DDR4 Haswell-E Scaling Review: 2133 to 3200 with G.Skill, Corsair, ADATA and Crucial
by Ian Cutress on February 5, 2015 10:10 AM ESTCPU Real World Performance
A small note on real world testing against synthetic testing – due to the way that DRAM affects a system, there can be a large disconnect between what we can observe in synthetic tests against real world testing. Synthetic tests are designed to exploit various feature XYZ, usually in an unrealistic scenario, such as pure memory read speeds or bandwidth numbers. While these are good for exploring the peak potential of a system, they often to not translate as well as CPU speed does if we invoke some common prosumer real world task. So while spending 10x on memory might show a large improvement in peak bandwidth numbers, users will have to weigh up the real world benefits in order to find the day-to-day difference when going for expensive hardware. Typically a limiting factor might be something else in the system, such as the size of a cache, so with all the will in the world a faster read speed won’t make much difference. As a result, we tend to stick to real world tests for almost all of our testing (with a couple of minor suggestions). Our benchmarks are either derived from areas such as transcoding a film or come from a regular software format such as molecular dynamics running a consistent scene.
Handbrake v0.9.9
For HandBrake, we take two videos (a 2h20 640x266 DVD rip and a 10min double UHD 3840x4320 animation short) and convert them to x264 format in an MP4 container. Results are given in terms of the frames per second processed, and HandBrake uses as many threads as possible.
The low quality conversion is more reliant on CPU cycles available, while the high resolution conversion seems to have a very slight ~3% benefit moving up to DDR4-3000 memory.
WinRAR 5.01
Our WinRAR test from 2013 is updated to the latest version of WinRAR at the start of 2014. We compress a set of 2867 files across 320 folders totaling 1.52 GB in size – 95% of these files are small typical website files, and the rest (90% of the size) are small 30 second 720p videos.
The biggest difference showed a 5% gain over DDR4-2133 C15, although this seemed at random.
FastStone Image Viewer 4.9
FastStone Image Viewer is a free piece of software I have been using for quite a few years now. It allows quick viewing of flat images, as well as resizing, changing color depth, adding simple text or simple filters. It also has a bulk image conversion tool, which we use here. The software currently operates only in single-thread mode, which should change in later versions of the software. For this test, we convert a series of 170 files, of various resolutions, dimensions and types (of a total size of 163MB), all to the .gif format of 640x480 dimensions. Results shown are in seconds, lower is better.

No difference between the memory speeds in FastStone.
x264 HD 3.0 Benchmark
The x264 HD Benchmark uses a common HD encoding tool to process an HD MPEG2 source at 1280x720 at 3963 Kbps. This test represents a standardized result which can be compared across other reviews, and is dependent on both CPU power and memory speed. The benchmark performs a 2-pass encode, and the results shown are the average frame rate of each pass performed four times. Higher is better this time around.
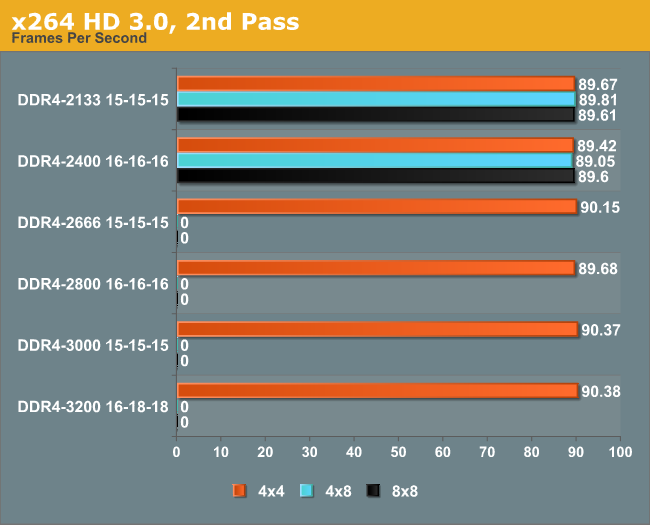
The faster memory showed a 2.5% gain on the first pass, but less than a 1% gain in the second pass.
