Intel Releases Broadwell-U: New SKUs, up to 48 EUs and Iris 6100
by Ian Cutress on January 5, 2015 10:00 AM ESTBroadwell GPU Improvements
The new integrated graphics for Broadwell from Intel in the form of HD 5500, HD 6000 and Iris 6100 open up some very important functionality. DirectX 11.2, OpenGL 4.3 and OpenCL 2.0 are big scoring points, especially OpenCL 2.0 when it comes to graphics compute. This includes features such as shared memory coherency between CPU and GPU to allow transfer of pointer-rich memory structures and ultimately the beginnings of heterogeneous CPU + GPU compute.

‘DirectX 12 Ready’ is somewhat of an interesting case, and it depends on Microsoft’s final specifications. At this point in time Intel state that they conform to as much of DirectX 12 feature set that they can get their hands on with their relationship with Microsoft, and barring any major addition or change, should be compatible. UHD-4K is also now supported through the HDMI 1.4b interface, albeit limited to 24 Hz.
Support for HEVC is also present in terms of a combined (hybrid) hardware and software solution, just as it was on Core-M. Intel stated that as parts of the H.264 algorithm are near if not identical to those of the H.265, with a small tweak to the hardware it can be used for both. This is still not an all-encompassing hardware acceleration, but it does aim at some parts of the codec. I would speculate that if a full section of the silicon could be made for complete hardware acceleration, it might eat into certain power budgets.
GPU Slices
Although mentioned in our Broadwell architecture overview, for Broadwell-U we should cover the basics of the GPU layout. Below is an image of a HD 6000 implementation featuring two slices of 24 EUs each, with each slice having three sub-slices of 8 EUs. Each EU can handle 7 threads at once when in a 128xSIMD8 32-bit configuration. When in the right data structure, this offers a good amount of power, especially to coalesced 16-bit computation.
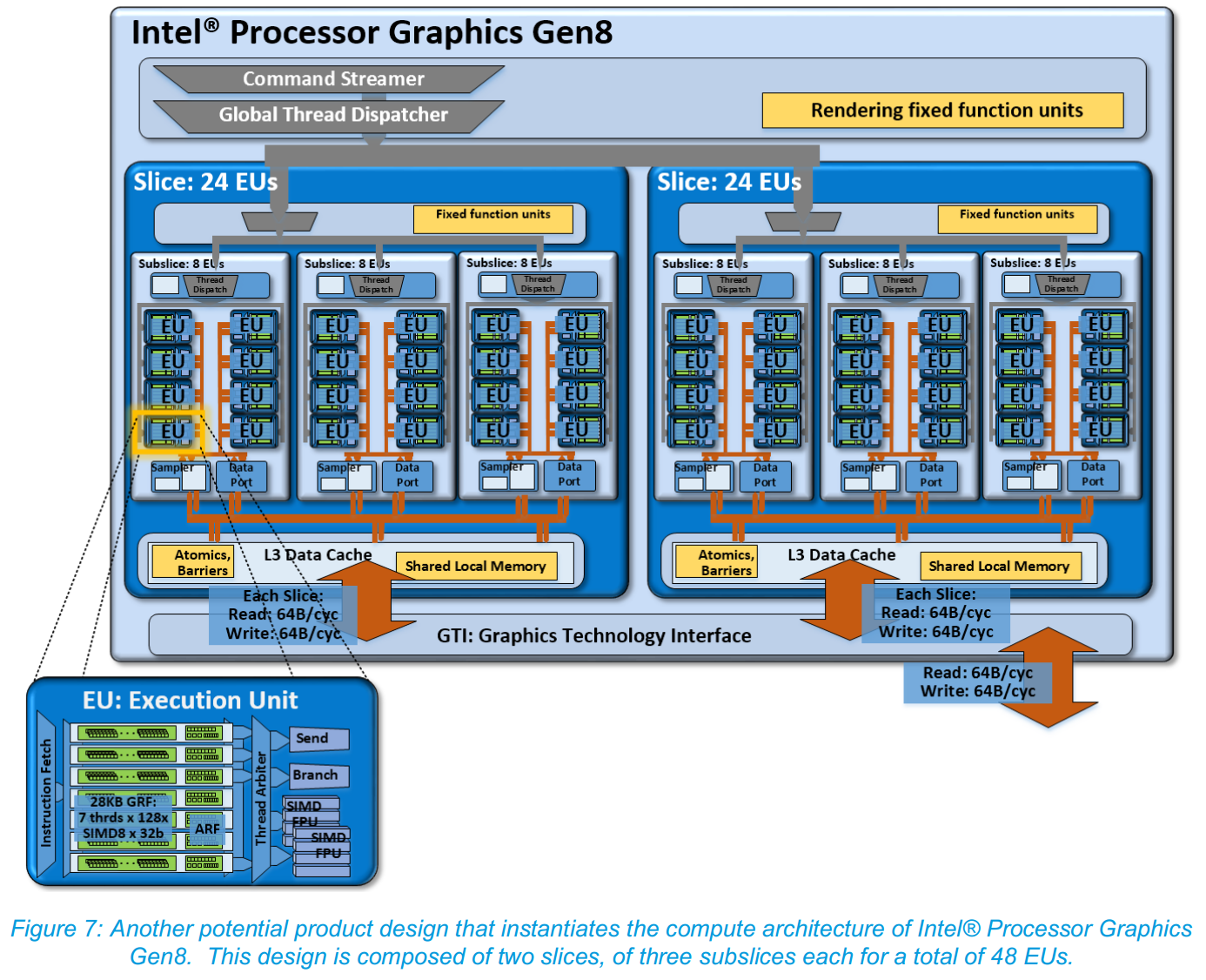
For Broadwell, Intel has reduced the number of EUs in a sub-slice from 10 down to 8. This is a big change, as it eases up the Thread Dispatch, Data Port and L1/L2 samplers in each EU as they have to deal with less data overall. By this logic, with two equivalent designs, one with 8 EUs per sub-slice should be able to get through more data due to less data bandwidth pressure and less competition for each sub-slice’s shared local memory.
