NVIDIA GTC 2015 Keynote Live Blog
by Ryan Smith on March 17, 2015 12:10 PM EST- Posted in
- GPUs
- Trade Shows
- NVIDIA
- GTC 2015

02:12PM EDT - And we're done here
02:11PM EDT - Wrap-up

02:10PM EDT - Elon and Jen-Hsun are wrapping up

02:08PM EDT - Multiple levels of security. Infotainment and actual driving controls are separated
02:07PM EDT - Now discussing car hacking
02:00PM EDT - Fast and slow is easy. Mid-speed is hard
02:00PM EDT - Discussing how various speeds are easier or harder
01:55PM EDT - Even if self-driving cars become a viable product, it will take 20 years to replace the car fleet
01:54PM EDT - Jen-Hsun and Elon are discussing the potential and benefits of self-driving cars
01:53PM EDT - Musk responds that he's more worried about "strong" AI, and not specialty AI like self-driving cars
01:52PM EDT - Jen-Hsun is grilling Musk on some of his previous comments on the danger of artificial intelligence

01:51PM EDT - Tesla meets Tesla
01:50PM EDT - Now on stage: Elon Musk

01:49PM EDT - Drive PX dev kit available in May, $10,000

01:46PM EDT - Jen-Hsun has a Drive PX in hand



01:42PM EDT - The key to training cars is not to train them low-level physics, but to train them the high-level apect of how the world works and how humans behave
01:42PM EDT - How do you make a car analogy when you're already talking about cars? With a baby analogy
01:39PM EDT - I for one am all for more Freespace
01:39PM EDT - Jen-Hsun talking about how free space is important to understand in a self-driving car

01:36PM EDT - Recapping the Drive PX system
01:36PM EDT - NVIDIA's vision: to augment ADAS with GPU deep learning

01:35PM EDT - Final subject of the day: self-driving cars
01:34PM EDT - And we're done with roadmaps. Looks like no updates on the Tegra roadmap
01:32PM EDT - 28 TFLOPS FP32
01:32PM EDT - DIGITS DevBox: 1300W
01:30PM EDT - Now Jen-Hsun is explaining why he thinks Pascal will offer 10x the performance of Maxwell, by combining the FP16 performance gains with other improvements in memory bandwidth and better interconnect performance through NVLink
01:29PM EDT - FP16 is quite imprecise, but NV seems convinced it can still be useful for neural network convolution


01:28PM EDT - Pascal has 3x the memory bandwidth of Maxwell. This would put memory bandwidth at 1TB/sec
01:28PM EDT - It sounds like Pascal will come with Tegra X1's FP16 performance improvements

01:27PM EDT - Mixed precision: discussing the use of FP16
01:27PM EDT - 4x the mixed precision performance of Maxwell
01:26PM EDT - Pascal offers 2x the perf per watt of Maxwell


