Exploring DirectX 12: 3DMark API Overhead Feature Test
by Ryan Smith & Ian Cutress on March 27, 2015 8:00 AM EST- Posted in
- GPUs
- Radeon
- Futuremark
- GeForce
- 3DMark
- DirectX 12
Discrete GPU Testing
We’ll kick things off with our discrete GPUs, which should present us with a best case scenario for DirectX 12 from a hardware standpoint. With the most powerful CPUs powering the most powerful GPUs, the ability to generate a massive number of draw calls and to have them consumed in equally large number, this is where DirectX 12 will be at its best.
We’ll start with a look a CPU scaling on our discrete GPUs. How much benefit do we see going from 2 to 4 and finally 6 CPU cores?
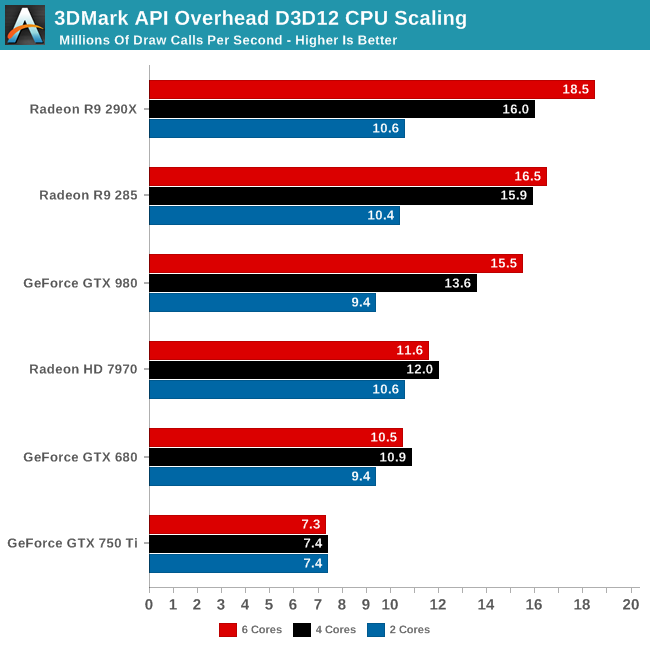
The answer on the CPU side is quite a lot. Whereas Star Swarm generally topped out at 4 cores – after which it was often GPU limited – we see gains all the way up to 6 cores on our most powerful cards. This is a simple but important reminder of the fact that the AOFT is a synthetic test designed specifically to push draw calls and avoid all other bottlenecks as much as possible, leading to increased CPU scalability.
With that said, it’s clear that we’re reaching the limits of our GPUs with 6 cores. While the gains from 2 to 4 cores are rather significant, increasing from 4 to 6 (and with a slight bump in clockspeed) is much more muted, even with our most powerful cards. Meanwhile anything slower than a Radeon R9 285X is showing no real scaling from 4 to 6 cores, indicating a rough cutoff right now of how powerful a card needs to be to take advantage of more than 4 cores.
Moving on, let’s take a look at the actual API performance scaling characteristics at 6, 4, and 2 cores.
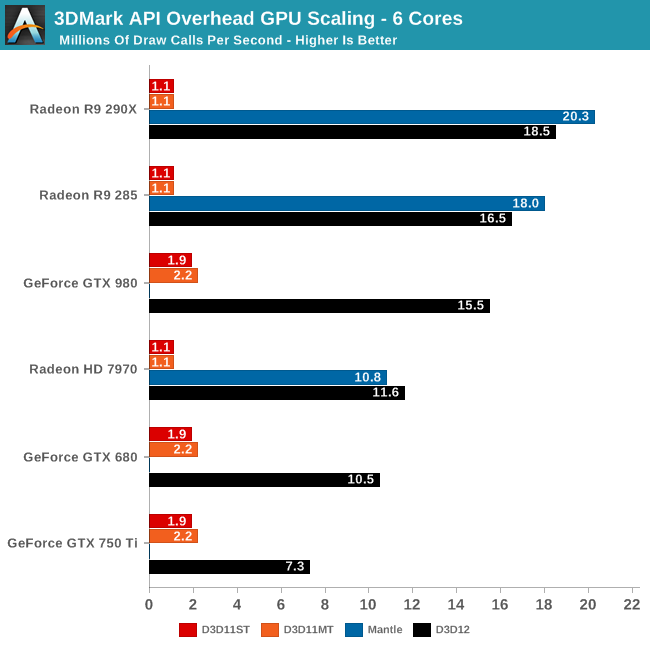
6 cores of course is a best case scenario for DirectX 12 – it’s the least likely to be CPU-bound – and we see first-hand the incredible increase in draw call throughput by switching from DirectX 11 to DirectX 12 or Mantle.
