The Samsung Exynos 7420 Deep Dive - Inside A Modern 14nm SoC
by Andrei Frumusanu on June 29, 2015 6:00 AM ESTPower Management
Power management of previous big.LITTLE SoCs from Samsung was disappointing as it showed little signs of optimizations for efficiency and a general of attention to detail. The Exynos 7420 improves on this in several areas, some which are tied to the 14nm improvement and others which are tied to software improvements.
Modern ARM CPU’s power management works in a few different ways. Firstly, DVFS (Dynamic Voltage and Frequency Scaling) mechanisms try to optimize power efficiency by running the lowest possible frequency state without impacting performance. Because lower frequency states require lower operating voltage they intrinsically use less energy for a given fixed workload. The switching between these P-states (Performance states) is arbitrated by a so-called CPU frequency governor which works within the Linux kernel’s CPUFreq framework.
Google has since Android 4.1 Jellybean standardized the use of the “interactive” CPU governor as a part of Android and the vast amount of devices out there adopt this as the default governor, although vendors may have modifications done to it. The interactive governor is a relatively simple concept: Given a certain sampling time (20ms), it checks the load of the CPU. If the load exceeds the target load on the current frequency, then change to a frequency that would accommodate the current load within the target load threshold. The target load threshold is a parameter which describes how much % of CPU capacity we want the CPU to be at when scaling up to a certain P-state. If the load spikes too fast and much is superior to the target load, then there’s a secondary threshold called the high-speed load threshold which forcefully scales the CPUs to a fixed higher frequency, which in the case of the Exynos 7420 is respectively 900 and 1200MHz for the A53 and A57 cores. If the load has been stable and the newly computed target frequency is consistently aiming lower for 4 sample periods, meaning 80ms, it then scales back frequency to a lower state.
Samsung tries to optimize the Interactive governor to improve big.LITTLE scaling by introducing some new operating modes which alter the configurables of the interactive scaling logic on-the-fly. For example if only a single big CPU passes a load threshold of 95% it enters “single-load” mode which reduces the scaling thresholds for easier increases in frequency and also sets up a quality-of-service minimum frequency request to the small cores. I’m not too sure why they forcefully raise the frequency on the small cores when load is high on the big cores but Samsung must have profiled frequency scaling and decided that this is a beneficial change. Another mode triggered on top of the single-load mode is when the cumulative load across all 4 CPUs exceeds a certain threshold. This multi-load mode again changes scaling parameters by making them more lax and easier to scale up.
These changes had already been implemented in the Exynos 5433 as well but were never effectively used as the parameters remained at their default values and thus representing no improvement in the scaling mechanism. The Galaxy Alpha's 5430 did have the settings correctly set up, but then again Meizu's MX4Pro didn't, meaning we're either seeing an unlikely deliberate design decision, or what I find more likely and reasonable explanation, an oversight on the part of the software teams.
It looks like these modifications are mostly aimed at improving performance and reaction time of the DVFS scaling, and it looks the due to these changes the Exynos 7420 behaves much better in that regard. Samsung’s handling of frequency scaling is generally very good as the governor does well in its task. There are also a large number of QoS (Quality-of-Service) mechanisms by a variety of drivers which are able to instantly request the CPU to transition to a minimum frequency. One example is the screen touch booster: this is an independent scaling mechanism that is able to control the CPU frequency of both clusters as well as to tell the scheduler to force migrations onto the big cores for better reaction time and UI fluidity as soon as the display driver receives an interrupt request from the touch controller. Another scenario would be IP blocks in the media pipeline – blocks such as the 2D composer or the hardware video accelerator are predictable in terms of the required memory bandwidth and CPU capacity, so their drivers will dynamically put performance floors on the device’s DVFS mechanism to guarantee throughput. Samsung goes as far as to also use a QoS system for I/O bandwidth for the NAND, modem and WiFi as well as IPC (Inter-process calls) communications.
Of course beyond DVFS scaling as a power management mechanism all modern devices also offer clock- and power-gating. For the CPU this is again something which is controlled by the kernel within a mechanism called the CPUIdle framework. In the past before hardware had such power-saving mechanisms idling a system usually meant that it was running infinite loops of NOPs (no operation) until it got interrupted to do some actual work. Today instead of running inefficient idle loops, the scheduler calls the CPUIdle governor telling it to do “nothing”. The CPUIdle governor accumulates statistics on how long each idle period is and based on this data is able to choose from a variety of deeper or shallower hardware idle states. On ARM CPUs since the A15/A7 this is mostly consolidated into 3 so-called C-states: a clock-gating state called WFI (Wait-for-interrupt), an individual core power-gating state and a cluster power-gating state.
