The OCZ Vector 180 (240GB, 480GB & 960GB) SSD Review
by Kristian Vättö on March 24, 2015 2:00 PM EST- Posted in
- Storage
- SSDs
- OCZ
- Barefoot 3
- Vector 180
Random Read Performance
One of the major changes in our 2015 test suite is the synthetic Iometer tests we run. In the past we used to test just one or two queue depths, but real world workloads always contain a mix of different queue depths as shown by our Storage Bench traces. To get the full scope in performance, I'm now testing various queue depths starting from one and going all the way to up to 32. I'm not testing every single queue depth, but merely how the throughput scales with the queue depth. I'm using exponential scaling, meaning that the tested queue depths increase in powers of two (i.e. 1, 2, 4, 8...).
Read tests are conducted on a full drive because that is the only way to ensure that the results are valid (testing with an empty drive can substantially inflate the results and in reality the data you are reading is always valid rather than full of zeros). Each queue depth is tested for three minutes and there is no idle time between the tests.
I'm also reporting two metrics now. For the bar graph, I've taken the average of QD1, QD2 and QD4 data rates, which are the most relevant queue depths for client workloads. This allows for easy and quick comparison between drives. In addition to the bar graph, I'm including a line graph, which shows the performance scaling across all queue depths. To keep the line graphs readable, each drive has its own graph, which can be selected from the drop-down menu.
I'm also plotting power for SATA drives and will be doing the same for PCIe drives as soon as I have the system set up properly. Our datalogging multimeter logs power consumption every second, so I report the average for every queue depth to see how the power scales with the queue depth and performance.
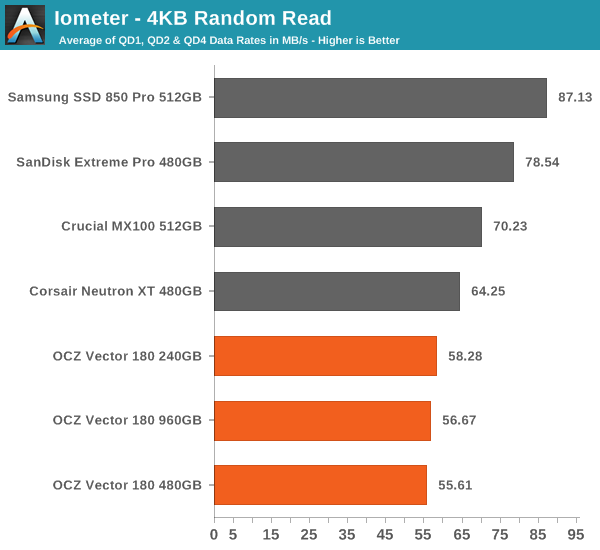
Random read performance at small queue depths has never been an area where the Vector 180 has excelled in. Given that these are one of the most common IOs, it's an area where I would like to see improvement on OCZ's behalf.
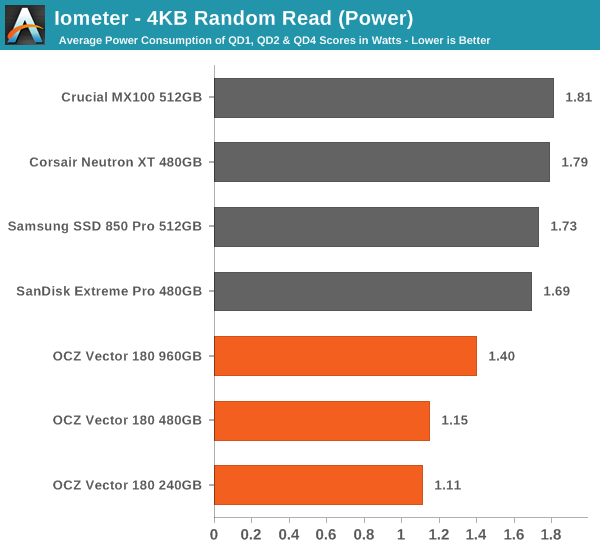
Power consumption, on the other hand, is excellent, which is partially explained by the lower performance.
