ARM A53/A57/T760 investigated - Samsung Galaxy Note 4 Exynos Review
by Andrei Frumusanu & Ryan Smith on February 10, 2015 7:30 AM ESTCortex A57 - Architecture
Shifting gears to a look at the Exynos 5433’s high-performance CPU cores, we have the Cortex-A57, the successor to ARM's earlier ARMv7 Cortex-A15.
As ARM’s first high-performance ARMv8 core, A57 is jumping into an interesting market. A57’s first year is likely to be even more successful than A15 was, and yet this is going to be the most competitive landscape yet within the ARM ecosystem, thanks to a larger number of ARM architecture licensees than ever before. Many of these licensees are in the server realm – companies like AppliedMicro who are making a run at the server market – meanwhile others such as Apple and NVIDIA have used their designs in the consumer market, even beating out A57 by nearly a year in the case of Apple. Still, within the narrower confines of the Android space, A57 is currently the CPU to beat for 2015, with everyone from Samsung to Qualcomm licensing the design for their high-end CPUs.

Diving into A57 itself then, A57 is in many ways a direct evolution and continuation of the A15 design. Intended for 28nm and newer nodes, A57 essentially picks up where A15 left off, introducing ARMv8 support while further ramping up ARM's IPC, overall single-threaded performance, and even energy efficiency. Under the hood ARM has made a number of changes to improve efficiency while retaining other elements of A15 that still make sense. The end result is something akin to an Intel “tock”, meaning we’re looking at something that isn’t a massive overhaul of the architecture (e.g. Cyclone or Denver) but institutes a number of new features and optimizations.

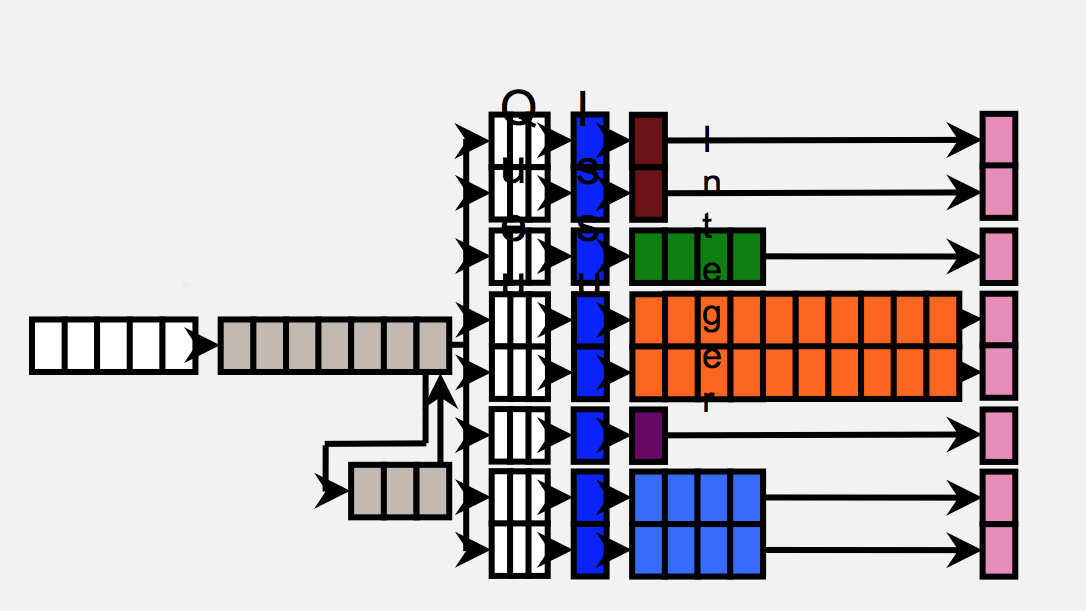
A57 is at its heart a fully out-of-order design, making for a very interesting contrast to NVIDIA’s Denver, which we took a look at last week. This basically being the norm to NVIDIA’s unorthodoxy, A57 is a much more traditional CPU design that follows ARM’s historical design tendencies and is similarly intended to fit in roughly the same design envelope as A15.