01:26PM EDT - Also reiterating the fact that Pascal will be the first NVIDIA GPU with 3D memory and NVLink
01:25PM EDT - New feature: mixed precision
01:25PM EDT - Roadmap update on Pascal and Volta
01:24PM EDT - Now: roadmaps
01:23PM EDT - NVIDIA is building them one at a time
01:23PM EDT - $15,000, available May 2015
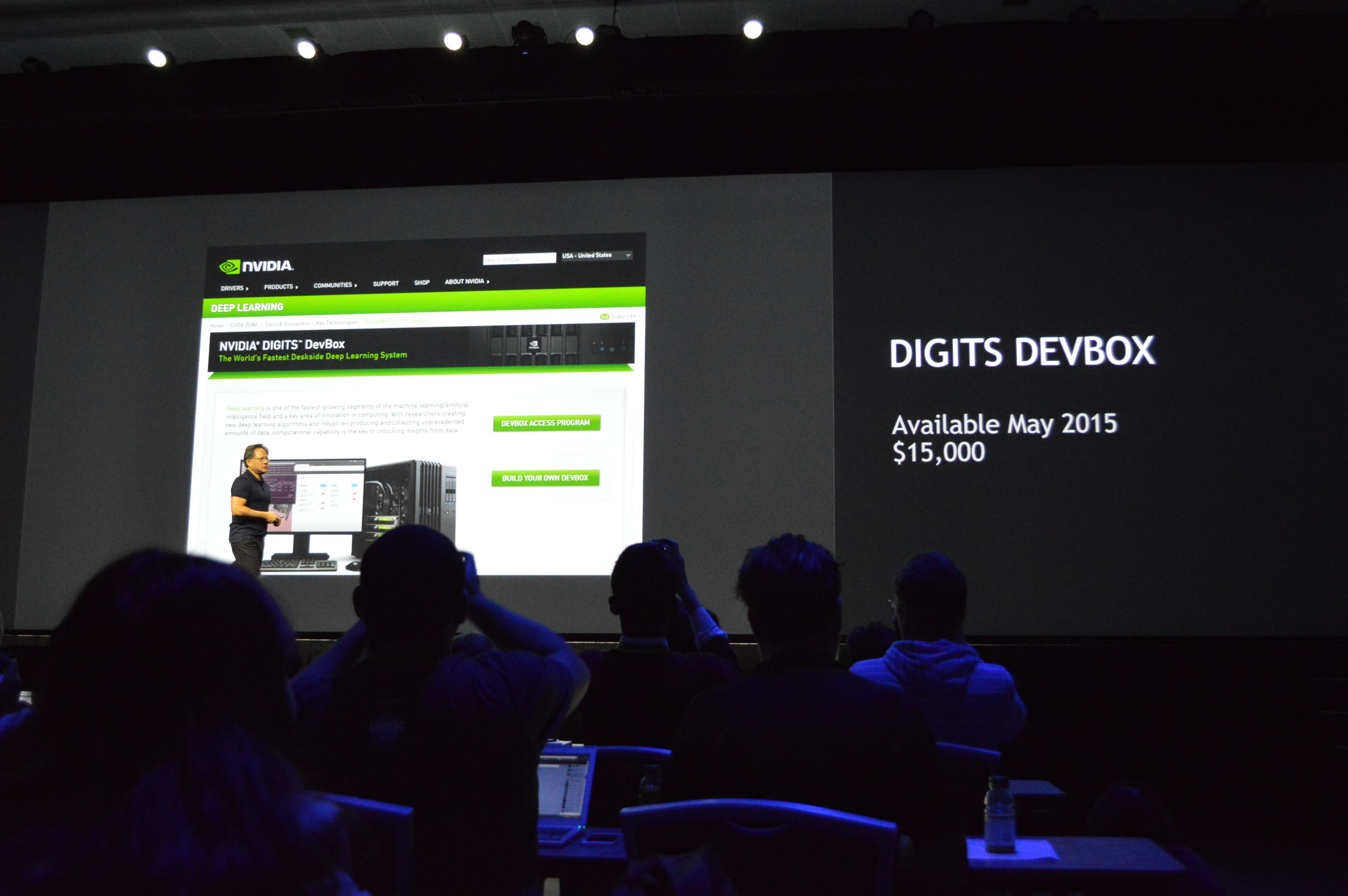
01:22PM EDT - They hope not to sell a whole lot of these, but rather to have these bootstrap further use of DIGITS
01:22PM EDT - Jen-Hsun is stressing that this is a box for developers, not for end-users
01:21PM EDT - Specialty box for running the DIGITS middleware
01:21PM EDT - 4 cards in a complete system. As much compute performance as you can get out of a single electrical outlet
01:20PM EDT - New product: the DIGITS DevBox

