ARM A53/A57/T760 investigated - Samsung Galaxy Note 4 Exynos Review
by Andrei Frumusanu & Ryan Smith on February 10, 2015 7:30 AM ESTMali T760 - Architecture
The Midgard GPU architecture has been around for over two years now since we saw the first Mali T604MP4 implemented in the Exynos 5250. Since then ARM has steadily done iterative improvements to the GPU IP resulting in what we now find in the Exynos 5433: the Mali T760. Over the last summer we've had the pleasure of getting an architectural briefing and disclosure from ARM, which Ryan has covered in his excellent piece: ARM’s Mali Midgard Architecture Explored. It's a must-read if you're interested in the deeper workings of the current generation Mali GPUs employed by Samsung and other vendors.
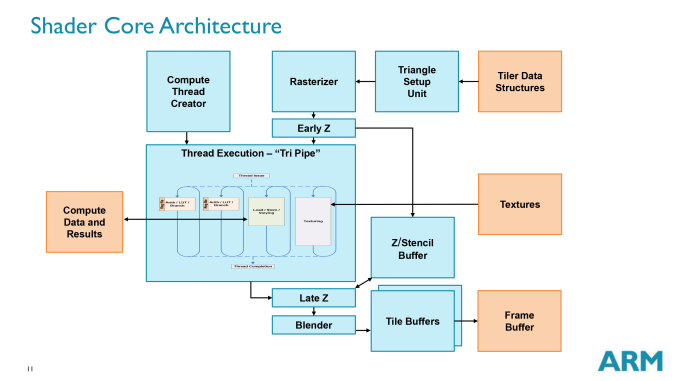
The T760's predecessor, the T628, has been now used for over a year in the Exynos 5420, 5422, 5430, 5260 and HiSilicon Hi3630, and regrettably it wasn't as competitive as we would have wished, in terms of performance and in power efficiency. Hoping that the T760 brings the Mali GPU in better competitive shape, there are two main points that we should be expecting from the T760 in terms of advancements over the T628.
- Improved power efficiency due to internal wiring optimizations between the cores and the L2 cache.
- Improved performance and power efficiency due to both reduced bandwidth usage and increases in effective usable bandwidth by help of ARM Frame-Buffer Compression (AFBC).
Mali T760 - Synthetic Performance
To be able to do an architectural comparison, I lock the T628 and T760 to 550MHz so that we can get a directly comparable perf/MHz figure for both architectures. Since both SoCs have the same internal bus architecture, same memory speed, and even same cache sizes on the GPU, performance differences should be solely defined by efficiency gains of the new architectural additions of the new Midgard GPU in the Exynos 5433. To do this we use GFXBench as the base comparison benchmark as it is our de-facto benchmark for graphics.
| GFXBench @ 550MHz Offscreen | ||||||
| Mali T628MP6 | Mali T760MP6 | % Advantage | ||||
| Manhattan | 12.8 fps | 14.5 fps | 13.2% | |||
| T-Rex | 31.5 fps | 35.1 fps | 11.1% | |||
| ALU performance | 42.4 fps | 41.6 fps | -1.8% | |||
| Alpha-blending | 3006.5 MB/s | 3819 MB/s | 27% | |||
| Driver overhead | 29.1 fps | 45.05 fps | 55.3% | |||
| Fill-rate | 2907 MTexels/s | 3120 MTexels/s | 7.3% | |||
If we begin with the synthetic numbers first, we see that there is a non-change in ALU throughput, with only a minor 1.8% decrease in performance over the T628MP6. The tri-pipe design hasn't changed on the T760 so this was an expected result. The small decrease could be attributed to many things but I don't think it's worth any serious attention.
It's on the alpha-blending test things get interesting: performance jumps 27% compared to the T628 at the same frequency. I initially thought this would have been an effect of AFBC and the resulting increased bandwidth, but ARM has explained this is an architectural improvement of the new Midgard generation on the T7XX series. The 7.3% fill-rate increase might also be a gain of this particular addition to the T760.
Completely unrelated to any architectural changes is a massive 55% boost in the driver overhead score. The Galaxy Alpha shipped with an r4p0 driver release while the Note 4 sports r5p0 Mali drivers. This is an outstanding increase for Android as it not only gives the T760 and ARM's new drivers a big advantage over its predecessors, but it also now suddenly leads all Android devices in that particular benchmark by a comfortable margin.
We've seen that Android devices have traditionally suffered in this test while iOS phones and tablets lead by a factor of 3x. This confirms a long-standing suspicion that we're still a long way from achieving acceptable driver overhead on the platform. I was curious as to what ARM did here to achieve such a big increase, so I reached out to them and they happily responded. The r5pX drivers improve on three main areas:
- Workload efficiency: The shader compiler was updated to make better use of the shader pipelines and achieve better cycle efficiency; in the case of the T760 there are also optimizations to AFBC usage.