From a high-level perspective, ARM makes a fairly straightforward tradeoff in terms of performance and power consumption. A57 is designed to be bigger and more performant than A15, but in turn it can consume more power as well. ARM’s internal projections for A57 are that it can achieve 25-50% better IPC at a cost of 20% higher power consumption if built on the 28nm node. In terms of overall energy efficiency this should leave A57 with a decent edge over A15, thanks to performance increases outpacing the power consumption increase.
The wildcard factor in all of this will be the manufacturing node, especially the temperamental 20nm processes. While A57 can be produced on 28nm, in keeping with the pace of manufacturing technology and the need to offset its larger size, the first consumer A57 designs like the Exynos 5433 are being produced at 20nm, as opposed to 28nm for the bulk of A15 designs. The smaller process helps to keep the size of A57 relatively small – enough to easily fit four cores on an SoC – and it means that we’re getting the power efficiency gains that come from a smaller process node, adding to A57’s architectural gains. However it also means that the performance gains on shipping A57 SoCs are going to be influenced by manufacturing factors such as leakage and the viability of higher clock speeds, so the real-world performance gains over A15 are going to be a bit more variable. Overall ARM is pushing for a higher IPC design in part to better control these factors, as higher IPC designs would allow for partners to ramp down the clock speeds a bit, and thereby voltage and power consumption.
In any case, let’s talk about the design of the A57. In creating the A57, ARM tells us that their goal was to design the CPU around the kinds of compute workloads they expect to see over the next few years, in order to get the best real-world performance out of their design. To that end, ARM says that in planning A57 they found that mobile workloads aren’t as instruction pipeline sensitive as they once were, and as a result the biggest bottlenecks aren’t in the pipeline itself but rather in feeding the pipeline. Consequently, A57’s design has made fewer changes to the A15 pipeline and focused more on improving the hardware supporting the pipeline, such as fetch, decode, and out-of-order execution capabilities.