7-Zip 9.2
As an open source compression tool, 7-Zip is a popular tool for making sets of files easier to handle and transfer. The software offers up its own benchmark, to which we report the result.
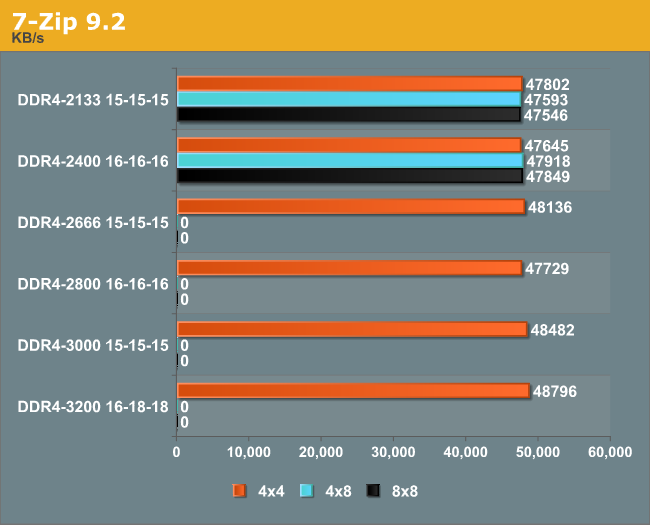
At most a 2% gain was shown by 3000+ memory.
Mozilla Kraken 1.1
One of the more popular web benchmarks that stresses various codes, we run this benchmark in Chrome 35.
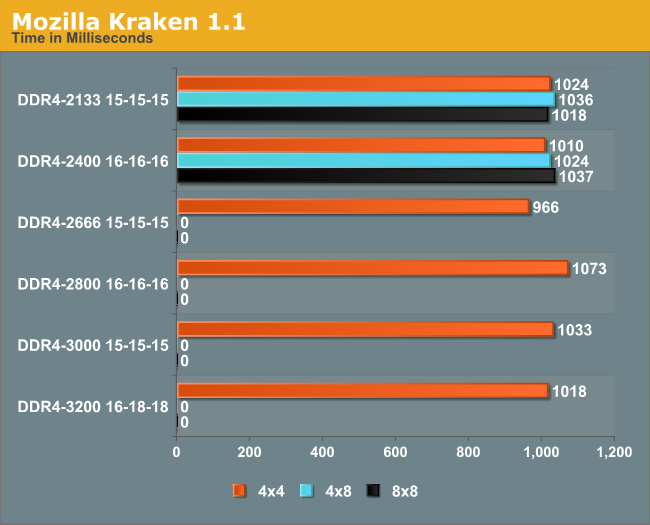
Kraken seemed to prefer the fast 1.2V memory, giving a 4.8% gain at DDR4-2800 C16, although this did not translate into the faster memory.
WebXPRT
A more in-depth web test featuring stock price rendering, image manipulation and face recognition algorithms, also run in Chrome 35.
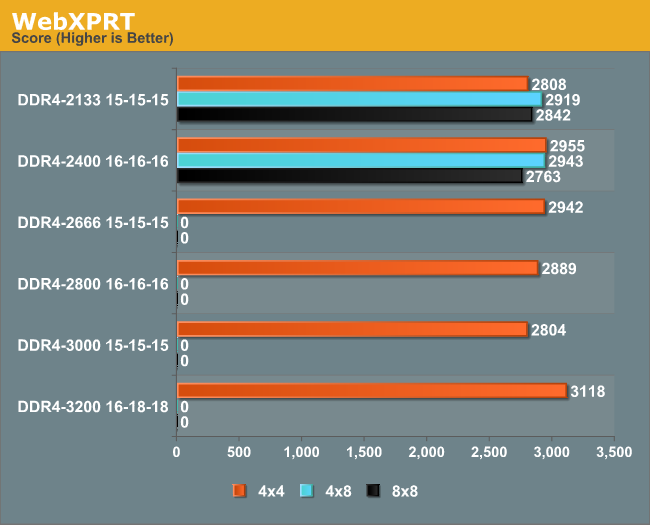
The DDR4-3200 gave an 11% gain over the base JEDEC memory, although this seemed to be more of a step than a slow rise.








