NVIDIA @ ICML 2015: CUDA 7.5, cuDNN 3, & DIGITS 2 Announced
by Ryan Smith on July 7, 2015 4:00 AM EST
Taking place this week in Lille, France is the 2015 International Conference on Machine Learning, or ICML. Now in its 32nd year, the annual event is one of the major international conferences focusing on machine learning. Coinciding with this conference are a number of machine learning announcements, and with NVIDIA now heavily investing in machine learning as part of their 2015 Maxwell and Tegra X1 initiatives with a specific focus on deep neural networks, NVIDIA is at the show this year to release some announcements of their own.
All-told, NVIDIA is announcing new releases for three of their major software libraries/environments, CUDA, cuDNN, and DIGITS. While NVIDIA is primarily in the business of selling hardware, the company has for some time now focused on the larger GPU compute ecosystem as a whole as a key to their success. Putting together useful and important libraries for developers helps to make GPU development easier and to attract developer interest from other platforms. Today’s announcements in turn are Maxwell and FP16-centric, with NVIDIA laying the groundwork for neural networks and other half-precision compute tasks which the company believes will be important going forward. Though the company only has a single product so far that has a higher performance FP16 mode – Tegra X1 – it has more than subtly been hinted at that the next-generation Pascal GPUs will incorporate similar functionality, making for all the more reason for NVIDIA to get the software out in advance.
CUDA 7.5
Starting things off we have CUDA 7.5, which is now available as a release candidate. The latest update for NVIDIA’s GPU compute platform is a smaller release as one would expect for a half-version update, and is primarily focused on laying the API groundwork for FP16. To that end CUDA 7.5 introduces proper support for FP16 data, and while non-Tegra GPUs still don’t receive a compute performance benefit from using FP16 data, they do benefit from reduced memory pressure. So for the moment NVIDIA is enabling this feature for developers to take advantage of any performance benefits from the reduced memory bandwidth needs and/or allowing for larger datasets in the same amount of GPU memory.
Meanwhile CUDA 7.5 is also introducing new instruction level profiling support. NVIDIA’s existing profiling tools (e.g. Visual Profiler) already go fairly deep, but now the company is looking to go one step further in helping developers identify specific code segments and instructions that may be holding back performance.
cuDNN 3
NVIDIA’s second software announcement of the day is the latest version of the CUDA Deep Neural Network library (cuDNN), NVIDIA’s collection of GPU accelerated neural networking functions, which is now up to version 3. Going hand-in-hand with CUDA 7.5, a big focus on cuDNN 3 is support for FP16 data formats for existing NVIDIA GPUs in order to allow for more efficient memory and memory bandwidth utilization, and ultimately larger data sets.

Meanwhile separate from NVIDIA’s FP16 optimizations, cuDNN 3 also includes some optimized routines for Maxwell GPUs to speed up overall performance. NVIDA is telling us that FFT convolutions and 2D convolutions have both been added as optimized functions here, and that they are touting an up to 2x increase in neural network training performance on Maxwell GPUs.
DIGITS 2
Finally, built on top of CUDA and cuDNN is DIGITS, NVIDIA’s middleware for deep learning GPU training. First introduced just back in March at the 2015 GPU Technology Conference, NVIDIA is rapidly iterating on the software with version 2 of the package. DIGITS, in a nutshell, is NVIDIA’s higher-level neural network software for general scientists and researchers (as opposed to programmers), offering a more complete neural network training system for those users who may not be accomplished computer programmers or neural network researchers.
NVIDIA® DIGITS™ Deep Learning GPU Training System
DIGITS 2 in turn introduces support for training neural networks over multiple GPUs, going hand-in-hand with NVIDIA’s previously announced DIGITS DevBox (which is built from 4 GTX Titan Xs). All things considered the performance gains from using multiple GPUs are not all that spectacular – NVIDIA is touting just a 2x performance increase in going from 1 to 4 GPUs – though for performance-bound training this none the less helps. Looking at NVIDIA’s own data, it looks like scaling from 1 to 2 GPUs is rather good, but scaling from 2 to 4 GPUs is where the performance gains from scaling slow down, presumably due to a combination of bus traffic and synchronization issues over a larger number of GPUs. Though on that note, it does make me curious whether the Pascal GPUs and their NVLink buses will improving multi-GPU scaling at all in this scenario.