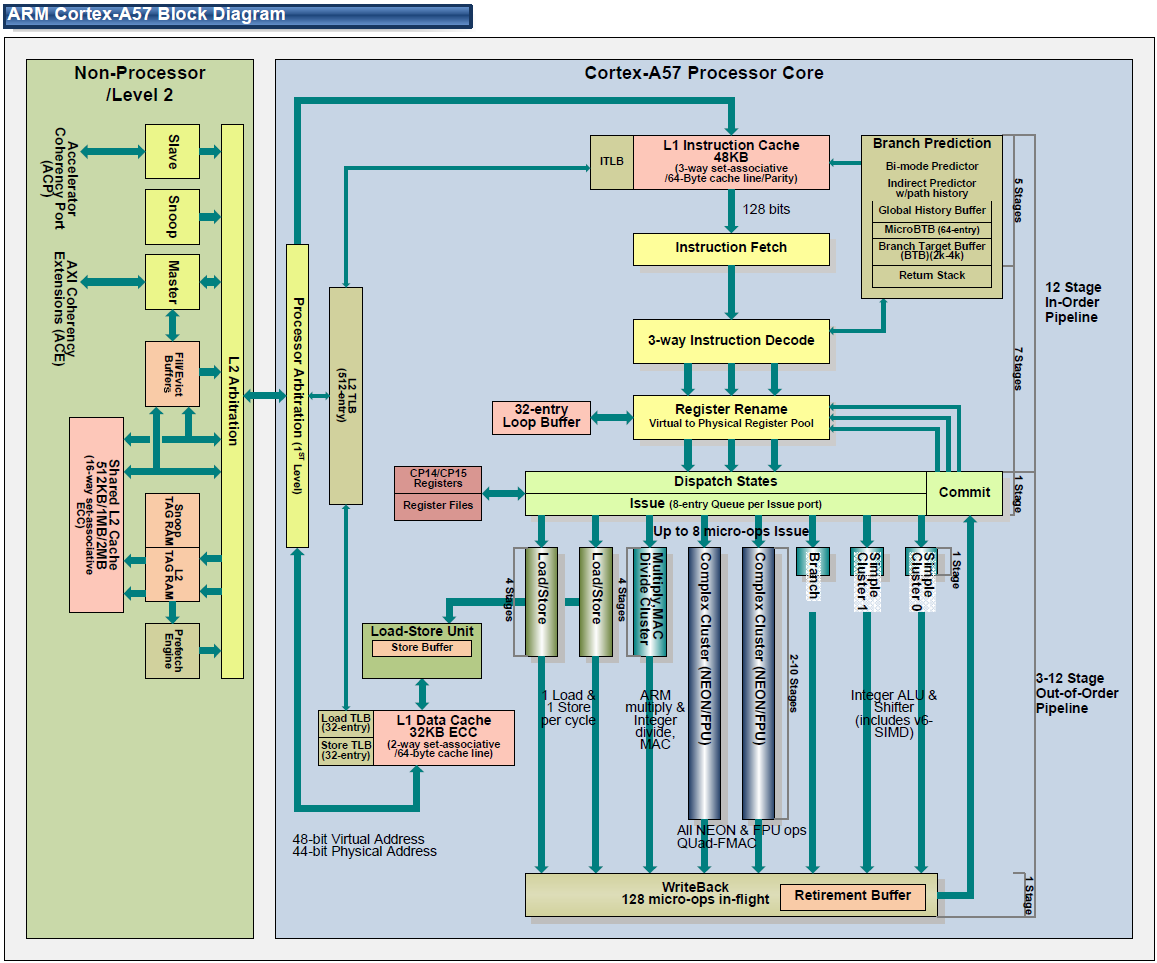
Image courtesy of Hiroshige Goto
Starting at the front then, at the fetch stage ARM has made numerous small changes. The L1 cache has been expanded from 32KB in A15 to 48KB in A57, and similarly its associativity has gone from 2-way to 3-way. The overall increase in cache helps to improve performance, though perhaps more importantly the larger instruction cache helps to offset the larger size of the 64-bit ARM instructions. Meanwhile the Branch Target Buffer, used to store past branches and better predict future branches, has seen its size doubled entirely, now coming in at 2K-4K. Meanwhile on the data side the L1 data cache is left unchanged at 32KB.
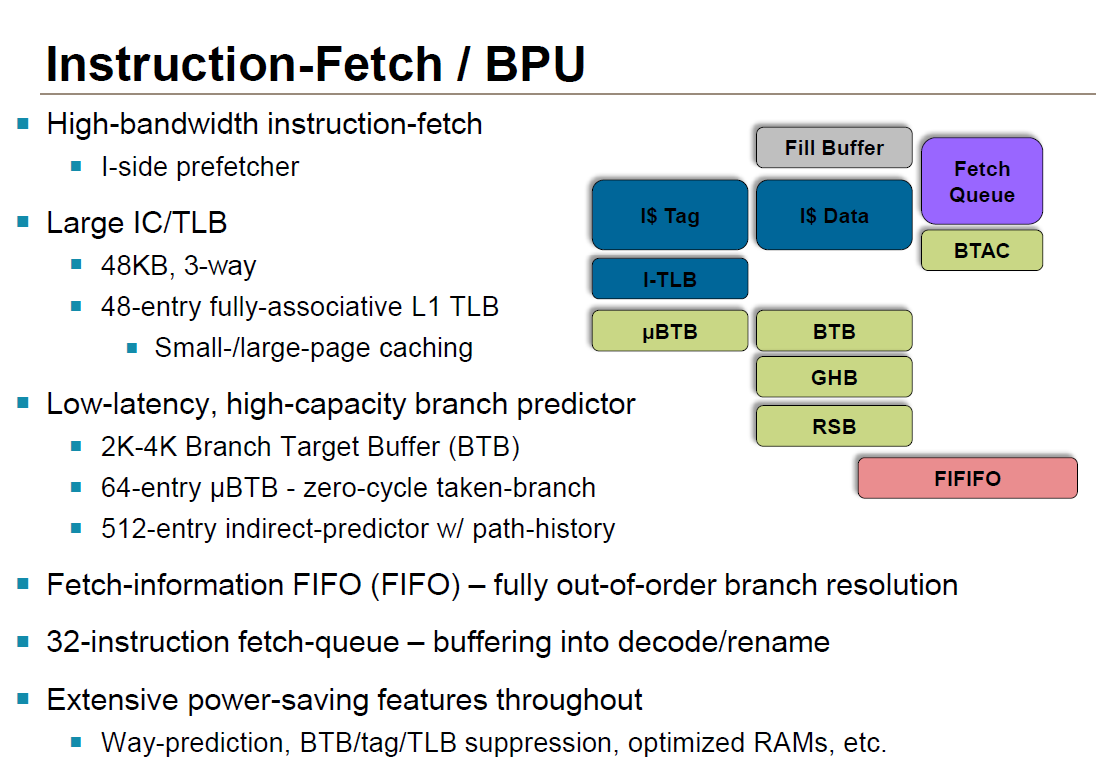
L2 cache on the other hand is configurable on a per-SoC basis. A57 supports L2 cache sizes between 512KB and 2MB, with the cache being 16-way set-associative. Each A57 core gets its own interface to the L2 cache, so there is no bandwidth sharing at the interface level. It also bears mentioning at this point that with A57 ARM now supports multiple memory page sizes on top of the standard 4K memory page size, though the larger pages are primarily for server use.
For instruction decoding, A57 retains the familiar 3-wide decoder front-end. ARM always faces a fine balancing act on decoder size – wider decoders are physically larger – and as with A57 this falls in line with ARM’s goal to focus on feeding the pipeline as opposed to the pipeline itself, as ARM believes they are not yet at the limit of a 3-wide pathway. Though not wider, the decoder has seen other changes to improve performance and power efficiency. Of particular note, the various decode planes for each instruction set – Thumb, NEON, AArch64, and ARMv7 – can now be power gated so that only the decode plane necessary is powered up, helping to offset the cost of needing to support four different instruction formats. Register renaming has also been tweaked at the decode stage, particularly to take advantage of the fact that ARMv8 allows for a flat register map, as opposed to the earlier banked register map.