120 Comments
View All Comments
jabber - Friday, February 6, 2015 - link
Well I've added into my T5400 workstation USB3.0, eSATA, 7870 GPU, SSHD and SSD. I haven't added SATA III as its way too costly for a decent card, plus even though I can only push 260MBps from a SSD, with 0.1ms access times I really can't notice in real world. The main chunk of the machine only cost around £200 to put together.Striker579 - Friday, February 6, 2015 - link
omg those retro color mb's....good timesWardrop - Saturday, February 7, 2015 - link
Wow, how did you accidentally insert your motherboard model in the middle of the word "provide"? Quite an impressive typo, lolmsroadkill612 - Saturday, September 2, 2017 - link
To be the devils advocate, many say there are few downside for most using 8 lane gpu vs 16 lanes for gpu.if nvme an ssd means reducing to 8 lanes for gpu to free some lanes, I would be tempted.
FlushedBubblyJock - Sunday, February 15, 2015 - link
Core 2 is getting weak - right click and open ttask manager then see how often your quad is maxxed at 100% useage (you can minimize and check the green rectangle by the clock for percent used).That's how to check it - if it's hammered it's time to sell it and move up. You might be quite surprised what a large jump it is to Sandy Bridge.
blanarahul - Thursday, February 5, 2015 - link
TOTALLY OFF TOPIC but this is how Samsung's current SSD lineup should be:850: 120 GB, 250 GB TLC with TurboWrite
850 Pro: 128 GB, 256 GB MLC
850 EVO: 500/512 GB, 1000/1024 GB TLC w/o TurboWrite
Because:
a) 500 GB and 1000 GB 850 EVOs don't get any speed benefit from TurboWrite.
b) 512/1024 GB PRO has only 10 MB/s sequential read, 2K IOPS and 12/24 GB capacity advantage over 500/1000 GB EVO. Sequential write speed, advertised endurance, random write speed, features etc. are identical between them.
c) Remove TurboWrite from 850 EVO and you get a capacity boost because you are no longer running TLC NAND in SLC mode.
Cygni - Thursday, February 5, 2015 - link
Considering what little performance impact these memory standards have had lately, DDR2 is essentially just as useful and relevant as the latest stuff... with the added of advantage of the fact that you already own it.FlushedBubblyJock - Sunday, February 15, 2015 - link
If you screw around long enough on core 2 boards with slight and various cpu OC's with differing FSB's and result memory divisors and timings with mechanical drives present, you can sometimes produce and enormous performance increase and reduce boot times massively - the key seems to have been a differing sound in the speedy access of the mechanical hard drive - though it offten coincided with memory access time but not always.I assumed and still do assume it is an anomaly in the exchanges on the various buses where cpu, ram, harddrive, and the north and south bridges timings just happen to all jibe together - so no subsystem is delayed waiting for some other overlap to "re-access".
I've had it happen dozens of times on many differing systems but never could figure out any formula and it was always just luck goofing with cpu and memory speed in the bios.
I'm not certain if it works with ssd's on core 2's (socket 775 let's say) - though I assume it very well could but the hard drive access sound would no longer be a clue.
retrospooty - Thursday, February 5, 2015 - link
I love reviews like this... I will link it and keep it for every time some newb doof insists that high bandwidth RAM is important. We saw almost no improvement going from DDR400 cas2 to DDR3-1600 CAS10 now the same to DDR4 3000+ CAS freegin 80 LOLmenting - Thursday, February 5, 2015 - link
depends on usage. for applications that require high total bandwidth, new generations of memory will be better, but for applications that require short latency, there won't be much improvement due to physical restraints of light speed