DDR4 Haswell-E Scaling Review: 2133 to 3200 with G.Skill, Corsair, ADATA and Crucial
by Ian Cutress on February 5, 2015 10:10 AM ESTProfessional Performance: Windows
Agisoft Photoscan – 2D to 3D Image Manipulation: link
Agisoft Photoscan creates 3D models from 2D images, a process which is very computationally expensive. The algorithm is split into four distinct phases, and different phases of the model reconstruction require either fast memory, fast IPC, more cores, or even OpenCL compute devices to hand. Agisoft supplied us with a special version of the software to script the process, where we take 50 images of a stately home and convert it into a medium quality model. This benchmark typically takes around 15-20 minutes on a high end PC on the CPU alone, with GPUs reducing the time.
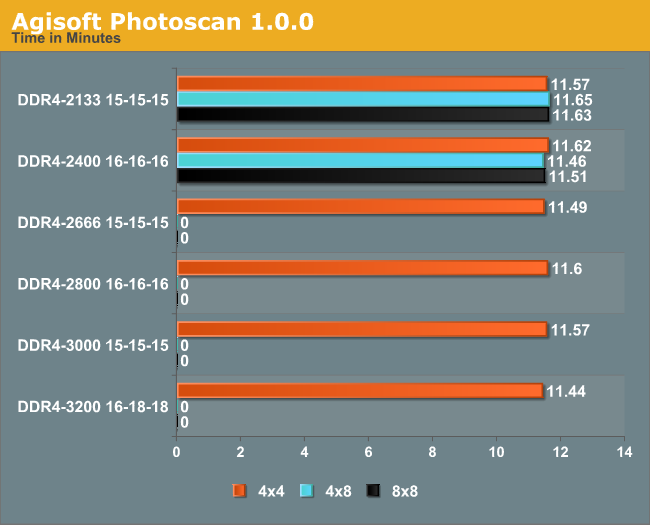
Photoscan, on paper, would offer more possibilities for faster memory to make a difference. However it would seem that the most memory dependent stage (stage 3) is actually a small part of the overall calculation and was absorbed by the natural variation in the larger stages, giving at most a 1.1% difference between times.
Cinebench R15
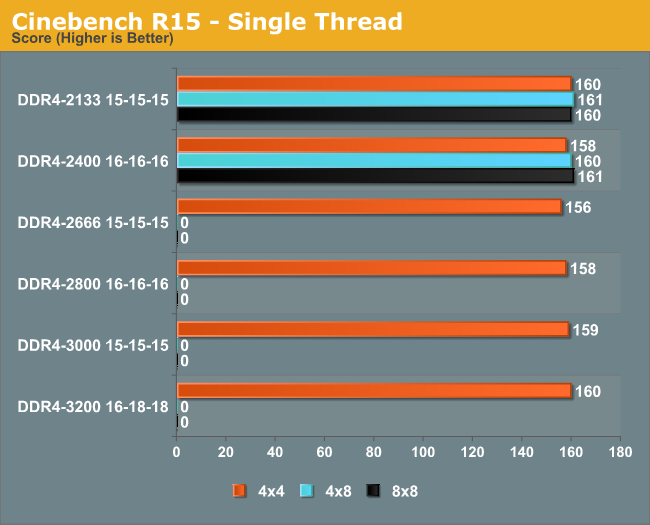
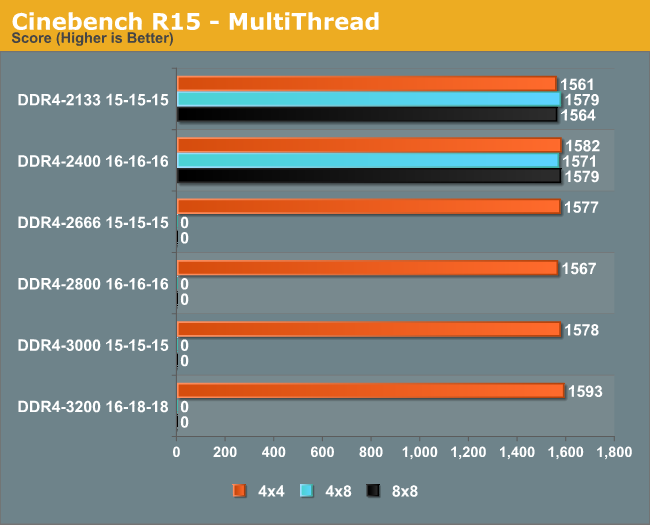
Cinebench is historically CPU dependent, giving a 2% difference from JEDEC to peak results.