 |
|||||||||
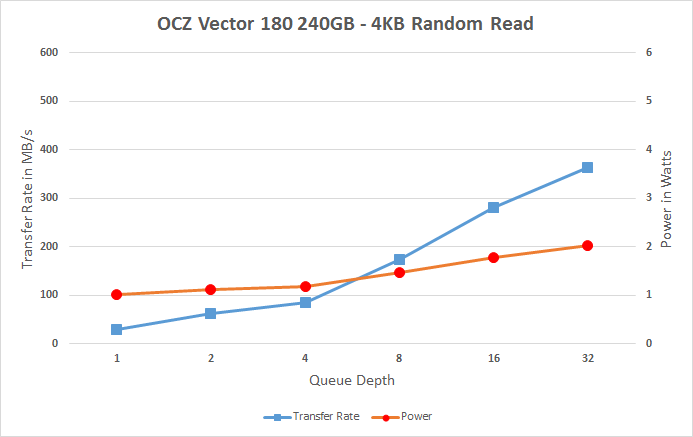
Having a closer look at the performance data across all queue depths reveals the reason for Vector 180's poor random read performance. For some reason, the performance only starts to scale properly after queue depth of 4, but even then the scaling isn't as aggressive as on some other drives.
Random Write Performance
Write performance is tested in the same way as read performance, except that the drive is in a secure erased state and the LBA span is limited to 16GB. We already test performance consistency separately, so a secure erased drive and limited LBA span ensures that the results here represent peak performance rather than sustained performance.
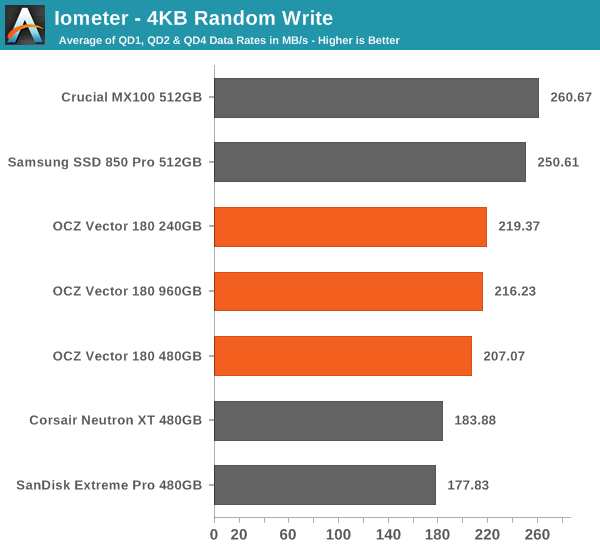
In random write performance the Vector 180 does considerably better, although it's still not the fastest drive around.
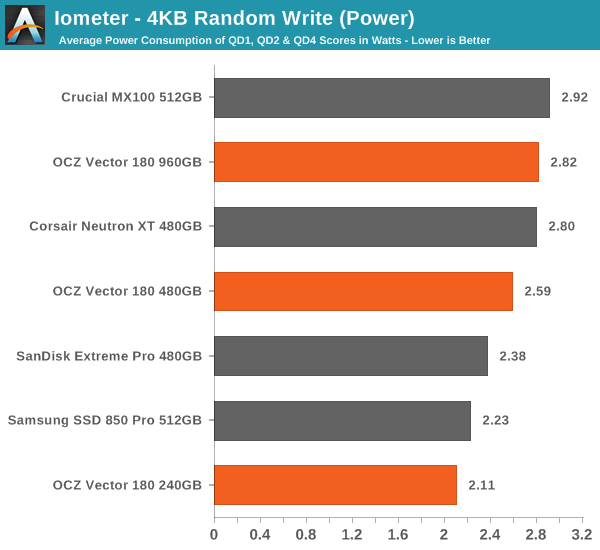
Even though the random write performance doesn't scale at all with capacity, the power consumption does. Still, the Vector 180 is quite power efficient compared to other drives.
