The Intel Xeon D Review: Performance Per Watt Server SoC Champion?
by Johan De Gelas on June 23, 2015 8:35 AM EST- Posted in
- CPUs
- Intel
- Xeon-D
- Broadwell-DE
Memory Subsystem: Latency
To measure latency, we use the open source TinyMemBench benchmark. The source was compiled for x86 with gcc 4.8.2 and optimization was set to "-O2". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests. To keep the graph readable we limited ourselves to the CPUs that were different.
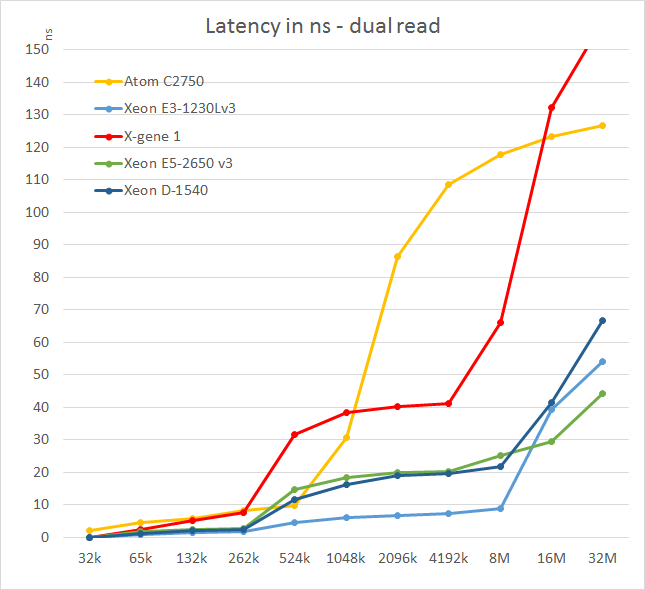
L3 caches have increased significantly the past years, but it is not all good news. The L3 cache of the Xeon E3 responds very quickly (about 10 ns or less than 30 cycles at 2.8 GHz) while the L3-cache of the new generation needs almost twice as much time to respond (about 20 ns or 50 cycles at 2.6 GHz). Larger L3 caches are not always a blessing and can result in a hit to latency - there are applications that have a relatively small part of cacheable data/instructions such as search engines and HPC application that work on huge amounts of data.
It gets worse for the "large L3 cache" models when we look at latency of accessing memory (measured at 64 MB):
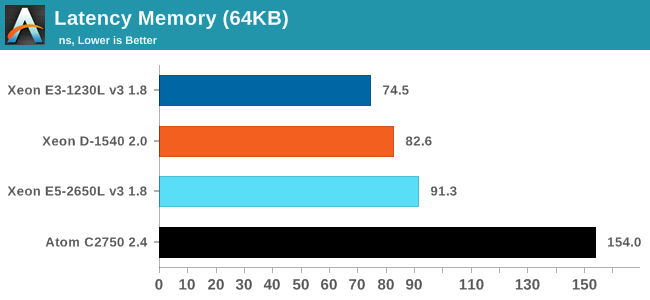
The higher L3-cache latency makes memory accesses more costly in terms of latency for the Xeon E5. Despite having access to DDR4-2133 DIMMs, the Xeon E5-2650L accesses memory slower than the Xeon E3-1230L. It is also a major weakness of the Atom C2750 which has much less sophisticated memory controller/prefetching.








90 Comments
View All Comments
Flunk - Tuesday, June 23, 2015 - link
Yes, but it's still bad marketing. -D is associated with inferior, overly hot, bad performing Intel chips.IanHagen - Tuesday, June 23, 2015 - link
Certainly. From a marketing standpoint it's a pretty poor choice. I agree with wussupi, E4 would haven been a far better name.karpodiem - Tuesday, June 23, 2015 - link
does anyone know where to buy these online? I'm looking for just the board/processor, model # 'X10SDV-TLN4F'All these random/small Supermicro resellers are selling it now, based on some Google searches. They're marking it up in price by at least a hundred bucks, because availability is limited. Anyone know when Newegg might get it in stock?
Looking to do a FreeNAS build - this board + IBM M1015 card in an ATX motherboard (6x4TB drives in RAIDZ2).
ats - Tuesday, June 23, 2015 - link
The TLN4F is the one in most demand and almost no place is able to keep it in stock. There are multiple places that will order it for you for ~1K but wait times can be anywhere from 1 week to 1 month.Jon Tseng - Tuesday, June 23, 2015 - link
> And the reality is that the current SoCs with an ARM ISA do not deliver the necessary per core> performance: they are still micro server SoCs, at best competing with the Atom C2750. So
> currently, there is no ARM SoC competition in the scale out market until something better than
> the A57 hits the market for these big players.
Dude... You really want to have a look at the latest ThunderX parts or the X-Gene 16nm shrinks before you start making unwise statements like that. These aren't waiting around for A57 they are custom ARM architecture designs. Per core performance might not be as hot as Xeon but once you start to throw 48 cores on a die I wouldn't quite call that "at best competing with Avaton".
smoohta - Tuesday, June 23, 2015 - link
Link to reviews?ats - Tuesday, June 23, 2015 - link
X-Gene is in the article, any further shrinks are still entirely vapor. ThunderX isn't currently available is is likely to have significantly worse per core performance than Atom C2k series and worse than A57. All the cores in the world don't do jack if the ST isn't there. And ST performance IS a barrier even in scale out. For general scale out, C2750 was found fairly wanting because of the ST performance, and neither X-Gene nor ThunderX even compete with C2750 in ST performance... QED.mczak - Tuesday, June 23, 2015 - link
He said "currently". The X-Gene 16nm cores might offer some competition who knows - but those are X-Gene 3 whereas you can't even buy anything with X-Gene 2 28nm ones right now... Likewise, ThunderX servers have been announced, but I haven't seen any reviews yet.name99 - Tuesday, June 23, 2015 - link
Look at the ThunderX parts HOW? Cavium releases fsck-all information about them. No-one knows if they are even OoO, how wide they are, etc.Yes, there are 48 cores on a SoC; and presumably they will do well for tasks like memcached that like lots of low-performance parallelism. But right now, we have ZERO evidence that a ThunderX part is a better single-threaded core than A57, let alone that it's comparable to Broadwell.
der - Tuesday, June 23, 2015 - link
NOICE FAM!