3D Particle Movement
3DPM is a self-penned benchmark, taking basic 3D movement algorithms used in Brownian Motion simulations and testing them for speed. High floating point performance, MHz and IPC wins in the single thread version, whereas the multithread version has to handle the threads and loves more cores.
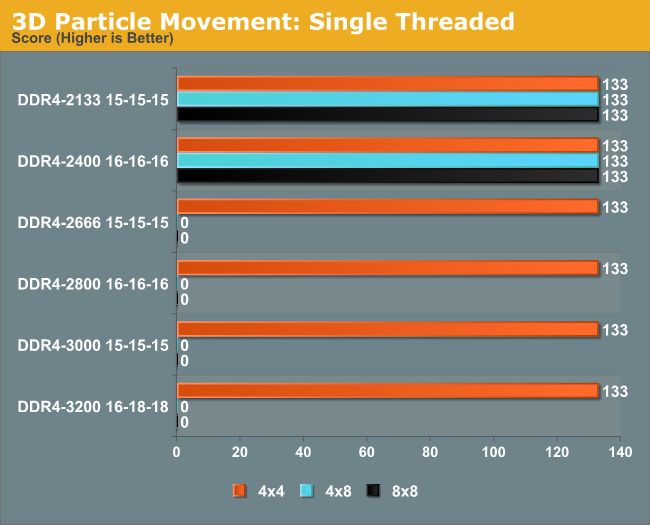

3DPM is also relatively memory agnostic for DDR4 on Haswell-E, showing that DDR4-2133 is good enough.
Professional Performance: Linux
Built around several freely available benchmarks for Linux, Linux-Bench is a project spearheaded by Patrick at ServeTheHome to streamline about a dozen of these tests in a single neat package run via a set of three commands using an Ubuntu 14.04 LiveCD. These tests include fluid dynamics used by NASA, ray-tracing, molecular modeling, and a scalable data structure server for web deployments. We run Linux-Bench and have chosen to report a select few of the tests that rely on CPU and DRAM speed.
C-Ray: link
C-Ray is a simple ray-tracing program that focuses almost exclusively on processor performance rather than DRAM access. The test in Linux-Bench renders a heavy complex scene offering a large scalable scenario.
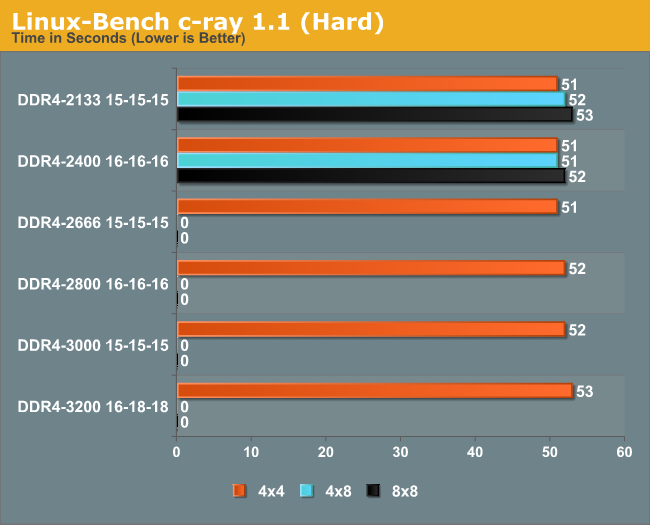
Natural variation gives a 4% difference, although the faster and more dense memory gave slower times.