Meanwhile ARM has also made a few important changes at the instruction dispatch and execution stage. Of note, the instruction window for OoOE has once again been increased in size; ARM still isn’t commenting on the precise size, but it is said to be able to hold more than 128 instructions to further improve OoOE performance. Elsewhere the register file has been given its own enhancements, primarily for AArch64 compatibility. Each 4K segment of the register file can now be configured as 128 32-bit registers or 64 64-bit registers, allowing for relatively small portions of the file to be switched over to 64-bit mode and avoiding wasting space on values that don’t require the larger register format.

| ARM CPU Core Comparison | ||||||
| Cortex-A15 | Cortex-A57 | |||||
| ARM ISA | ARMv7 (32-bit) | ARMv8 (32/64-bit) | ||||
| Decoder Width | 3 micro-ops | 3 micro-ops | ||||
| Pipeline Length | 18 stages | 18 stages | ||||
| Branch Mispredict Penalty | 15 cycles | 15 cycles? | ||||
| Integer Add | 2 | 2 | ||||
| Integer Mul | 1 | 1 | ||||
| Load/Store Units | 1 + 1 (Dedicated L/S) | 1 + 1 (Dedicated L/S) | ||||
| Branch Units | 1 | 1 | ||||
| FP/NEON ALUs | 2x64-bit | 2x128-bit | ||||
| L1 Cache | 32KB I$ + 32KB D$ | 48KB I$ + 32KB D$ | ||||
| L2 Cache | 512KB - 4MB | 512KB - 2MB | ||||
As for the pipeline itself, both the integer and floating point units have seen some upgrades for performance and 64-bit compatibility reasons. Though ARM doesn’t go into great detail on how they have this arranged, they have integer datapaths for both 32-bit and 64-bit execution, allowing them to only fire up the 64-bit path when they need it. Additional paths do create some complexity, but the pay-off over a single 64-bit path is that additional transistors are not fired up and additional power burnt just to run 32-bit code.