 |
|||||||||
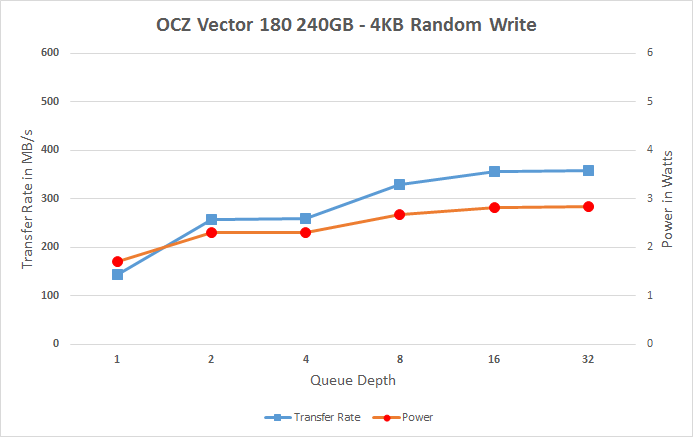
The Vector 180 scales smoothly across all queue depths, but it could scale a bit more aggressively because especially the QD4 score is a bit low. On a positive side, the Vector 180 does very well at QD1, though.








89 Comments
View All Comments
nils_ - Wednesday, March 25, 2015 - link
It's an interesting concept (especially when the Datacenter uses a DC Distribution instead of AC), but I don't know if I would be comfortable with batteries in everything. A capacitor holds less of a charge but doesn't deteriorate over time and the only component that really needs to stay on is the drive (or RAID controller if you're into that).nils_ - Wednesday, March 25, 2015 - link
"I don't think it has been significant enough to warrant physical power loss protection for all client SSDs."If a drive reports a flush as complete, the operating system must be confident that the data is already written to the underlying device. Any drive that doesn't deliver this is quite simply defective by design. Back in the day this was already a problem with some IDE and SATA drives, they reported a write operation as complete once the data hit the drive cache. Just because something is rated as consumer grade does not mean that they should ship defective devices.
Even worse is that instead of losing the last few writes you'll potentially lose all the data stored on the drive.
If I don't care whether the data makes it to the drive I can solve that in software.
shodanshok - Wednesday, March 25, 2015 - link
If a drive receive an ATA FLUSH command, it _will_ write to stable storage (HDD platters or NAND chips) before returning. For unimportant writes (the ones not marked with FUA or encapsulated into an ATA FLUSH) the drive is allowed to store data into cache and return _before_ the data hit the actual permanent storage.SSDs adds another problem: by the very nature of MCL and TLC cells, data at rest (already comitted to stable storage) are at danger by the partial page write effect. So, PMF+ and Crucial's consumer drive Power Loss Protection are _required_ for reliable use of the drive. Drives that don't use at least partial power loss protection should use a write-through (read-only cache) approach at least for the NAND mapping table or very frequent flushes of the mapping table (eg: Sandisk)
mapesdhs - Wednesday, March 25, 2015 - link
How do the 850 EVO & Pro deal with this scenario atm?
Ian.
Oxford Guy - Wednesday, March 25, 2015 - link
"That said, while drive bricking due to mapping table corruption has always been a concern, I don't think it has been significant enough to warrant physical power loss protection for all client SSDs."I see you never owned 240 GB Vertex 2 drives with 25nm NAND.
prasun - Wednesday, March 25, 2015 - link
"PFM+ will protect data that has already been written to the NAND"They should be able to do this by scanning NAND. The capacitor probably makes life easier, but with better firmware design this should not be necessary.
With the capacitor, the steady state performance should be consistent, as they won't need to flush mapping table to NAND regularly.
Since this is also not the case, this points to bad firmware design
marraco - Wednesday, March 25, 2015 - link
I have a bricked Vertex 2 resting a meter away. It was so expensive that I cannot resign to trow it at the waste.I will never buy another OCZ product, ever.
OCZ refused to release the software needed to unbrick it. Is just a software problem. OCZ got my money, but refuses to make it work.