NAMD, Scalable Molecular Dynamics: link
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois at Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization up to and beyond 200,000 cores. The reference paper detailing NAMD has over 4000 citations, and our testing runs a small simulation where the calculation steps per unit time is the output vector.
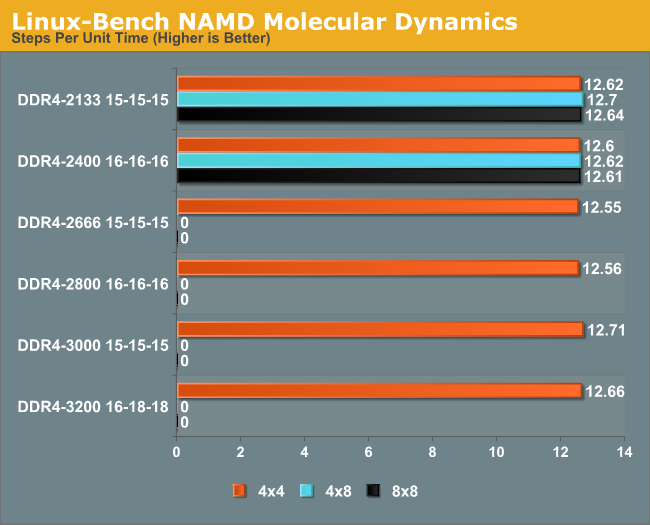
NAMD showed little difference between our memory kits, peaking at 0.7% above JEDEC.
NPB, Fluid Dynamics: link
Aside from LINPACK, there are many other ways to benchmark supercomputers in terms of how effective they are for various types of mathematical processes. The NAS Parallel Benchmarks (NPB) are a set of small programs originally designed for NASA to test their supercomputers in terms of fluid dynamics simulations, useful for airflow reactions and design.
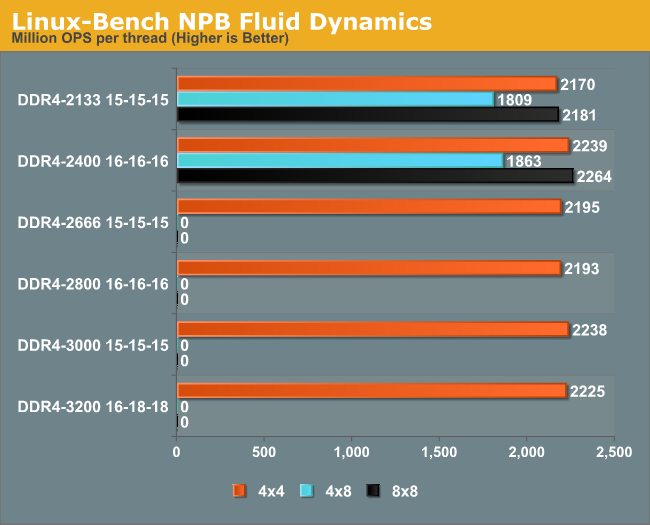
Despite the 4x8 GB results going south of the border, the faster memory does give a slight difference in NPB, peaking at 4.3% increased performance for the 3000+ memory kits.
Redis: link
Many of the online applications rely on key-value caches and data structure servers to operate. Redis is an open-source, scalable web technology with a b developer base, but also relies heavily on memory bandwidth as well as CPU performance.
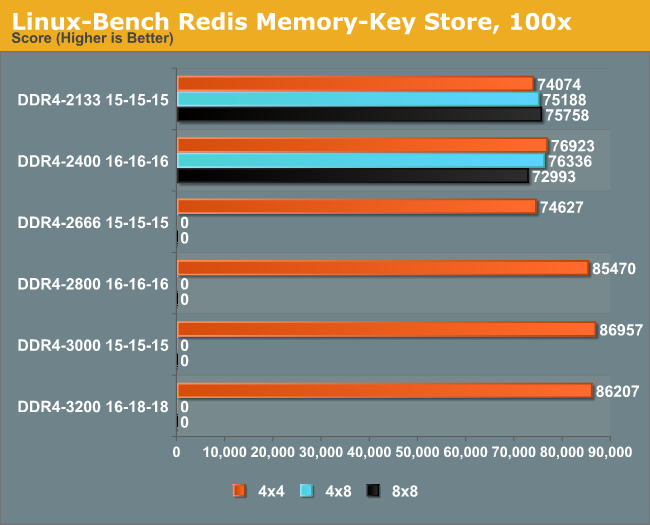
When tackling a high number of users, Redis performs up to 17% better using 2800+ memory, indicating our best benchmark result.