- Improved driver job scheduling: Improvements to the kernel job scheduler making sure that hardware utilization is as close to 100% as possible.
- Overall optimizations to reduce CPU load, allowing for more performance in CPU-bound scenarios and otherwise lower power consumption.
At the same time it should be noted that CPU performance certainly also plays a part in driver overhead scores - when measuring overhead we're essentially measuring how much CPU time is being spent on the drivers - though how big of a role is up for debate. A57 in particular offers some solid performance increases over our A15-backed Exynos 5430, which can influence this score. However in testing, by lowering the CPU performance I was only able to get down to 29fps in the driver overhead test when limiting the frequency to 1 GHz on the A57 cores, giving much lower performance than the what the 1.8GHz A15 would achieve.
Based on the above, I believe that if ARM can bring these driver improvements to previous generation devices there should be a sizable performance boost to be had. It won't be as great due to the lack of the corresponding A57 CPU, but it should still be a solid boost.
Overall, the aggregate of these new technologies can be measured in the Manhattan and T-Rex practical tests. Here we see an 11-13% increase of performance per clock. Ultimately this means that the raw performance gains from the T760 alone are not going to be huge, but then as T760 is an optimization pass on Midgard rather than a massive overhaul, there aren't any fundamental changes in the design to drive a greater performance improvement. What we do get then from T760 is a mix of performance and rendering efficiency increases, power efficiency increases, and the possibility to be a bit more liberal on the clock speeds.
Power Consumption
I was first interested to see how ARM's GPU would scale in power and performance depending on core count. To do this I locked the system again to the little cores as to avoid any power overhead the A57 cores might have on the measurement. I locked the GPU to 500MHz as I wanted to do a direct comparison in terms of scaling with the T628 and chose that frequency to run both devices; however, that ended up with bogus numbers for the T628 as there seems to be some misbehavior in the drivers of the Galaxy Alpha when trying to limit the core count to less than the full 6-core configuration.
In any case, I was more looking to get an impression of the inevitable overhead of the CPU and rest-of-SoC and how power consumption scales between cores. I'm using GFXBench's T-Rex Offscreen test to measure these power figures, again with already-accounted screen and system idle power consumption.

As we see in the chart, using additional cores on the Mali T760 seems to scale quite linearly. Adding an additional core adds on average another 550mW at 500MHz to the total power consumption of the system. If we actually go subtract this figure from the MP1 power value we end up with a difference of around 550mW that should be part CPU, RoS (Rest-of-SoC), memory, and common blocks on the GPU that are not the shader cores. Of course this is all assuming there is no power increase on the CPU and RoS due to increased load of the GPU. It's quite hard to accurately attribute this number without doing hardware modifications to the PCB board to add sense resistors to at least five voltage rails of the PMIC, but for our purposes it gives a good enough estimate for the now following measurements.
As mentioned I wanted to include the T628 in the same graphs, but due to driver issues I can only give the full-core power consumption numbers. The Exynos 5430 used 3.74W at the same 500MHz lock; this 110mW difference could very well be just the increased consumption of the A53 cores over the A7 cores, so it seems both GPUs consume the same amount of power at a given frequency.
In terms of performance, the Mali T760 scaled in a similar way as the power consumption:
| Mali T760 Core Performance Scaling @ 500MHz | ||||||
| MP1 | MP2 | MP3 | MP4 | MP5 | MP6 | |
| fps | 5.8 | 11.5 | 17 | 22.5 | 27.6 | 32.2 |
| fps per core | 5.8 | 5.75 | 5.66 | 5.62 | 5.52 | 5.36 |
We see a slight degradation of ~1-1.5% on the per-core fps with each additional core but this seems within reasonable overhead of the drivers and hardware. All in all, the scaling on Mali T760 seems to be excellent and we should be seeing predictable numbers from future SoCs that employ more shader cores. The T760 supports up to an MP16 configuration, and while I don't expect vendors to implement this biggest setup any time in the near future, we should definitely see higher core numbers in future SoCs this year.
Again, I can only give the MP6 number for the T628 here: 26.2fps. This means that the T760 is roughly 23% more efficient in terms of perf/W than its predecessor while operating at the same frequency. In the aspect of silicon efficiency, this is also an improvement. The Mali T760MP6 on the 5433 comes in at 30.90mm² 25mm² of the total SoC area, only a meager 0.29mm² more than the T628MP6 in the Exynos 5430.
While until now I was measuring performance and power consumption at a fixed frequency for facultative reasons, it's time to see what the GPU is actually capable of at it's full frequency. But there's a catch.