01:19PM EDT - Web-based UI

01:19PM EDT - DIGITS: A deep GPU training system for data scientists
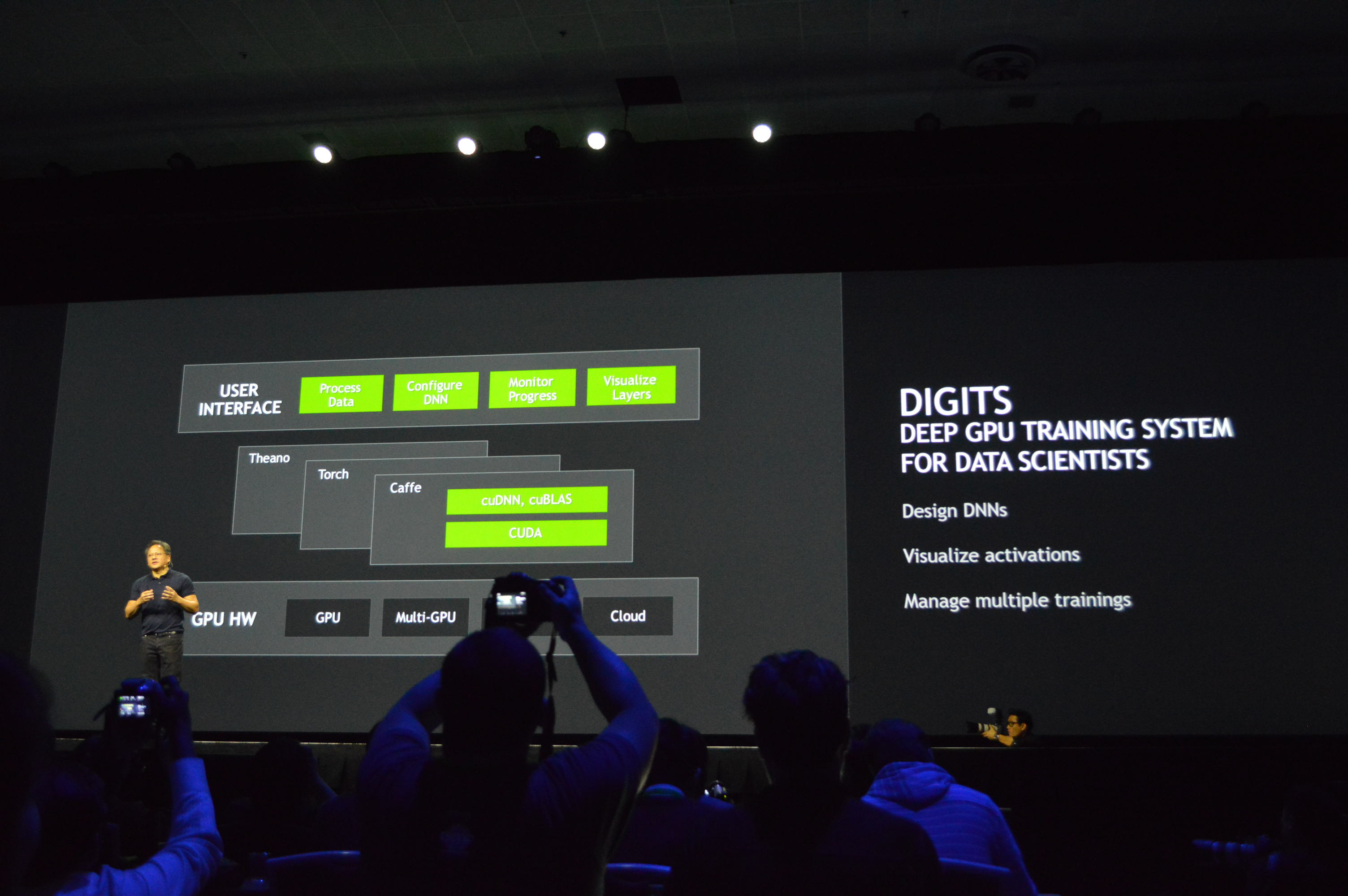
01:18PM EDT - NVIDIA now discussing ew frameworks for deep learning
01:16PM EDT - It's surprisingly accurate
01:16PM EDT - Demonstrating how he is able to use neural networks to train computers to describe scenes they're seeing

01:12PM EDT - "Automated image captioning with convnets and recurrent nets"
01:12PM EDT - Now on stage: Andrej Karpathy of Stanford

01:09PM EDT - Deep learning can also be applied to medical research. Using networks to identify patterns in drugs and biology

01:07PM EDT - Discussing how quickly companies have adopted deep learning, both major and start-ups

01:03PM EDT - Continuing to discuss the training process, and how networks get more accurate over time


12:59PM EDT - Now discussing AlexNet in depth


12:49PM EDT - The moral of the story: GPUs are a good match for image recognition via neural networks
12:48PM EDT - Now discussing AlexNet, a GPU powered neural network software package, one of the first and significantly better than its CPU counterparts
12:47PM EDT - Recounting a particular story about neural networks and handwriting recognition in 1999
12:44PM EDT - Discussing the history of neural networks for image recognition
12:42PM EDT - Now shifting gears from GTX Titan X to a deeper focus on deep learning

12:41PM EDT - While GTX Titan X lacks FP64 performance, NVIDIA still believes it will be very useful for compute users who need high FP32 performance such as neural networks and other examples of deep learning