120 Comments
View All Comments
jabber - Friday, February 6, 2015 - link
Well I've added into my T5400 workstation USB3.0, eSATA, 7870 GPU, SSHD and SSD. I haven't added SATA III as its way too costly for a decent card, plus even though I can only push 260MBps from a SSD, with 0.1ms access times I really can't notice in real world. The main chunk of the machine only cost around £200 to put together.Striker579 - Friday, February 6, 2015 - link
omg those retro color mb's....good timesWardrop - Saturday, February 7, 2015 - link
Wow, how did you accidentally insert your motherboard model in the middle of the word "provide"? Quite an impressive typo, lolmsroadkill612 - Saturday, September 2, 2017 - link
To be the devils advocate, many say there are few downside for most using 8 lane gpu vs 16 lanes for gpu.if nvme an ssd means reducing to 8 lanes for gpu to free some lanes, I would be tempted.
FlushedBubblyJock - Sunday, February 15, 2015 - link
Core 2 is getting weak - right click and open ttask manager then see how often your quad is maxxed at 100% useage (you can minimize and check the green rectangle by the clock for percent used).That's how to check it - if it's hammered it's time to sell it and move up. You might be quite surprised what a large jump it is to Sandy Bridge.
blanarahul - Thursday, February 5, 2015 - link
TOTALLY OFF TOPIC but this is how Samsung's current SSD lineup should be:850: 120 GB, 250 GB TLC with TurboWrite
850 Pro: 128 GB, 256 GB MLC
850 EVO: 500/512 GB, 1000/1024 GB TLC w/o TurboWrite
Because:
a) 500 GB and 1000 GB 850 EVOs don't get any speed benefit from TurboWrite.
b) 512/1024 GB PRO has only 10 MB/s sequential read, 2K IOPS and 12/24 GB capacity advantage over 500/1000 GB EVO. Sequential write speed, advertised endurance, random write speed, features etc. are identical between them.
c) Remove TurboWrite from 850 EVO and you get a capacity boost because you are no longer running TLC NAND in SLC mode.
Cygni - Thursday, February 5, 2015 - link
Considering what little performance impact these memory standards have had lately, DDR2 is essentially just as useful and relevant as the latest stuff... with the added of advantage of the fact that you already own it.FlushedBubblyJock - Sunday, February 15, 2015 - link
If you screw around long enough on core 2 boards with slight and various cpu OC's with differing FSB's and result memory divisors and timings with mechanical drives present, you can sometimes produce and enormous performance increase and reduce boot times massively - the key seems to have been a differing sound in the speedy access of the mechanical hard drive - though it offten coincided with memory access time but not always.I assumed and still do assume it is an anomaly in the exchanges on the various buses where cpu, ram, harddrive, and the north and south bridges timings just happen to all jibe together - so no subsystem is delayed waiting for some other overlap to "re-access".
I've had it happen dozens of times on many differing systems but never could figure out any formula and it was always just luck goofing with cpu and memory speed in the bios.
I'm not certain if it works with ssd's on core 2's (socket 775 let's say) - though I assume it very well could but the hard drive access sound would no longer be a clue.
retrospooty - Thursday, February 5, 2015 - link
I love reviews like this... I will link it and keep it for every time some newb doof insists that high bandwidth RAM is important. We saw almost no improvement going from DDR400 cas2 to DDR3-1600 CAS10 now the same to DDR4 3000+ CAS freegin 80 LOLmenting - Thursday, February 5, 2015 - link
depends on usage. for applications that require high total bandwidth, new generations of memory will be better, but for applications that require short latency, there won't be much improvement due to physical restraints of light speed