While I initially reported that the T760 on the 5433 was running at 700MHz, and that frequency is indeed used as a maximum of the DVFS mechanism, there's also a secondary maximum frequency of 600MHz. How can this be? In fact the DVFS mechanisms of both the 5430 and 5433 have a new addition in their logic that is both very unusual and maybe, dare I say, innovative in the mobile space.
Until now, and for all other SoCs other than these two, classical DVFS systems would base their scaling decision on the general load metric provided by the GPU drivers. This is normally computed by reading out some hardware performance counters from the hardware. The DVFS logic would take this load metric and apply simple up- and down-thresholds of certain percentages to either increase or decrease the frequency.
In the case of both 5430 and 5433, Samsung goes deeper into the architecture of the Mali GPU and retrieves individual performance counters of each element of a tri-pipe.

It evaluates the individual load of the (combined) arithmetic pipelines (ALUs), load/stores unit (LS), and the texture (TEX) unit. What it does is that when the load on the LS unit exceeds a certain threshold, the higher DVFS frequency of 700MHz is blocked off from being reached. Similarly it also denies the higher frequency when the ALU utilization is greater than 70% of the LS utilization.
In practice, what this does is that workloads that are more ALU heavy are allowed to reach the full 700MHz while anything that has a more balanced or texture-heavy usage stays at 600MHz. This decision making is only valid for the last frequency jump in the DVFS table, as anything below that uses the classical utilization metric supplied by the ARM drivers. This is the main reason why I needed to cap the GPU frequency to a P-state that is not affected by this mechanism, as it's not possible to disable it by traditional means and I needed to run the same frequency on both the T628 and T760 for the synthetic performance benchmarks.
Now as to why this matters for the general user, the 700MHz state in the Exynos 5433 comes with a vastly increased power requirement, as it's clearly running a high overdrive state at 1075mV versus 975mV at 600MHz. This means that the 700MHz state is 42% more power hungry than the 600MHz state, and in fact, we'll see this in the full power figures when running under the default DVFS configurations.

On the T628 this overdrive state happens on the 550MHz to 600MHz frequency jump. Here the power penalty should be less heavy as the voltage and frequency jump account for a "mere" theoretical 13% increase.
I've always suspected that the Manhattan test was more of an ALU heavy test compared to past Kishonti benchmarks. What this peculiar DVFS mechanism on the 5433 allowed me to do is actually confirm this as I could see exactly what is happening on the pipelines of the GPU. While the texture load is more or less the same on both Manhattan and T-Rex, the load/store unit utilization is practically double on the T-Rex test. On the other hand, Manhattan is up to 55% more ALU heavy depending on the scene of the benchmark.
The result is that power draw in Manhattan on the 5433 is coming in at a whopping 6.07W, far ahead of the 5.35W that is consumed in the T-Rex test. Manhattan should actually be the less power hungry test on this architecture if the tests were to be run at the same frequency and voltages. We can see this in the Exynos 5430, as the power draw on Manhattan is lower than on T-Rex, even though it's using that 13% more power intensive 600MHz hardware state.
Why Samsung chose to bother to implement this state is a mystery to me. My initial theory was that it would allow more ALU heavy loads to gain performance while still keeping the same power budget. ARM depicts the ALU inside the tri-pipe diagram in a smaller footprint as the LS or TEX units, which traditionally pointed out to a very rough correlation of the actual size of the blocks in silicon. The huge jump in power however does not make this seem viable in any realistic circumstance and definitely not worth the performance boost. I can only assume Samsung was forced to do this to close the gap between the Mali T760 and Qualcomm's Adreno 420 in the Snapdragon 805 variant of the Note 4.
I have yet to do a full analysis of today's current games to see how many of them actually have a heavy enough ALU workload to trigger this behavior, but I expect it wouldn't be that many. BaseMark X for example is just on this threshold as half the scenes run in the overdrive state while the other half aren't ALU heavy enough. For everything else the 600MHz state is the true frequency where the device will cap out.
| Exynos 5430 vs Exynos 5433 T-Rex Offscreen Power Efficiency |
||||||
| FPS | Energy | Avg. Power | Perf/W | |||
| Exynos 5430 (stock) | 31.3 | 80.7mWh | 5.19W | 6.03fps/W | ||
| Exynos 5433 (stock) | 37.7 | 91.0mWh | 5.85W | 6.44fps/W | ||
| Exynos 5430 (little lock) | 29.3 | 73.2mWh | 4.71W | 6.23fps/W | ||
| Exynos 5433 (little lock) | 37.3 | 88.6mWh | 5.70W | 6.55fps/W | ||
The end power/W advantage for the T760 at its shipped frequencies falls down to under 6% because of the higher clocks and voltages. Another peculiarity I encountered while doing my measurements was that the Exynos 5430 was affected much more by limiting the system to the little cores. Here the Mali hits CPU-bound scenarios immediately as the scores drop by 7% on the off-screen test and a staggering 26% on the on-screen results of T-Rex. Usually GFXBench is a relatively CPU light benchmark that doesn't require that much computational power, but the A7 cores are still not able to cope with simple 3D driver overhead. The 5433 on the other hand is basically not affected by this. This is a very good improvement as it means much less big core activity while gaming, one of big.LITTLE's most damning weak-points.