Somewhat unexpectedly, the greatest gains and the highest absolute performnace are achieved by AMD’s Radeon R9 290X. As we saw in Star Swarm and continue to see here, AMD’s DirectX 11 throughput is relatively poor, topping out at 1.1 draw calls for both DX11ST and DX11MT. AMD simply isn’t able to push much more than that many calls through their drivers, and without real support for DX11 multi-threading (e.g. DX11 Dirver Command Lists), they gain nothing from the DX11MT test.
But on the opposite side of the coin, this means they have the most to gain from DirectX 12. The R9 290X sees a 16.8x increase in draw call throughput switching from DX11 to DX12. At 18.5 million draw calls per second this is the highest draw call rate out of any of our cards, and we have good reason to suspect that we’re GPU command processor limited at this point. Which is to say that our CPU could push yet more draw calls if only a GPU existed that could consumer that many calls. On a side note, 18.5M calls would break down to just over 300K calls per frame at 60fps, which is a similarly insane number compared to today’s standards where draw calls per frame in most games is rarely over 10K.
Meanwhile we see a reduction in gains going from the 290X to the 285 and finally to the 7970. As we mentioned earlier we appear to be command processor limited, and each one of these progressively weaker GPUs appears to contain a similarly weaker command processor. Still, even the “lowly” 7970 can push 11.6M draw calls per second, which is a 10.5x (order of magnitude) increase in draw call performance over DirectX 11.
Mantle on the other hand presents an interesting aside. As AMD’s in-house API (and forerunner to Vulkan), the AMD cards do even better on Mantle than they do DirectX 12. At this point the difference is somewhat academic – what are you going to do with 20.3M draw calls over 18.5M – but it goes to show that Mantle can still squeeze out a bit more at times. It will be interesting to see whether this holds as Windows 10 and the drivers are finalized, and even longer term whether these benefits are retained by Vulkan.
As for the NVIDIA cards, NVIDIA sees neither quite the awesome relative performance gains from DirectX 12 nor enough absolute performance to top the charts, but here too we see the benefits of DirectX 12 in full force. At 1.9M draw calls per second in DX11ST and 2.2M draw calls per second in DX11MT, NVIDIA starts out in a much better position than AMD does; in the latter they essentially can double AMD’s DX11MT throughput (or alternatively have half the API overhead).
Once DX12 comes into play though, NVIDIA’s throughput rockets through the roof as well. The GTX 980 sees an 8.2x increase over DX11ST, and a 7x increase over DX11MT. On an absolute basis the GTX 980 is consuming 15.5M draw calls per second (or about 250K per frame at 60fps), showing that even the best DX11 implementation can’t hold a candle to this early DirectX 12 implementation. The benefits of DirectX 12 really are that great for draw call performance.
Like AMD, NVIDIA seems to be command processor limited here. GPU-Z reports 100% GPU usage in the DX12 test, indicating that by NVIDIA’s internal metrics the card is working as hard as it can. Meanwhile though not charted, I also tested a GTX Titan X here, which achieved virtually the exact same results as the GTX 980. In lieu of more evidence to support being CPU bound, I have to assume that the GM200 GPU uses a similar command processor as the GM204 based GTX 980, leading to a similar bottleneck. Which would make some sense, as the GM200 is by all practical measurements a supersized version of GM204.