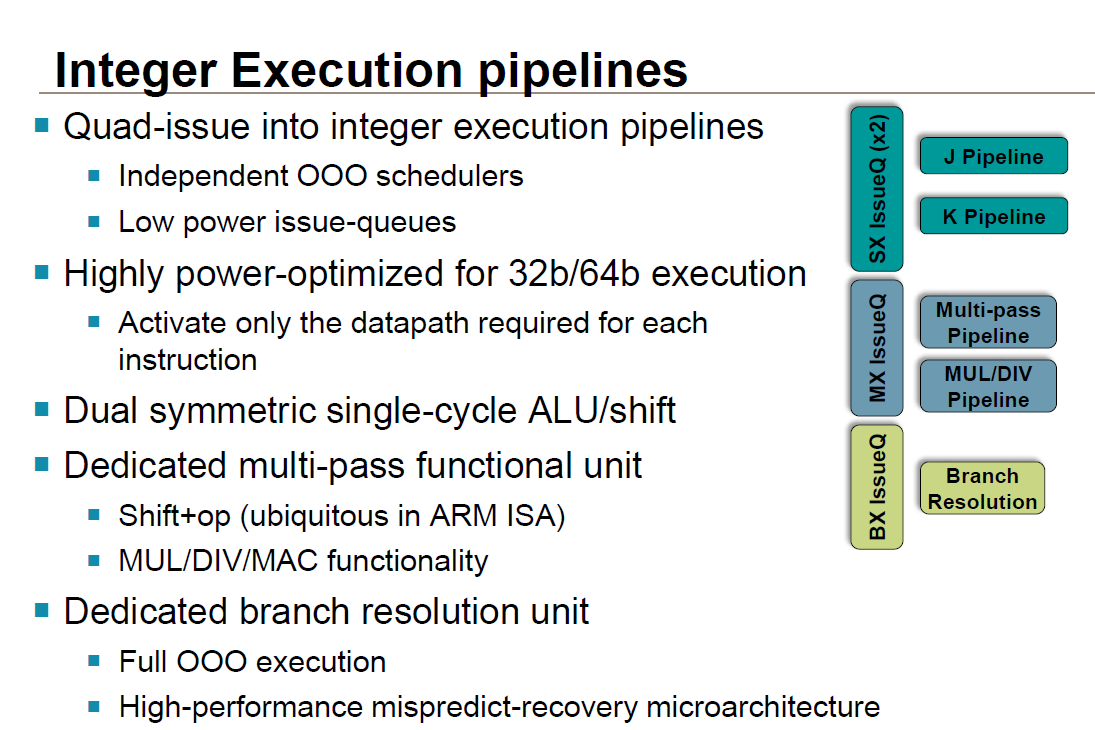
The floating point/NEON units on the other hand are outright wider, doubling from 64-bits to 128-bits and in turn potentially doubling NEON performance (when the FP units can be fully fed). Unlike the integer pipeline there aren’t separate paths for different data sizes, but ARM does tell us that they have worked in some further power optimizations to keep power usage down. These units are now also IEEE-754-2008 compliant when executing ARMv8 code. For the consumer market this does not have much of an impact, but it is an important distinction for the server market, which is another area ARM is hoping to get the A57 into now that they have 64-bit addressing capabilities. Finally, A57 supports an optional cryptography accelerator unit at this stage to speed up AES and SHA1/SHA2-256 performance.

Last but certainly not least, the load/store units have learned a few new tricks as well. Loads can now bypass non-disambiguated stores, which is good for around another 5% increase in performance. At the same time a dependence predictor is now in place at this stage, primarily to help improve OoOE performance by preventing A57 from over-speculating and otherwise harming performance during speculative memory operations.