Do NOT EVER buy anything from OCZ.
ocztosh - Wednesday, March 25, 2015 - link
Hello Marraco, thank you for your feedback and sorry to hear that you had an issue with the Vertex 2. That particular drive was Sandforce based and there was no software to unbrick it unfortunately, nor did the previous organization have the source code for firmware. This was actually one of the reasons that drove the company to push to develop in-house controllers and firmware, so we could control these elements which ultimately impacts product design and support.Please do contact our support team and reference this thread. Even though this is a legacy product we would be more than happy to help and provide support. Thank you again for your comments and we look forward to supporting you.
mapesdhs - Wednesday, March 25, 2015 - link
Indeed, the Vertex4 and Vector series are massively more reliable, but the OCZ hatersignore them entirely, focusing on the old Vertex2 series, etc. OCZ could have handled
some of the support issues back then better, but the later products were more reliable
anyway so it was much less of an issue. With the newer warranty structure, Toshiba
ownership & NAND, etc., it's a very different company.
Irony is, I have over two dozen Vertex2E units and they're all working fine (most are
120s, with a sprinkling of 60s and 240s). One of them is an early 3.5" V2E 120GB,
used in an SGI Fuel for several years, never a problem (recently replaced with a
2.5" V2E 240GB).
Btw ocztosh, I've been talking to some OCZ people recently about why certain models
force a 3gbit SAS controller to negotiate only a 1.5gbit link when connected to a SATA3
SSD. This occurs with the Vertex3/4, Vector, etc., whereas connecting the SATA2 V2E
correctly results in a 3Gbit link. Note I've observed similar behaviour with other brands,
ditto other SATA2 SSDs (eg. SF-based Corsair F60, 3Gbit link selected ok). The OCZ
people I talked to said there's nothing they can do to fix whatever the issue might be,
but what I'm interested in is why it happens; if I can find that out then maybe I can
figure a workaround. I'm using LSI 1030-based PCIe cards, eg. SAS3442, SAS3800,
SAS3041, etc. I'd welcome your thoughts on the issue. Would be nice to get a Vertex4
running with a 3Gbit link in a Fuel, Tezro or Origin/Onyx.
Note I've been using the Vertex4 as a replacement for ancient 1GB SCSI disks in
Stoll/SIRIX systems used by textile manufacturers, works rather well. Despite the
low bandwidth limit of FastSCSI2 (10MB/sec), it still cut the time for a full backup
from 30 mins to just 6 mins (tens of thousands of small pattern files). Alas, with
the Vertex4 no longer available, I switched to the Crucial M550 (since it does have
proper PLP). I'd been hoping to use the V180 instead, but its lack of full PLP is an issue.
Ian.
alacard - Wednesday, March 25, 2015 - link
In my view the performance consistency basically blows the lid off of OCZ and the reliability of their Barefoot controller. Despite reporting from most outlets, for years now drives based off of this technology have suffered massive failure rates due to sudden power loss. Here we have definitive evidence of those flaws and the lengths OCZ is going to in order to work around them (note, i didn't say 'fix' them).The fact that they were willing to go to the extra cost of adding the power loss module in addition to crippling the sustained performance of their flagship drive in order to flush the cache out of DRAM speaks VOLUMES about how bad their reliability was before. You don't go to such extreme - potentially kiss of death measures - without a good boot up your ass pushing you headlong toward them. In this case said boot was constructed purely out of OCZ's fear that releasing yet ANOTHER poorly constructed drive would finally put their reputation out of it's misery for good and kill any chance a future sales.
OCZ has cornered themselves in a no win scenario:
1) They don't bother making the drive reliable and in doing so save the cost of the power loss module and keep the sustained speed of the Vector 180 high. The drive reviews well with no craters in performance and the few customers OCZ has left buy another doomed Barefoot SSD that's practically guaranteed to brick on them within a few months. As a result they loose those customers for good along with their company.
or
2) The go to the cost of adding the power loss module and cripple the drives performance to ensure that the drive is reliable. The drive reviews horribly and no one buys it.
This is their position. Kiss of death indeed.
Ultimately, i think it speaks to how complicated controller development is and that if you don't have a huge company with millions of R&D funds at your disposal it's probably best if you don't throw your hat into that ring. It's a shame but it seems to be the way high tech works. (Global oligopoly, here we come.)
All things considered, it's nice that this is finally all out in the open.