WFI is an instruction-level and architectural power-management state with extremely low latency that stops the clock to a given CPU. By stopping the clock one avoids dynamic leakage by the CPU, so this is a crucial part of doing “nothing” in mobile CPUs. Individual core power-gating states are able to turn off power to the CPU this way. This is a deeper state as the CPU needs to save its state upon entry and restore it upon waking up. On the 7420 we’re talking about exit latencies of 100µs. Because of the overhead of restoring the CPU state, it’s also not worth to enter these modes for reduced periods of time (called residency time). For the A57 cores this residency threshold is 2000µs and for the A53 cores 750µs. When all cores within a cluster are idle the whole cluster is allowed to be powered down. This of course has larger overhead with larger exit latencies (300µs) and greater minimal residency times (5ms). The cluster power-down is largely used on the big cluster as the small cluster is only allowed to power itself down when the screen is off. A very low-hanging fruit which has finally been picked by Samsung is to have optimized configuration values for each cluster. Previous Samsung SoCs would oddly just use a single driver with the same settings for both clusters, which didn’t make much sense and likely impacted CPU idle efficiency.
The 14nm process seems to have introduced a change in dynamic between the two CPU clusters as the efficiency of each cluster has scaled differently. This has significant impact in the way the GTS scheduler settings are set up as the new chipset’s power efficiency curves are tighter to each-other when compared to the Exynos 5433. To demonstrate this, I took the SPECint2000 scores of each cluster to determine what the IPC difference between the two architectures is and then used this as a ratio to normalize the A57 perf/W curve to the A53’s clocks. On the first set of charts the vertical axis is just an arbitrary normalized value of MHz/mW for the A53 cores, and the A57 curve uses a multiplier ratio of 2.09 to scale the efficiency value and thus represent the IPC increase of the larger architecture.
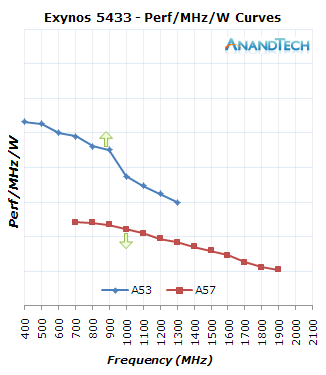
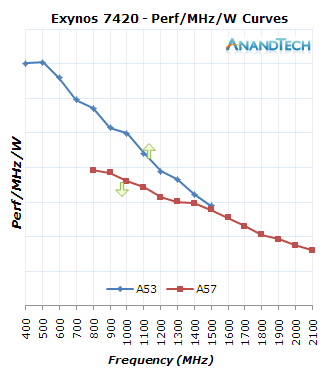
I’ll get back to actual perf/W charts in just a bit, but first I want to explain why the perf/MHz/W curves are an important metric we can deduce a lot from. Currently the Linux kernel and GTS mechanism sees load on a frequency invariant scale; what this means that if a process takes up 50% of the CPU while it’s running at 500MHz and its maximal scaling frequency is 1GHz, the scheduler will account the task as a 25% load on that CPU. This mechanism is meant to normalize current load to the maximum possible capacity of a CPU, and not just the current one.
The trigger points that determine thread migrations in GTS are called the up- and down-thresholds, which are thresholds on the load scales of the CPUs. For the Exynos 5433 Samsung used 50% and 25% as the up- and down-thresholds. When a thread would exceed 50% of the A53’s capacity it would be migrated over to the big cores, and once on the big core if the task would fall below 25%’s of the CPU’s capacity it would then migrate down. On the 7420 these values are set up slightly differently as Samsung configured the default values at 46.7% and 20.8%. At first I was confused to see such specific values and didn’t fully understand why they were set up as such until I calculated the actual performance/W curves of both CPU cluster.
One will have noticed the arrows I put on the graphs – these represent the theoretical point where a thread should migrate up to the big core, or down to the little cores. For the very attentive readers they will notice that the up threshold arrows aren’t at the mentioned 50 and 46% frequency points of the little cores. This is because the CPU frequency governor should actually be able to scale up frequency faster than the task triggering a scheduler migration by hitting the normalized up-threshold. For example 50% up-threshold of the 5433 would mean a 100% load at 800MHz of the A53 cores, but that will realistically never happen as the CPU will have scaled up to a higher frequency by then. The 5433 governor will try to maintain 10% of idle capacity when scaling to a frequency while the 7420 seeks 25%, meaning the latter has more lax settings which make it scale higher in frequency even though the load doesn’t require it. The result is that the avarage effective performance/capacity point where the little CPUs will try to migrate to the big cores is slightly below 900MHz for the 5433 and just above 1100MHz for the 7420.
For the down-threshold of the big cores the logic is a tad simpler because the scaling-down mechanism of the frequency governor is slower than the scheduler’s migration mechanism. This means that the arrow depicted in the graphs is a minimal value of when a thread will migrate down, and a down-migration might happen anytime at the higher frequencies.
