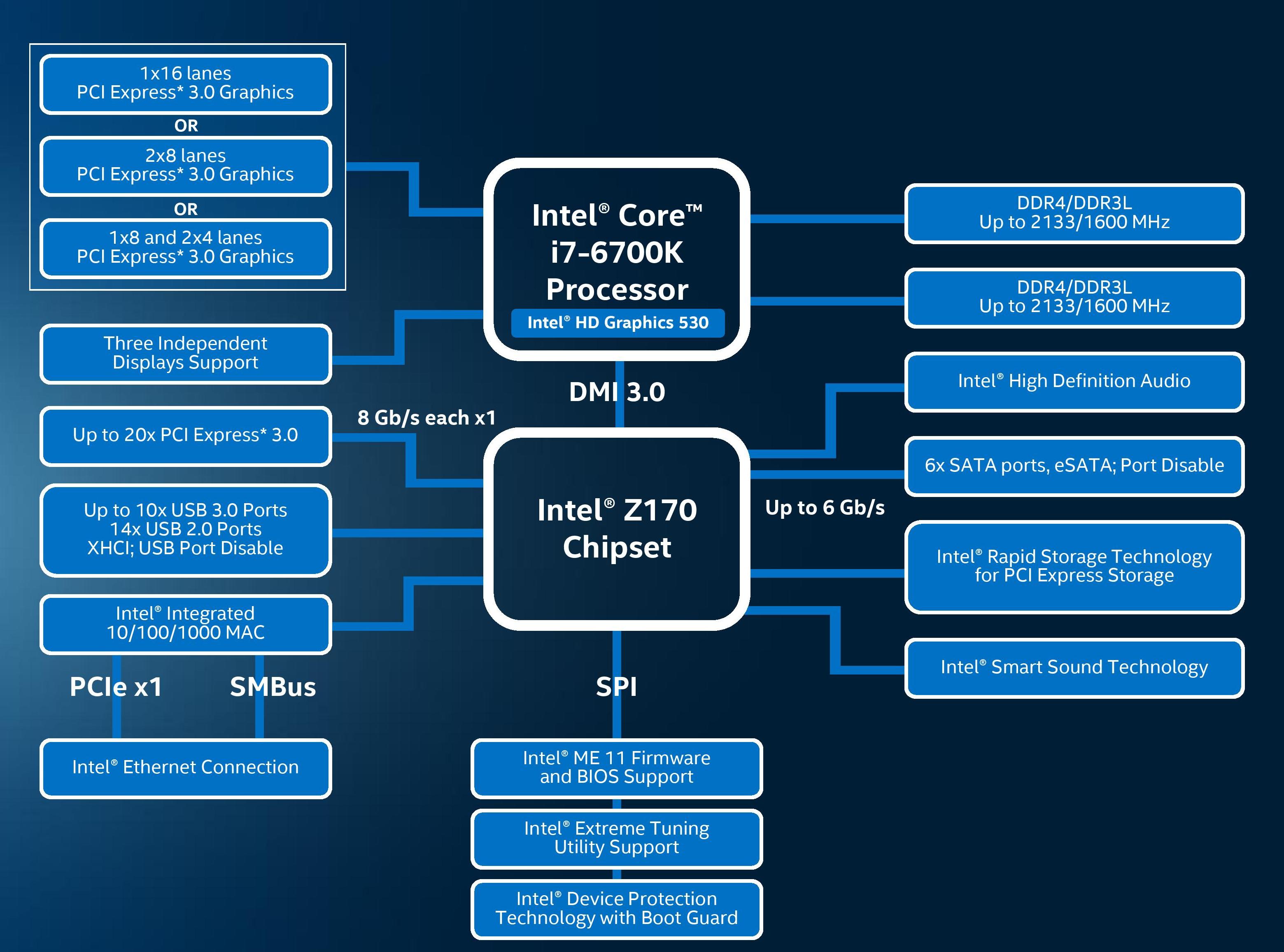
From a CPU connectivity standpoint, we discussed the DDR3L/DDR4 dual memory controller design on the previous page so we won’t go over it again here. On the PCI-Express Graphics allocation side, the Skylake processors will have sixteen PCIe 3.0 lanes to use for directly attached devices to the processor, similar to Intel's previous generation processors. These can be split into a single PCIe 3.0 x16, x8/x8 or x8/x4/x4 with basic motherboard design. (Note that this is different to early reports of Skylake having 20 PCIe 3.0 lanes for GPUs. It does not.)