Each slice has an L3 Data Cache, which for Gen8 is improved from 384 KB to 576 KB per slice. This ends up being split anyway as 64 KB per sub-slice as shared local memory and 384 KB for inter-slice L3 communication. More slices mean more caching overall, and as an aid to the last level cache outside the GPU, the Graphics Technology Interface has doubled the write bandwidth.

The principle behind caches is to provide a small amount of memory that can be accessed faster at the expense of size. The algorithms in place to predict which data is needed next (or preprogrammed data fetching) helps increase the overall speed of any CPU function, but increasing the size of a cache decreases the need for later caches by reducing the data misses that require trips further out. GPUs are historically bandwidth starved, both for gaming and for compute, so by virtue of having four named caches for the GPU to use and increasing at least the third, this should contribute to the large performance numbers Intel is producing in comparison to the previous generation.
In terms of throughput, Intel gives the following numbers for GT2 / 24 EU configurations:
32b FP: 384 FLOP/cycle = 24 EUs * (2 * SIMD-4 FPU) * (MUL + ADD)
64b DP: 96 FLOP/cycle = 24 EU * SIMD-4 FPU * (MUL + ADD) * 0.5 throughput
32b INT: 192 IOP/cycle = 24 EU * (2 * SIMD-4 FPU) * ADD
The Gen8 EUs will support 16-bit floats (half-floats) natively, as well as 16-bit integers.
We can construct a table calculating out to full performance:
| Intel Gen8 Graphics Throughput | |||
| Processor | 32b FP GFLOPs |
64b DP GFLOPS |
32b INT GFLOPs |
| i7-5557U (48 EUs at 1100 MHz) | 844.8 | 211.2 | 422.4 |
| i5-5257U (48 EUs at 1050 MHz) | 806.4 | 201.6 | 403.2 |
| i3-5157U (48 EUs at 1000 MHz) | 768 | 192 | 384 |
| i7-5250U (48 EUs at 950 MHz) | 729.6 | 182.4 | 364.8 |
| i7-5600U (24 EUs at 950 MHz) | 364.8 | 91.2 | 182.4 |
| i5-5300U (24 EUs a 900 MHz) | 345.6 | 86.4 | 172.8 |
| i3-5010U (23 EUs at 900 MHz) | 331.2 | 82.8 | 165.6 |
| i3-5005U (23 EUs at 850 MHz) | 312.8 | 78.2 | 156.4 |
| Pentium 3805U (12 EUs at 800 MHz) | 153.6 | 38.4 | 76.8 |
Having doubled the EUs not only doubles the performance but the extra bit of frequency also helps.