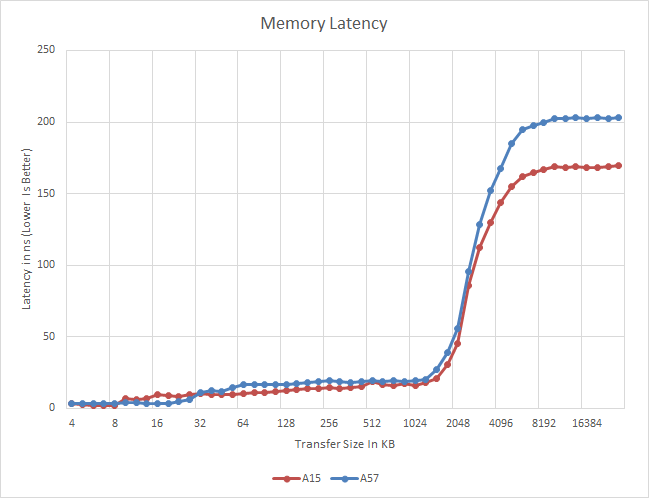
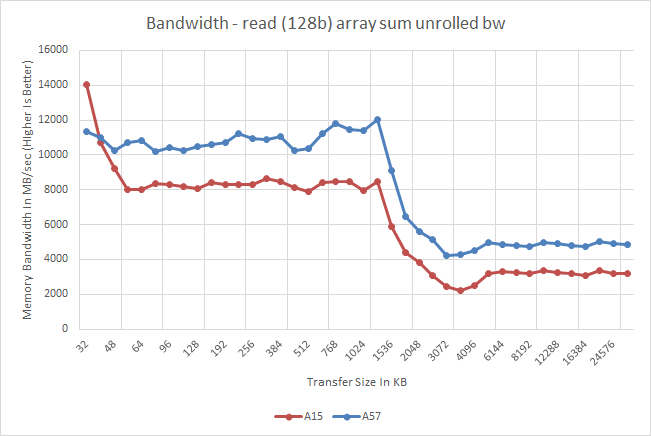
Meanwhile a quick look at memory latency and bandwidth on the A57 cores in the Exynos 5433 finds an unexpected pairing. Latency is virtually unchanged from the A15 through the L2 cache, but once it hits main memory the latency increases by nearly 40ns. On the other hand memory bandwidth is consistently better on the A57, even in cache. As far as latency is concerned this may be due to a Samsung design decision in the SoC itself. Meanwhile the improved bandwidth is likely a consequence of A57's various enhancements to improve throughput within the CPU cores.
ARM's relatively poor memory bandwidth figures have garnered them a poor reputation when it comes to memory performance, but what we are seeing here might be a gross misrepresentation of real-world performance. To understand how these figures come to be, we need to look at how the CPU is wired to the SoC's interconnect and memory controllers. ARM, as opposed to designs by Apple or NVIDIA, uses separate read and write data-ports in its fabric. On the cluster level, this is a dual 128-bit interface (one for reads, one for writes) that connects to matching ports of the SoC's memory controllers via the CCI's (Cache Coherent Interconnect) crossbar architecture. On the Exynos 5430 and 5433, the CCI runs at half the DRAM frequency, meaning 412.5 MHz for the aforementioned SoCs. This results in a maximum physical bandwidth of 6.6 GB/s in each direction.
What most of today's synthetic benchmarks portray is only the bandwidth measured in either direction, giving ARM a distinctive disadvantage. Total achievable bandwidth can reach double these figures. In fact, when we execute simultaneous read and write tests (multithreaded on two CPUs) we benchmark bandwidth numbers reaching the theoretical peaks of the memory controllers at 13.2GB/s. Interestingly, it seems ARM is employing the same setup to the L2 cache as bandwidth there also doubles to up to 25GB/s for the 5430's A15 and 27.5GB/s for the 5433's A57 clusters.
As to why ARM prefers this kind of configuration is a good question. We suspect that there may be power or latency advantages to the design, but we cannot be certain of it. Overall, it should have less of an impact in real-world scenarios as the benchmarks would lead one believe. Use cases where computations are either read or write heavy should only appear in scenarios such as video encoding or texture decompression such as loading video game assets, with the the former not being a real issue in the mobile space due to fixed-function hardware dedicated to the task.