With this, SLI will work up to x8/x8. If a motherboard supports x8/x4/x4 and a PCIe card is placed into that bottom slot, SLI will not work because only one GPU will have eight lanes. NVIDIA requires a minimum of PCIe x8 in order to enable SLI. Crossfire has no such limitation, which makes the possible configurations interesting. Below we discuss that the chipset has 20 (!) PCIe 3.0 lanes to use in five sets of four lanes, and these could be used for graphics cards as well. That means a motherboard can support x8/x8 from the CPU and PCIe 3.0 x4 from the chipset and end up with either dual-SLI or tri-CFX enabled when all the slots are populated.
DMI 3.0
The processor is connected to the chipset by the four-lane DMI 3.0 interface. The DMI 3.0 protocol is an upgrade over the previous generation which used DMI 2.0 – this upgrade boosts the speed from 5.0 GT/s (2GB/sec) to 8.0 GT/s (~3.93GB/sec), essentially upgrading DMI from PCIe 2 to PCIe 3, but requires the motherboard traces between the CPU and chipset to be shorter (7 inches rather than 8 inches) in order to maintain signal speed and integrity. This also allows one of the biggest upgrades to the system, chipset connectivity, as shown below in the HSIO section.
CPU Power Arrangements
Moving on to power arrangements, with Skylake the situation changes as compared to Haswell. Prior to Haswell, voltage regulation was performed by the motherboard and the right voltages were then put into the processor. This was deemed inefficient for power consumption, and for the Haswell/Broadwell processors Intel decided to create a fully integrated voltage regulator (FIVR) in order to reduce motherboard cost and reduce power consumption. This had an unintended side-effect – while it was more efficient (good for mobile platforms), it also acted as a source of heat generation inside the CPU with high frequencies. As a result, overclocking was limited by temperatures and the quality of the FIVR led to a large variation in results. For Skylake on the desktop, the voltage regulation is moved back into the hands of the motherboard manufacturers. This should allow for cooler processors depending on how the silicon works, but it will result in slightly more expensive motherboards.