Moving down the NVIDIA lineup, we see performance decrease as we work towards the GTX 680 and GTX 750 Ti. The latter is a newer product, based on the GM107 GPU, but ultimately it is a smaller and lower performing GPU than the GTX 680. Regardless, we are hitting the lower command processor throughput limits of these cards, and seeing the maximum DX12 throughput decrease accordingly. This means that the relative gains are smaller – DX11 performance is virtually the same as GTX 980 since the CPU is the limit there – but even GTX 750 Ti sees a 3.8x increase in throughput over DX11ST.
Finally, it’s here where we’re seeing a distinct case of the DX11 test producing variable results. For the NVIDIA cards we have seen our results fluctuate between 1.4M and 1.9M. Of all of our runs 1.9M is more common – not to mention it’s close to the score we get on NVIDIA’s public WDDM 1.3 drivers – so it’s what we’re publishing here. However for whatever reason, 1.4M will become more common with fewer cores even though the bottleneck was (and remains) single-core performance.
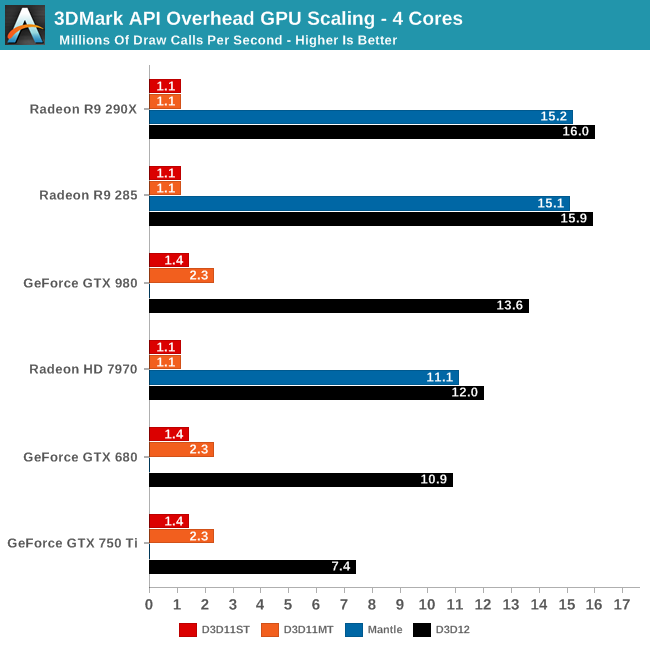
As for performance scaling with 4 cores, it’s very similar to what we saw with 6 cores. As we noted in our CPU-centric look at our data, only the fastest cards benefit from 6 cores, so the performance we see with 4 cores is quite similar to what we saw before. AMD of course still sees the greatest gains, while overall the gap between AMD and NVIDIA is compressed some.
Interestingly Mantle’s performance advantage melts away here. DirectX 12 is now the fastest API for all AMD cards, indicating that DX12 scales out better to 4 cores than Mantle, but perhaps not as well to 6 cores.
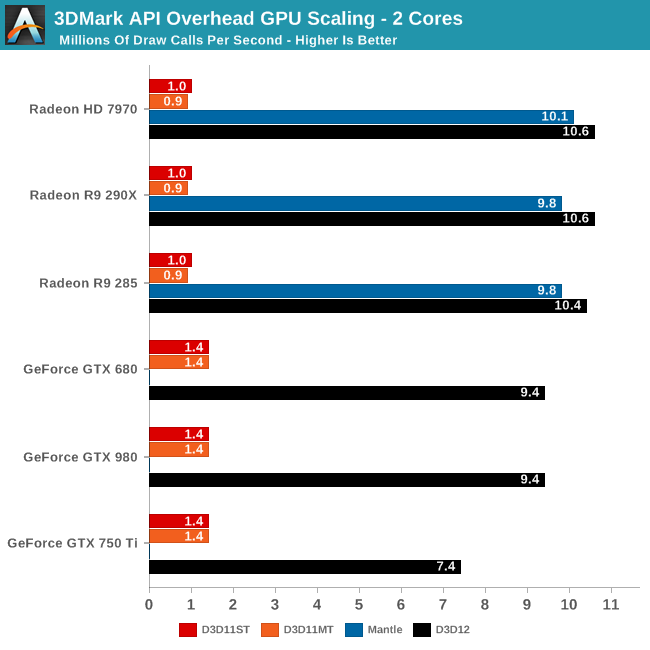
Finally with 2 cores many of our configurations are CPU limited. The baseline changes a bit – DX11MT ceases to be effective since 1 core must be reserved for the display driver – and the fastest cards have lost quite a bit of performance here. None the less, the AMD cards can still hit 10M+ draw calls per second with just 2 cores, and the GTX 980/680 are close behind at 9.4M draw calls per second. Which is again a minimum 6.7x increase in draw call throughput versus DirectX 11, showing that even on relatively low performance CPUs the draw call gains from DirectX 12 are substantial.
