AMD Launches Carrizo: The Laptop Leap of Efficiency and Architecture Updates
by Ian Cutress on June 2, 2015 9:00 PM ESTIPC Increases: Double L1 Data Cache, Better Branch Prediction
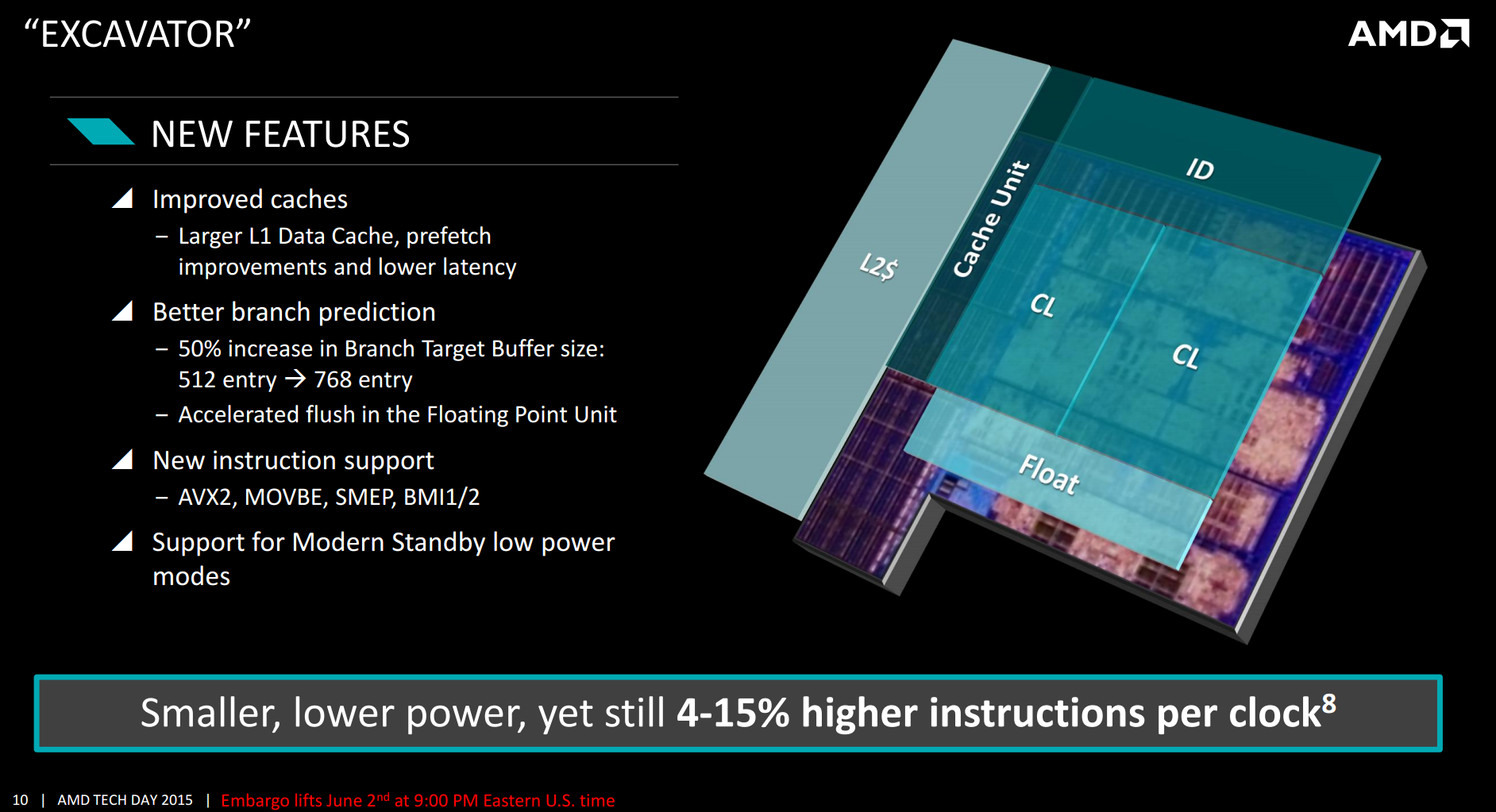
One of the biggest changes in the design is the increase in the L1 data cache, doubling its size from 64 KB to 128 KB while keeping the same efficiency. This is combined with a better prefetch pipeline and branch prediction to reduce the level of cache misses in the design. The L1 data cache is also now an 8-way associative design, but with the better branch prediction when needed it will only activate the one segment required and when possible power down the rest. This includes removing extra data from 64-bit word constructions. This reduces power consumption by up to 2x, along with better clock gating and minor adjustments. It is worth pointing out that doubling the L1 cache is not always easy – it needs to be close to the branch predictors and prefetch buffers in order to be effective, but it also requires space. By using the high density libraries this was achieved, as well as prioritizing lower level cache. Another element is the latency, which normally has to be increased when a cache increases in size, although AMD did not elaborate into how this was performed.