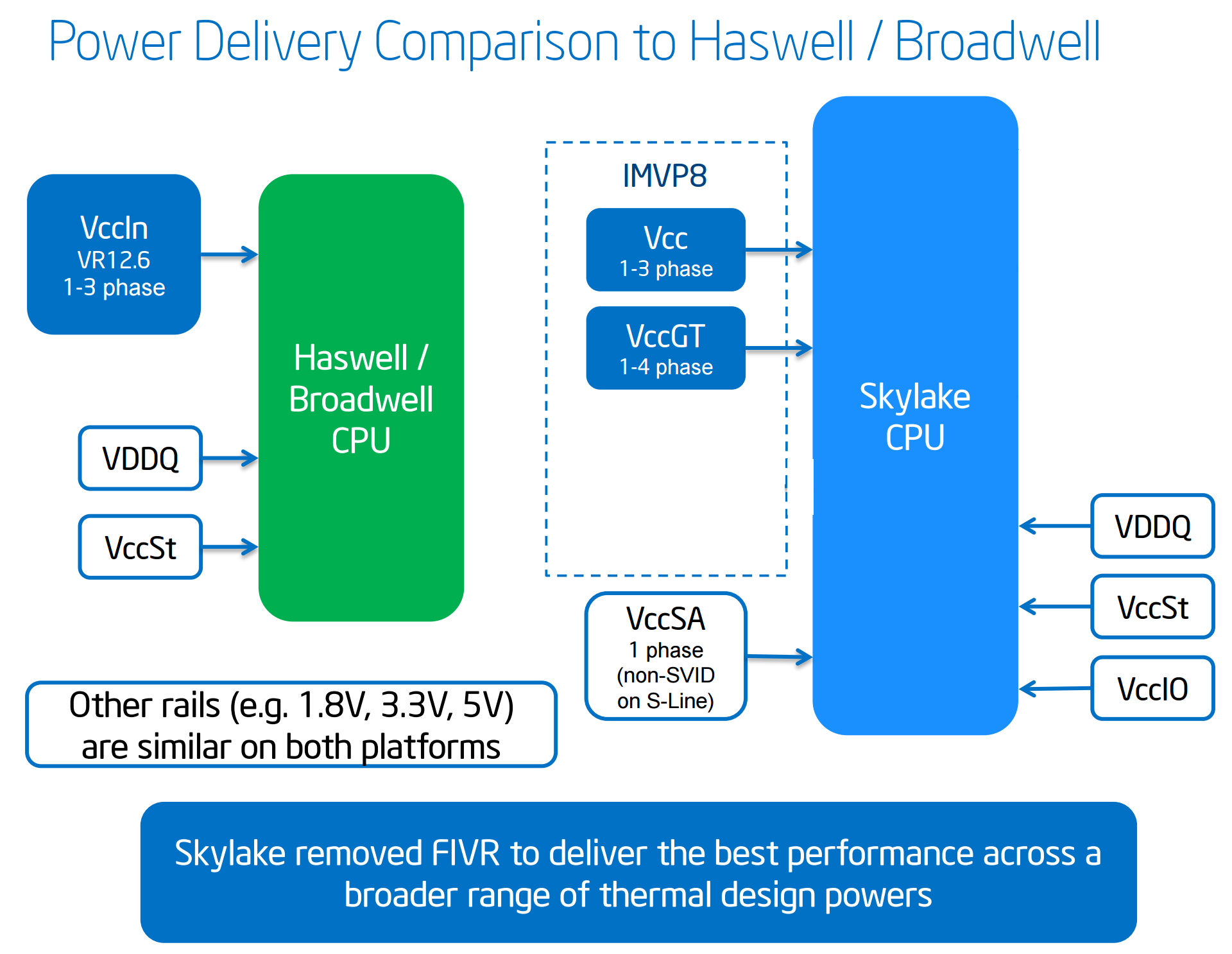
A slight indication of this will be that some motherboards will go back to having a large amount of multiplexed phases on the motherboard, and it will allow some manufacturers to use this as a differentiating point, although the usefulness of such a design is sometimes questionable.








477 Comments
View All Comments
SkOrPn - Tuesday, December 13, 2016 - link
Well if you were paying attention to AMD news today, maybe you partially got your answer finally. Jim Keller yet again to the rescue. Ryzen up and take note... AMD is back...CaedenV - Wednesday, August 5, 2015 - link
Agreed, seems like the only way to get a real performance boost is to up the core count rather than waiting for dramatically more powerful single-core parts to hit the market.kmmatney - Wednesday, August 5, 2015 - link
If you have an overclocked SandyBridge, it seems like a lot of money to spend (new motherboard and memory) for a 30% gain in speed. I personally like to upgrade my GPU and CPU when I can get close the double the performance of the previous hardware. It's a nice improvement here, but nothing earth=shattering - especially considering you need a new motherboard and memory.Midwayman - Wednesday, August 5, 2015 - link
And right as dx12 is hitting as well. That sandy bridge may live a couple more generations if dx12 lives up to the hype.freaqiedude - Wednesday, August 5, 2015 - link
agreed I really don't see the point of spending money for a 30% speedbump in general, (as its not that much) when the benefit in games is barely a few percent, and my other workloads are fast enough as is.If Intel would release a mainstream hexa/octa core I would be all over that, as the things I do that are heavy are all SIMD and thus fully multithreaded, but I can't justify a new pc for 25% extra performance in some area's. with CPU performance becoming less and less relevant for games that atleast is no reason for me to upgrade...