12:40PM EDT - (The crowd takes a second to start applauding)
12:40PM EDT - GTX Titan X: $999
12:39PM EDT - Discussing how NVIDIA's cuDNN neural network middleware has allowed them to significantly increase neural network training times. Down to 3 days on GTX Titan X
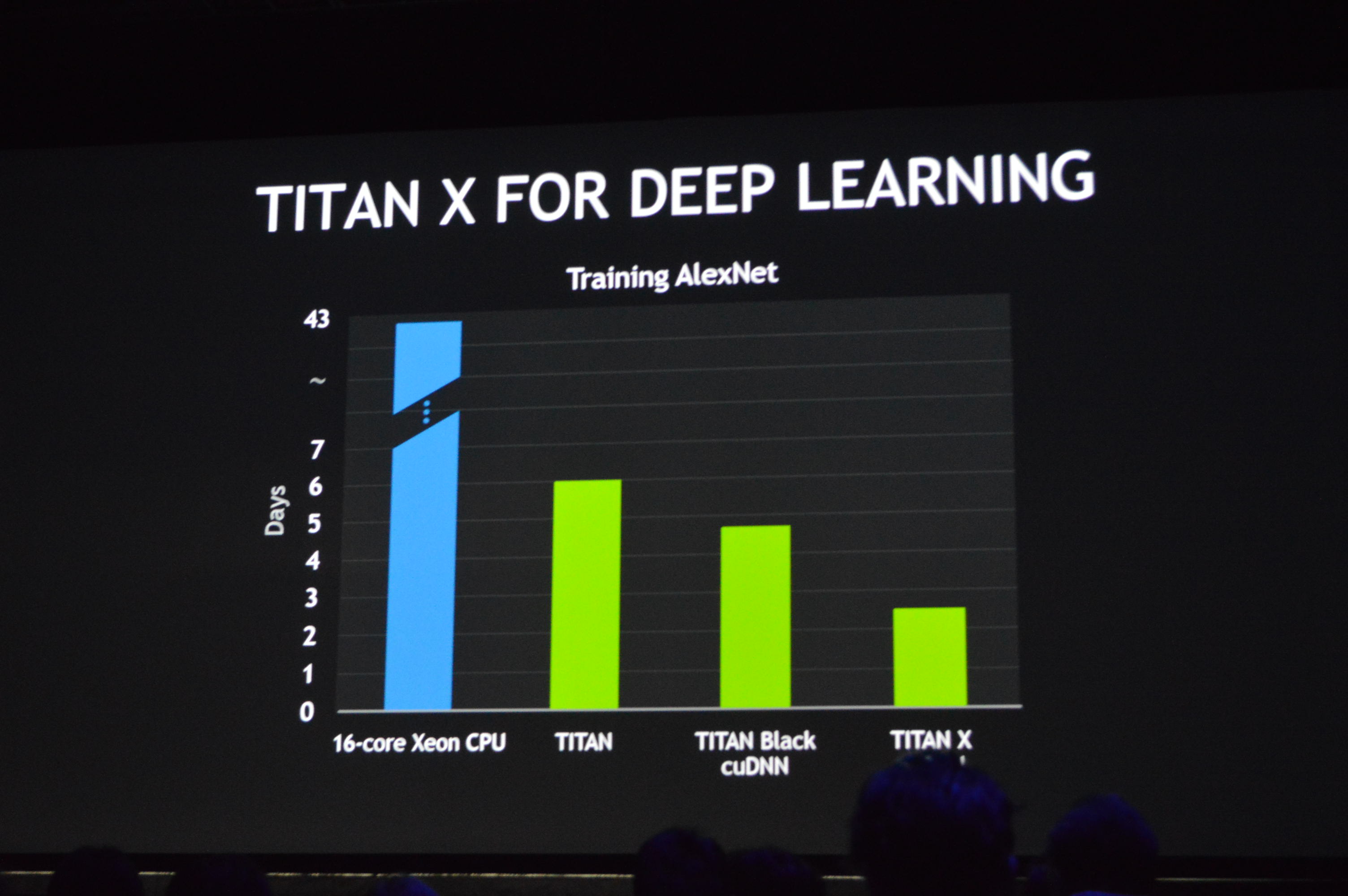
12:37PM EDT - Now how GTX Titan X ties into deep learning


12:32PM EDT - Now running Epic's kite demo in real time on GTX Titan X
12:31PM EDT - Big Maxwell does not have Big Kepler's FP64 performance. Titan X offers high FP32, but only minimal FP64
12:30PM EDT - Titan X: 8 billion transistors. Riva 128 was 4 million

12:30PM EDT - Now rolling a teaser video
12:29PM EDT - Previously teased at GDC 2015: http://www.anandtech.com/show/9049/nvidia-announces-geforce-gtx-titan-x
12:29PM EDT - New GPU: GTX Titan X
12:29PM EDT - Jen-Hsun is continuing to address the developers, talking about how NVIDIA has created a top-to-bottom GPU compute ecosystem
12:26PM EDT - (Not clear if that's cumulative, or in the last year)
12:26PM EDT - NVIDIA has sold over 450K Tesla GPUs at this point

12:25PM EDT - Now recapping the first year of GTC, and the first year of NVIDIA's Tesla initiative
12:23PM EDT - But NVIDIA couldn't do this without their audience, the developers