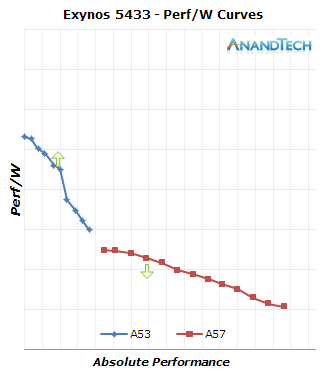
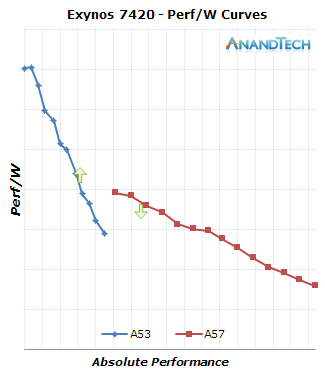
When plotting the efficiency points on an axis depicting the absolute performance of the cores we get a much clearer picture of what big.LITTLE is supposed to achieve. And this is where we see a large difference between the 5433 and 7420: The way the Note 4 is currently set up makes it migrate up threads sooner than compared to the Galaxy S6 and the efficiency degradation when doing so is much greater. An optimal implementation would be a device where the up- and down-migration points would be as close as possible to each other in the efficiency axis while having a slight jump in the performance axis acting as a hysteresis to avoid migrations when a load falls in between the two performance curves.
It seems to me that Samsung paid much better attention to efficiency optimizations on the Exynos 7420’s software as it fixes many of the weird configuration issues of the Note 4 Exynos. The Exynos 7420 joins the Exynos 5430 (And MediaTek’s MT6595 which I’ll hopefully address sometime soon) as one of the rare SoCs which are able to reign in ARM’s big CPU core designs in a small form-factor mobile device and effectively use big.LITTLE without major downsides. While Samsung’s software stack could definitely improve with features such as full energy awareness inside the scheduler, it's no longer as misconfigured and as bad as I decribed it in the Exynos 5433 review.
In terms of maximum power consumption, I think 1.9GHz would have been a slightly more reasonable cap for the A57 cores as the device can on some occasions such as updating many apps or visiting a very heavy ad-ridden site can load up the big CPUs to their full capacity and make the device run a bit hot, but it’s a rare occasion and the vast majority of processing time is spent on the lower frequencies. It will be interesting to see what ARM's A72 processor core will be able to achieve in terms of performance and power efficiency. For 2015 though it seems Samsung's A57 SoC still remains king due to its process node advantage.








114 Comments
View All Comments
Andrei Frumusanu - Monday, June 29, 2015 - link
Frankly, I don't know. I tried to ask Samsung a similar question but they refused to comment on customer relations. Meizu so far seems to be the only major vendor consistently using Exynos parts but as to why we haven't seen other vendors adopt them can be attributed to anything going from pricing to volume availability. Only the companies themselves know the details of these contracts.gnx - Monday, June 29, 2015 - link
Thanks! The SoC market is really strange.id4andrei - Monday, June 29, 2015 - link
This is Samsung's chance to eat Qualcomm's lunch. Close down node manufacturing for others(including Apple) and be like Intel. Either use Exynos or be satisfied with inferior nodes from other fabs.CiccioB - Monday, June 29, 2015 - link
And that meas start competing with PP only, like Intel did.That is, if you force others to go to other foundries, you have to be sure you have the best one, or in case TMSC comes up with a better PP (like a 16+nm revision) you have just thrown all your customers to your fab competitors, making double damage (or total one). Or just think if Intel tomorrow suddenly opens to ARM customers in order to saturate it's now rusting 14nm machineries. Samsung would be in great trouble after that eventual (and IMHO stupid) move.
Investing in PP i really expensive and there are other foundries capable of doing so. Samsung can't be sure to always be the best one on the market. And invest tons of billions of dollar every year to make sure to be the number one (for SoC of course).
ZeDestructor - Wednesday, July 1, 2015 - link
Samsung is part of a common platform alliance/agreement with GloFo, so while they could lock down and close others out, GloFo would not, so there's little commercial benefit from doing so.They could of course coerce GloFo into doing the same, but that lands them into hot water with regulatory watchdogs like the FTC regarding anti-competitive practices and collusion, which while Samsung wouldn't really mind (no, really), GloFo would.
eh_ch - Monday, June 29, 2015 - link
How will it take for Samsung's process to trickle down to AMD via GloFo? Could it bridge the efficiency gap to nvidia / Intel? Holding out hope that ATI/MD will be competitive once more.eh_ch - Monday, June 29, 2015 - link
How long will it take, that isAdding-Color - Monday, June 29, 2015 - link
No, AMD won't have a technology advantage to Nvidia on next gen GPUs, currently it looks like nvidia will choose Samsung for their next node, and as Samsung and GloFo jav some kind of alliance and share processes (glofo licenses some Samsung processes AFAIK, the technology should be very similar for both, yet AMD should have a small HBM advantage, they have better relations to hynix (and helped to develop HBM) than nvidia.jjj - Monday, June 29, 2015 - link
There won't be a HBM advantage from a technological point of view, at best AMD could get slightly better pricing but even that is unlikely since Nvidia has much higher volume. The first gen HBM was late and both Nvidia and AMD had plenty of time to prepare for it.As for the process, we don't really know what foundry each will use and what version of the process.On the GPU side both are more likely to go TSMC or use both. On the CPU side AMD will likely go GloFo but not this early version of the process and Intel might go 10nm not long after AMD has 14nm. On 10nm TSMC and Samsung do seem to be catching up with Intel but doubt AMD will have 10nm early.
fluxtatic - Tuesday, June 30, 2015 - link
Hell, at this point I'd be happy to see AMD at < 28nm