Xenonite - Thursday, August 6, 2015 - link
"If Intel would release a mainstream hexa/octa core I would be all over that, as the things I do that are heavy are all SIMD and thus fully multithreaded, but I can't justify a new pc for 25% extra performance in some area's."SIMD actually has absolutely nothing to do with multithreading. SIMD refers to instruction-level parallellism, and all that has to be done to make use of it, for a well-coded app, is to recompile with the appropriate compiler flag. If the apps you are interested in have indeed been SIMD optimised, then the new AVX and AVX2 instructions have the potential to DOUBLE your CPU performance. Even if your application has been carefully designed with multi-threading in mind (which very few developers can, let alone are willing to, do) the move from a quad core to a hexa core CPU will yield a best-case performance increase of less than 50%, which is less than half what AVX and AVX2 brings to the table (with AVX-512 having the potential to again provide double the performance of AVX/AVX2).
Unfortunately it seems that almost all developers simply refuse to support the new AVX instructions, with most apps being compiled for >10 year old SSE or SSE2 processors.
If someone actually tried, these new processors (actually Haswell and Broadwell too) could easily provide double the performance of Sandy Bridge on integer workloads. When compared to the 900-series Nehalem-based CPUs, the increase would be even greater and applicable to all workloads (integer and floating point).
boeush - Thursday, August 6, 2015 - link
Right, and wrong. SIMD are vector based calculations. Most code and algorithms do not involve vector math (whether FP or integer). So compiling with or without appropriate switches will not make much of a difference for the vast majority of programs. That's not to say that certain specialized scenarios can't benefit - but even then you still run into a SIMD version of Amdahl's Law, with speedup being strictly limited to the fraction of the code (and overall CPU time spent) that is vectorizable in the first place. Ironically, some of the best vectorizable scenarios are also embarrassingly parallel and suitable to offloading on the GPU (e.g. via OpenCL, or via 3D graphics APIs and programmable shaders) - so with that option now widely available, technologically mature, and performant well beyond any CPU's capability, the practical utility of SSE/AVX is diminished even further. Then there is the fact that a compiler is not really intelligent enough to automatically rewrite your code for you to take good advantage of AVX; you'd actually have to code/build against hand-optimized AVX-centric libraries in the first place. And lastly, AVX 512 is available only on Xeons (Knights Landing Phi and Skylake) so no developer targeting the consumer base can take advantage of AVX 512.Gonemad - Wednesday, August 5, 2015 - link
I'm running an i7 920 and was asking myself the same thing, since I'm getting near 60-ish FPS on GTA 5 with everything on at 1080p (more like 1920 x 1200), running with a R9 280. It seems the CPU would be holding the GFX card back, but not on GTA 5.Warcraft - who could have guessed - is getting abysmal 30 FPS just standing still in the Garrison. However, system resources shows GFX card is being pushed, while the CPU barely needs to move.
I was thinking perhaps the multicore incompatibility on Warcraft would be an issue, but then again the evidence I have shows otherwise. On the other hand, GTA 5, that was created in the multicore era, runs smoothly.
Either I have an aberrant system, or some i7 920 era benchmarks could help me understand what exactly do I need to upgrade. Even specific Warcraft behaviour on benchmarks could help me, but I couldn't find any good decisive benchmarks on this Blizzard title... not recently.
Samus - Wednesday, August 5, 2015 - link
The problem now with nehalem and the first gen i7 in general isn't the CPU, but the x58 chipset and its outdated PCI express bus and quickpath creating a bottleneck. The triple channel memory controller went mostly unsaturated because of the other chipset bottlenecks which is why it was dropped and (mostly) never reintroduced outside of enthusiast x99 quad channel interface.For certain applications the i7 920 is, amazingly, still competitive today, but gaming is not one of them. An SLI GTX 570 configuration saturates the bus, I found out first hand that is about the most you can get out of the platform.
D. Lister - Thursday, August 6, 2015 - link
Well said. The i7 9xx series had a good run, but now, as an enthusiast/gamer in '15, you wouldn't want to go any lower than Sandy Bridge.