I'm still not satisfied with the power consumption on these phones, a little over 5.7W TDP is certainly unsustainable in a phone factor and will inevitably lead to thermal throttling (as we'll see in the battery rundown). Apple's SoCs here definitely have a power efficiency advantage no matter how you look at it. I'm curious to see how an Imagination GPU would fare under the same test conditions.
All in all, as the T700 series is largely an optimization pass on Midgard, the resulting T760 brings some improvements over its T628 counterpart but it's not as much of an improvement as I'd like to see. Since doing these measurements I've received a Meizu MX4Pro that also sports an Exynos 5430, but it came with an average binned chip as opposed to the almost worst-case found in the Galaxy Alpha that I've used for comparison here. In preliminary measurements I've seen almost a 1W reduction in power over the Alpha.
This leaves me with a blurred conclusion on the T760. There is definitely an improvement, but I'm left asking myself just how much of this is due to the newer drivers on the Note 4 or just discrepancies between chip bins.








135 Comments
View All Comments
tipoo - Tuesday, February 10, 2015 - link
Agreed, it was a little shocking to see that even the Cortex A57 is stomped on by the A8/Cyclone R2. And that with two cores and sane clock speeds.I would say this is what everyone else would be doing, ideally, but the cost here is die size. Instead they shoot for smaller higher clocked designs to save some die size and cost, since other companies aren't willing to pay as much for the SoC in the BoM as Apple is.
ruggia - Tuesday, February 10, 2015 - link
to be fair, the basic minimum performance Cyclone R2 have had to achieve was beat A57, since that was the reference design available from ARM for everyone. So I don't think it's that surprising.tipoo - Tuesday, February 10, 2015 - link
On the other hand, them and Nvidia alone have parts better than the A57 per-core out, and even from those two the 64 bit Denver K1 is too high in power draw and chokes on some tasks due to its code morphing engine bottlenecking the process.So it is still remarkable, to me, how early and how long Apples lead has lasted.
Kidster3001 - Friday, February 27, 2015 - link
Why do we need octa cores in phones/tablets? Marketing says we do, plain and simple. It's bragging rights. No real benefit but it sounds cool. Apple is doing it wider and smarter.DarkLeviathan - Saturday, December 19, 2015 - link
But unfortunately people are getting dumb-er and stupid-er (XD). Falling into marketing ploys. I feel like Apple is the one who is not marketing crazy now. Its all numbers with the Android people :/ Apple cares about user experience more than any other companies and they spend a lot more money on it.xdrol - Tuesday, February 10, 2015 - link
Please go compare it to nVidia Denver cores.tipoo - Tuesday, February 10, 2015 - link
I have. It wins some benchmarks, but is less consistent in the real world because it's a code morphing design that can get choked up by unpredictable code. It's also more power hungry, though that's partly the fab.lilo777 - Tuesday, February 10, 2015 - link
bigstrudel, you are either Apple fanboy or a troll. For your own sake I hope it's the former and you understand that what you posted is pure nonsense. The only tests where iPhone dominates Samsung phones are specint and basemark tests. But the reason for that is not what you probably think it is. Specint benchmarks use only one core. Sure, A8 core is faster but then iPhone has just two of them. The total power of four cores is higher than that of two A8s. And it's not like the two A8 cores consume twice less power than four Samsung cores. A8 is a very BIG core. Each A8 core uses more power than a single Samsung core. And basemark scores... Those depend on screen resolution and iPhone has a very low resolution compared to Note 4. In short, both approaches (two large cores or big.LITTLE architecture) have pros and cons. There is no magic here. It is not clear to me why would you say that A8 "stands light years ahead" when the phone based on this SOC (iPhone 6) lags high end Android phones in synthetic benchmarks like Geekbench.DarkLeviathan - Saturday, December 19, 2015 - link
1. The CPU and resolution has almost nothing in which you can compare with2. If you do a little research and stop drinking that Samsung marketing soup, you would realize that not all the Samsung cores are not the same. They vary in power...
PC Perv - Tuesday, February 10, 2015 - link
Apple A series is already eclipsed by Exynos 5433 as seen by sub-test scores in Geekbench. (how does Geekbench calculate aggregate score? I have no idea) A8 will also be crushed and humiliated by soon-to-arrive Exynos 7420.Dual-core is the best configuration? My ass. That is why they added another core in the new iPad. Oh, if you look at the die shot there is a space for a 4th core there, too.