12:22PM EDT - Tesla continues to do well for the company, with NVIDIA racking up even more supercomputer wins. It has taken longer than NVIDIA originally projected, but it looks like Tesla is finally taking off
12:21PM EDT - Pro Visualization: Another good year, with GRID being a big driver
12:20PM EDT - Automotive revenue has doubled year-over-year
12:19PM EDT - Cars: a subject near and dear to Jen-Hsun's heart. Automotive has been a bright spot for NVIDIA's Tegra business
12:18PM EDT - Also recapping the SHIELD Console announcement from GDC 2015

12:17PM EDT - Year in review: GeForce
12:17PM EDT - Jen-Hsun thinks we'll be talking about deep learning fo te next decade, and thinks it will be very important to NVIDIA's future
12:16PM EDT - This continues NVIDIA's earlier advocacy of this field that was started with their CES 2015 Tegra X1 presentation
12:15PM EDT - Today's theme: deep learning

12:15PM EDT - 4 announcements: A new GPU, a very fast box, a roadmap reveal, and self-driving cars

12:14PM EDT - Jen-Hsun has taken the stage
12:14PM EDT - We're told to expect several surprises today. Meanwhile Tesla CEO Elon Musk is already confirmed to be one of today's guests, so that should be interesting
12:13PM EDT - Run time is expected to be 2 hours, with NVIDIA CEO Jen-Hsun Huang doing much of the talking
12:13PM EDT - We're her at the keynote presentation for NVIDIA's annaul conference, the GPU Technology Conference








47 Comments
View All Comments
nathanddrews - Tuesday, March 17, 2015 - link
It makes sense. If NVIDIA's CUDA customers are primarily universities, governments, and large corporations, then why bother making a "budget" DP card like the Titan X? They are clearly selling enough Tesla cards to make it worthwhile to strip down the Titan brand.I wonder how many - if any - CUDA programmers are using Swan or other conversion methods to OpenCL? Also, what sort of performance difference would there be between CUDA on Titan X and that converted code on 390X?
blanarahul - Tuesday, March 17, 2015 - link
"Of course, maybe part of the 'power optimizations' for Maxwell 2.0 involved removing all hardware level support for FP64"Then why keep support for that 0.2 GFLOPS of FP64 performance? Unless it's separate from the majority of SMMs that is.
JarredWalton - Tuesday, March 17, 2015 - link
You can always emulate FP64 with software, which is why it's 1/32 -- you basically use 32X as many FP32 instructions emulating FP64 compared to doing it natively. CPUs, GPUs, whatever -- they can all do FP64, but for some of them it's very slow.hammer256 - Tuesday, March 17, 2015 - link
Can you actually use FP32 instructions to emulate FP64 operations? I would imagine that to emulate FP64 operations you'll need to be using integer and logical ops. Anyone knows anything about this?But yeah, there goes that FP64 performance... that 28nm. 14/16nm FinFET can't come soon enough :(
JarredWalton - Tuesday, March 17, 2015 - link
You may be right -- it could be they're doing FP64 using lots of INT operations. It's been a while since I looked at doing any of this so I'm not up to speed.JarredWalton - Tuesday, March 17, 2015 - link
And now I've read the full review and understand that there is native FP64 hardware. I do wonder how hard it would be (performance wise) to emulate FP64 using other calculations, but most likely it would be even slower than the 1/32 ratio. Oops.[Goes and wipes egg off face...]
Ryan Smith - Tuesday, March 17, 2015 - link
GM200 has 1 FP64 ALU for every 32 FP32 ALUs. This is the case for all Maxwell GPUs.Kevin G - Tuesday, March 17, 2015 - link
I'm actually surprised that nVidia hasn't make more use of the GK210 chip. They quietly announced it late last year after the GTX 980. I took it as an indication it'd carry the double precision performance banner for months to come and with GM200's weak DP performance, my prediction came true.Now the second part of my prediction is that we'd see a Quadro (K6200?) based upon GK210. That hasn't panned out yet and the Quadro lineup may just go with the GM200 after all. Pictures of a Quadro M6000 have been floating around the past couple of days.
Ultimately the reason to remove much of the DP hardware from GM200 comes down to die size. It is already a huge chip and beefing up its DP throughput would balloon its size even more.
MrSpadge - Tuesday, March 17, 2015 - link
Quadro needs the FP32 and other Maxwell improvements more than FP64.testbug00 - Tuesday, March 17, 2015 - link
"compute optimized" means what exactly? The only thing Nvidia would need to do is to not disable the FP64 units. Given that they have any on the die.