As listed above, the branch prediction benefits come about through a 50% increase in the BTB size. This allows the buffer to store more historic records of previous interactions, increasing the likelihood of a prefetch if similar work is in motion. If this requires floating point data, the FP port can initiate a quicker flush required to loop data back into the next command. Support for new instructions is not new, though AVX2 is something a number of high end software packages will be interested in using in the future.
These changes, according to AMD, relate to a 4-15% higher IPC for Excavator in Carrizo compared to Steamroller in Kaveri. This is perhaps a little more what we normally would expect from a generational increase (4-8% is more normal), but AMD likes to stress that this comes in addition to lower power consumption and with a reduced die area. As a result, at the same power Carrizo can have both an IPC advantage and a frequency advantage.
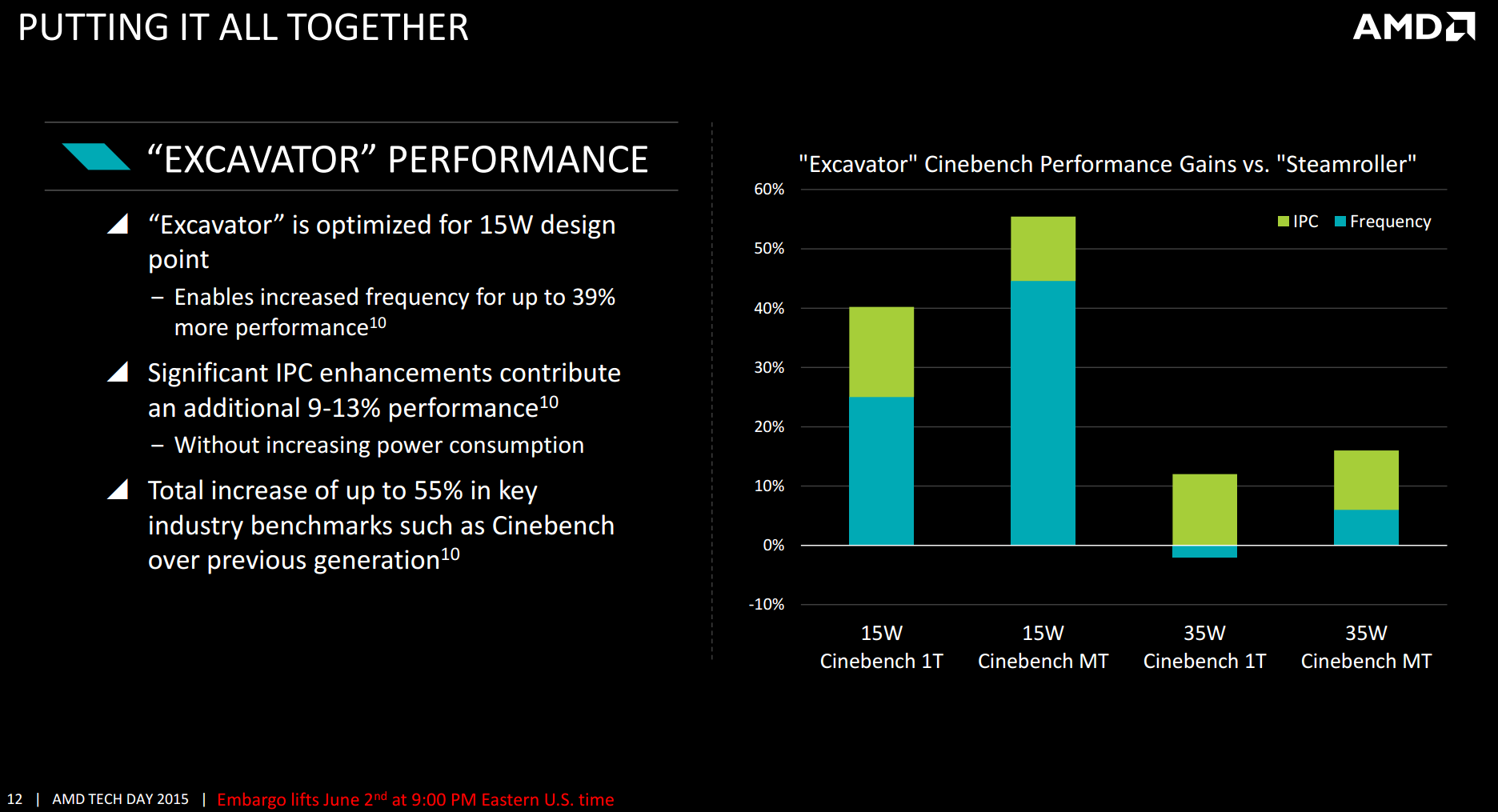
As a result, AMD states that for the same power, Cinebench single threaded results will go up 40% and multithreaded results up 55%. The benefits are fewer however the further up the power band you go despite the increase, as the higher density libraries perform slightly worse at higher power than Kaveri.