As we mentioned back in August, the sub-slice also gets some minor improvements to increase pixel and Z-fill rates, and the front end’s geometry units are also beefed up. Further reading can be found on Intel’s PDF on the Gen 8 Graphics Overview from IDF.








85 Comments
View All Comments
Jaybus - Monday, January 5, 2015 - link
Huh? Peak FP32 for x1 is 512 GFlops, substantially less than 48 EU Broadwell-U.name99 - Tuesday, January 6, 2015 - link
BUT Intel offer a coherent single address space for GPU and CPU compute. This is an important step on the path to practical commonplace heterogeneous computing. As far as I know nV aren't offering that in X1.(I'd be curious to know if Imagination are offering it in Rogue 7, because Apple are probably the company that's best set to put all the pieces of this together, from the hardware through the OS to the language+dev tools to the frameworks' but if IMG aren't on track, Apple are kinda screwed. Of course Apple COULD be preparing their mythical self-designed GPU...)
There's plenty to be irritated about with Broadwell, but let's praise the improvements that really are a good foundation for the future, and this is primary among them.
stephenbrooks - Tuesday, January 6, 2015 - link
GFlops not TFlops! And at FP32 the Tegra X1 peaks at 512 Gflops (source: http://anandtech.com/show/8811/nvidia-tegra-x1-pre... ).tipoo - Sunday, January 18, 2015 - link
*Twitch*Argh. The X1 gflop number you just gave is for half precision, it's their double speed FP16 mode. And then you're going and comparing that to a full precision number.
MattCoz - Monday, January 5, 2015 - link
I'm really interested to see what kind of performance improvement can be seen over my current Ivy Bridge i5-3317U. I really want to upgrade my laptop for numerous reasons, but after 2 years I'm looking for more than just a marginal increase in performance. I was very disappointed when Lenovo went with the Core M for the Yoga 3.TiGr1982 - Monday, January 5, 2015 - link
I have this same Core i5-3317U in Surface Pro 1 (1st gen, it works without throttling there, but two CPU fans are audible under heavy load). I believe, CPU-wise, you won't get really big improvements with Broadwell-U over Ivy-U. GPU-wise, however, Broadwell-U will be way faster.So, it depends on what you are interested in more: CPU progress, GPU progress, or both.
III-V - Monday, January 5, 2015 - link
I'm in the same boat. Think I have the same processor, too.I am looking at getting the inevitable Surface Pro 4. It looks like I'll be able to get the same CPU performance (assuming it's Broadwell-Y), and a fair bit better GPU performance, with much improved battery life. Should be good for my needs... Don't need too much number crunching power on the thing, and the graphics are a real sore spot on my Asus S400CA.
nwarawa - Monday, January 5, 2015 - link
I am concerned about the Broadwell Pentiums and Celerons overlapping with the new Cherry Trail.Up until now, Baytrail and Ivybridge Celerons have been sold in similarly priced systems. The Celeron might use a bit more power, but in a cheap laptop, or especially a little ITX box, it was worth it for the extra performance. The 1.5 IvyBridge cores still hold a noticeable lead over a Baytrail core at 2.6 (boost). They shared the same GPU generation, but the Celeron had 6 EUs to the Baytrail's 4 EUs, plus ran at a higher clock.
Now, apparently CherryTrail is going to have 16 EUs to Broadwell Celeron's 12 EUs. They both will have dual-channel LPDDR3-1600 interfaces, so unless the GT1 is clocked significantly higher, this will be the first time an Atom has a better GPU than its mainstream contemporary.
As for the CPU portion, for years the cheapest Celeron U has hardly budged in clockrate, from the 1.4 Sandybridge to the new 1.5 Broadwell. So these chips' upgrades have depended almost entirely on process improvements. The process improvements from BayTrail to CherryTrail sound a bit more aggressive than those from Haswell to Broadwell. So, if Intel ends up clocking the CherryTrail higher too (say, 2.8boost), we may also have situation were the CherryTrail has near CPU performance parity with the Broadwell Celeron.
naloj - Monday, January 5, 2015 - link
Looks like Intel has published the specs of the Broadwell-U NUC line:http://www.intel.com/content/www/us/en/nuc/product...
ayejay_nz - Monday, January 5, 2015 - link
Thanks a lot for this link!