Overall then, with 6 CPU cores in play AMD appears to have an edge in command processor performance, allowing them to sustain a higher draw call throughput than NVIDIA. That said, as we know the real world performance of the GTX 980 easily surpasses the R9 290X, which is why it’s important to remember that this is a synthetic benchmark. Meanwhile at 2 cores where we become distinctly CPU limited, AMD appears to still have an edge in DirectX 12 throughput, an interesting role reversal from their poorer DirectX 11 performance.








113 Comments
View All Comments
tipoo - Friday, March 27, 2015 - link
4X gains seen herehttp://www.pcworld.com/article/2900814/tested-dire...
Ryan Smith - Friday, March 27, 2015 - link
Sorry, that was an error in that table. We didn't have the 4770R for this article.geekfool - Saturday, March 28, 2015 - link
hhm pcw says " All of our tests were performed at 1280x720 resolution at Microsoft's recommendation."if that's the case with your tests too then its seems that the real test today should be 1080p and a provisional 4k/UHD1 to get a set of future core numbers regardless of MS's wishes...
Ryan Smith - Sunday, March 29, 2015 - link
720p is the internal rendering resolution, and is used to avoid potential ROP bottlenecks (especially at the early stages). This is supposed to be a directed, synthetic benchmark, and the ability to push pixels is not what is intended to be tested.That said, the actual performance impact from switching resolutions on most of these GPUs is virtually nil since there's more than enough ROP throughput for all of this.
Winterblade - Friday, March 27, 2015 - link
Very interesting results, and very informative article, the only small caveat I find is that for proper comparison of 2, 4 and 6 cores (seems to be one of the focal points of the article) the clock should be the same for all 3 configurations, it is a bit misleading otherwise. The difference seems to be around 10 - 15% in going from 4 to 6 cores but there is also a 10% difference in clock rate between them.chizow - Friday, March 27, 2015 - link
Fair point, it almost looks like they are trying to artifically force some contrast in the results there. Biggest issue I have with that is you are more likely to find higher clocked 4-cores in the wild since they tend to overclock better than the TDP and size limited 6-core chips.That's the tradeoff any power-user faces there, higher overclock on that 4790K (and soon Broadwell-K) chip or the higher L3 cache and more cores of a 6-core chip with lower OC potential.
dragonsqrrl - Friday, March 27, 2015 - link
I got 1.7M draw calls per second with an i7-970 and GTX480 in DX11, and 2.3M in DX11MT. Pretty much identical to every other Nvidia card benchmarked. Interested to see what kind of draw call gains I get with a 480 once Windows 10 and DX12 come out with finalized drivers.godrilla - Friday, March 27, 2015 - link
Vulkan seems more attractive for devs though.The battle of the APIs incoming.
junky77 - Friday, March 27, 2015 - link
Well, currently, the limiting factor is almost always the GPU, with with a powerful GPU, unless we are talking AMD CPUs which are TDP limtied in many cases or an I3 and even then the differences are not greatSo, I think that it's mainly a look for the future, allowing higher draws scenes, potentially
Mat3 - Friday, March 27, 2015 - link
Would be interesting to see how the FX-8350 compares to the i7-4960X for this test.