137 Comments
View All Comments
name99 - Saturday, June 6, 2015 - link
You are comparing a $400 laptop to a $1500 laptop and, what do you know, the $1500 laptop comes out better. What a surprise!The point is that in this space batteries have long been cheap and the energy efficiency nothing like at the higher end. Which means the work-life has been something like 3 hrs. If AMD shifts that to six hours with this chip, that's a massive improvement in the target space.
You're also making bad assumptions about why these laptops are bought. If you rely on your laptop heavily for your job, you buy a $1500 laptop. These machines are bought to act as light performance desk machines that are occasionally (but only occasionally) taken to a conference room or on a field trip.
name99 - Saturday, June 6, 2015 - link
AMD does not have infinite resources. This play makes sense.Intel is essentially operating by starting with a Xeon design point and progressively stripping things out to get to Broadwell-M, which means that Broadwell-M over-supplies this $400-$700 market. Meanwhile at the really low end, Intel has Atom.
AMD is seeing (correctly, I think) that there is something of a gap in the Intel line which they can cover AND that this gap will probably persist for some time --- Intel isn't going to create a third line just to fit that gap.
Krysto - Wednesday, June 3, 2015 - link
I might be ready to get into AMD, as AMD has a lot of innovation lately. But it still disappoints me greatly that they aren't able to adopt a more modern process node.If they launch their new high-performance CPU core next year as part of an APU that uses HBM memory and is at the very least on 16nm FinFET, I might get that instead of a Skylake laptop. HSA is pretty cool and one of the reasons I'd get it.
UtilityMax - Wednesday, June 3, 2015 - link
The Kaveri FX parts are still almost half as slow in IPC as a competing Intel Core i3 with the same TDP. Only in tests involving multithreaded apps that can load all four cores the FX parts are keeping up with the Core i3. Let's hope the Carrizo generation of APUs will improve this situation.silverblue - Thursday, June 4, 2015 - link
Without being an AMD apologist, I think the point was that single threaded performance was "good enough" for your usual light work which tends to be hamstrung by I/O anyway.There are two things that I need to see clarified about Carrizo, however:
1) Does Carrizo drop CPU frequency automatically when the GPU is being taxed? That's certainly going to be an issue as regards the comparison with an i3.
2) With the addition of AVX2, were there any architectural changes made to accommodate AVX2, for example a wider FlexFPU?
sonicmerlin - Tuesday, June 9, 2015 - link
Yup. I'll wait for the 14 nm Zen APUs with HBM. The performance leap (both CPU and GPU) should be truly massive.Phartindust - Thursday, June 4, 2015 - link
Dude your gettin a Dell with a AMD processor!When was the last time that happened?
Looks like @Dell loves #Carrizo, and will use @AMD once again. #AMDRTP http://www.cnet.com/au/news/dell-inspirion-amd-car... …
elabdump - Friday, June 5, 2015 - link
Don't forget that Intel gives you an non fixable NSA approved BIOS: http://mjg59.dreamwidth.org/33981.htmlpatrickjchase - Friday, June 5, 2015 - link
Ian, you appear to have confused I-cache and D-cache.You wrote: "The L1 data cache is also now an 8-way associative design, but with the better branch prediction when needed it will only activate the one segment required and when possible power down the rest".
This is of course gibberish. Branch prediction would help to predict the target set of an *instruction* fetch from the I-cache, but is useless for D-cache set prediction for the most part (I say "for the most part" because Brad Calder did publish a way-prediction scheme based on instruction address back in the 90s. It didn't work very well and hasn't been productized that I know of).
zodiacfml - Friday, June 5, 2015 - link
Imagine what they could with 14nm of this, probably at half the cost of a Core M with 60 to 70% CPU performance of the M, yet with better graphics at the same TDP.