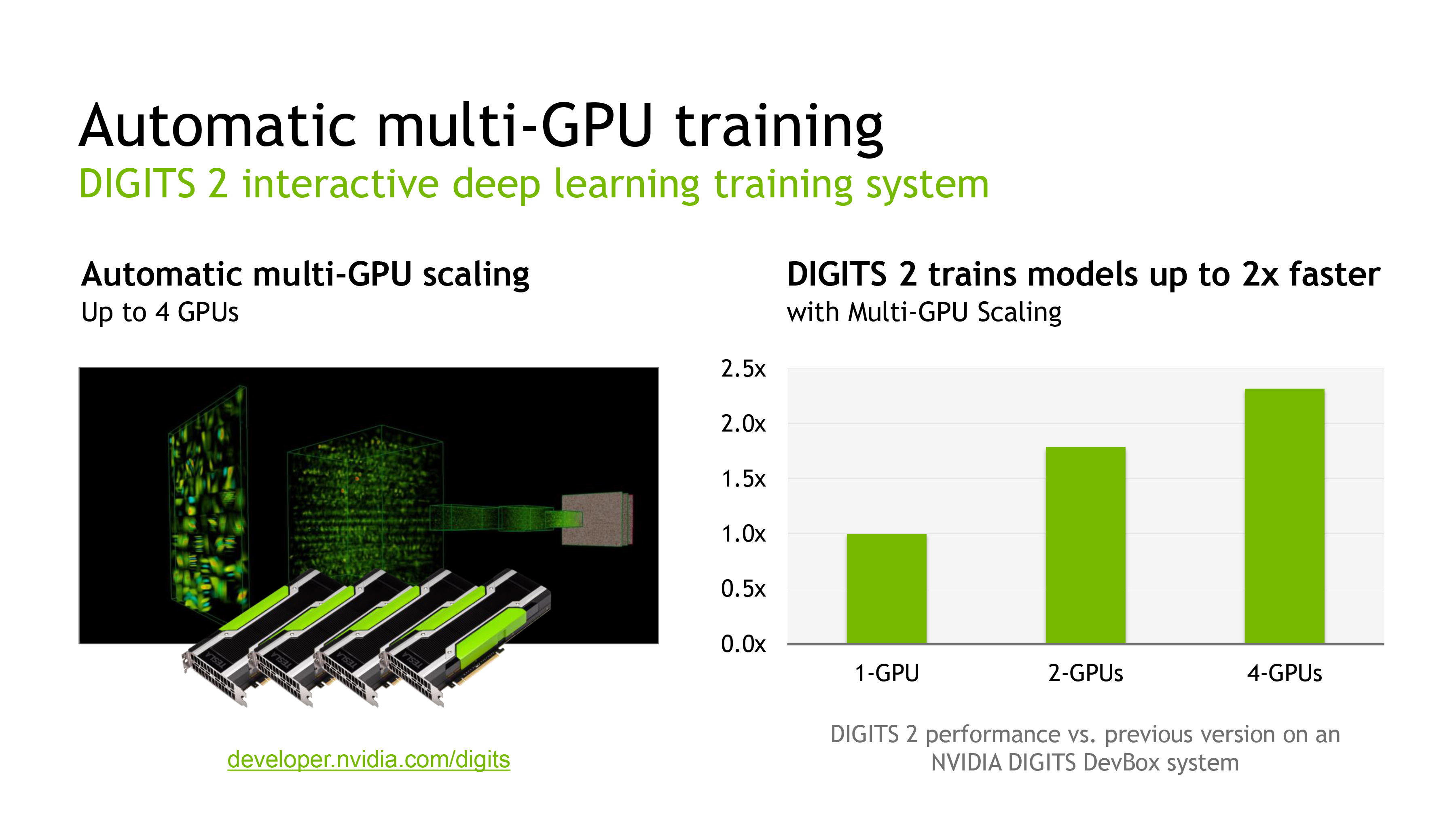
In any case, the preview release of DIGITS 2 is now available from NVIDIA, though the company has not stated when a final version will be made available.
Source: NVIDIA








26 Comments
View All Comments
saratoga4 - Wednesday, July 8, 2015 - link
When you multiply a large number on pen and paper, you don't solve every digit at once. The way we learn in grade school is to do each decimal digit (~3 bits) as one multiply and then shift/sum the result. A computer can do the same thing using 2 32 bit multiplies and some logic to combine the result.This was actually really common in the past even for 32 bit operations. The original iPhone for instance launched with a CPU that only had a 16 bit multiplier. 32 bit operations were synthesized (in hardware) by doing the first 16 bit multiply on the first cycle, and the second on the second cycle. For this reason multiplying 16 bit numbers was a lot faster then 32.
p1esk - Wednesday, July 8, 2015 - link
I'm talking about floating point, not integers.saratoga4 - Wednesday, July 8, 2015 - link
The iPhone example was for the ALU, but aside from that, yes I was referring to floating point.p1esk - Wednesday, July 8, 2015 - link
Sure, you can execute FP32 instructions with FP16 units, but I'm asking how to execute two FP16 instructions on a single FP32 unit simultaneously. I don't see how to do that without completely redesigning FP32 unit into some monstrosity that looks like two FP16 units interconnected in a complicated way. That would probably slow down the execution of native FP32 ops significantly.If you have any reference to such design I'd love to see it.
bortiz - Wednesday, July 8, 2015 - link
I don't get the problem.. Lets go to the core of the problem which is 2-16b adds going to 1 32b add. You have 2 16 bit ripple adders. You set the overflow bit of the first adder as an input to the lowest bit of the next ripple adder (ripple adders add 3 bit numbers). This portion is not complicated. Where it gets complicated is that the add now takes 2 clocks to execute as opposed to 1. The simple solution is to block all operations in 32b mode to take 2 clocks, otherwise you do have check for boundary conditions and block the specific addresses and registers being referenced to allow for pipelining, and or 16/32b operations.p1esk - Wednesday, July 8, 2015 - link
Again, you are talking about integers. I'm asking about floating point.saratoga4 - Wednesday, July 8, 2015 - link
There really isn't much difference. A floating point number is just two paired integers, a mantissa and an exponent. When you do a multiply, the mantissas are just integers that are multiplied like any other integer. The exponents are then added. Finally the resulting mantissa is renormalized and the exponent updated.So basically, what bortiz said.
p1esk - Wednesday, July 8, 2015 - link
Bortiz was talking about using two 16 bit adders to do one 32 bit addition. I'm asking about the opposite - how to use one 32 bit adder to do two 16 bit additions at once.Have you seen an FP adder? I looked at several designs, and none of them can support two additions.
saratoga4 - Thursday, July 9, 2015 - link
Logically if you can use 2 FP16 units as one FP32 unit, then you could make an FP32 unit that could do two FP16 operations at once (by just making it from two FP16 units).Did I just blow your mind ;)
p1esk - Friday, July 10, 2015 - link
You would blow my mind if you supported your statements with references. I'm not asking about what is possible to do "logically". I want to know what is actually done in real chips, more specifically, in Tegra X1. So far your guesses are as good as mine.