Overall then, as put together A57 serves as the natural step up from A15, both in terms of the underlying design and of the overarching architecture. There is no single great change to drive performance here – and in fact the instruction pipeline isn’t much different in execution – but by focusing on building out for AArch64 execution and improvements to better feed those pipelines, ARM expects that they can get a significant IPC increase over A15. Coupled with 20nm and later 16nm/14nm processes ARM and their partners are hoping to push A57 far, though given the fact that A15 was already a bit power hungry in phones, it will be interesting to see how much of those process gains are spent on performance (clock speeds) and how much is spent on bringing down power consumption.

Meanwhile, ARM’s long-term plans for A57 also call for it to lead a double-life as a server CPU. With a 64-bit memory space, applications running on the A57 can finally address all the memory they need (and then some), so coupled with the IPC increase ARM is hoping to crack the server market in a way that early A15 efforts never did. Among the first companies shipping a server CPU will be AMD and their A1100, so it will be interesting to see how A57 plays out in the server market over the coming year.








135 Comments
View All Comments
aryonoco - Wednesday, February 11, 2015 - link
Everyone is aware that developing a power-aware scheduler is a VERY hard problem. The Linux kernel doesn't have it, but neither does anyone else really.The problem is that when ARM developed big.LITTLE, they would have known that for it to work, it requires a well-designed power-aware scheduler. And they should have known that that's a very hard problem to solve in software. History is littered with great hardware architectures that should have performed a lot better, if only the software was up to it, e.g., Intel's Itanium or Transmeta's Crusoe. But history has time and time shown that architectures that require too clever a software solution around them just don't work (perhaps one should add AMD's Bulldozer to this list as well, seeming as AMD expected everyone to rewrite their software to become GPU aware).
I remember back in the days KISS was a big mantra of Unix sysadmins, and for a good reason: you can optimize simple things very well. Witness the simple (by comparison) dual core Apple A8 that doesn't require any magical scheduler or a binary translator (Denver) and yet beats everyone else in practical tests. It's disheartening that the likes of ARM and Nvidia don't seem to have learnt this.
tuxRoller - Thursday, February 12, 2015 - link
The article suggests that this (the scheduler) is work that Samsung (alone) should've done. I don't recall the author indicating that it's actually an unsolved problem in computer science (again, in a general purpose environment), as I indicated, BTW.big.LITTLE will certainly work best with such a scheduler, but even without you should expect to approach some efficiency that lies between the big and little cores. Even this half-hearted attempt isn't terribly worse than the android competition.
Andrei Frumusanu - Thursday, February 12, 2015 - link
Power collapse is proper power gating on the individual cores in their respective CPUIdle states, your link is outdated and does not apply to new generation ARM cores.tuxRoller - Thursday, February 12, 2015 - link
Do you have a reference?To the best of my knowledge linaro are still working on hotplug.
Also, for Linux, cpuidle refers to a specific governor that doesn't actually power down, but handles the c states, but it looks like arm uses it for suspension (http://events.linuxfoundation.org/sites/events/fil... slides 10 and 13).
Andrei Frumusanu - Friday, February 13, 2015 - link
CPUIdle is the kernel framework that manages the CPU's idle states, such as WFI (Clock gating), core power collapse, cluster power collapse. CPUIdle states are C-states, but "C-states" is an ACPI denomination that is rarely used on ARM CPUs.Hotplug has been left for dead for a long time, it hasn't been used for PM in ARM CPUs since the A15/A7 generation. Today it's only used for like forcing cores off when in screen-off states or rare coarse power management for like battery savings modes for some vendors.
sgmuser - Thursday, February 12, 2015 - link
I have Exynos and wanted that specifically for the Wolfson Audio. Sad to note that, its not exploited enough by Samsung.
Did someone notice the RAM bandwidth. How much impact that it makes?
Also, from personal experience, I find exynos seems to be smooth and never noticed lag for an user like me. Graphics performance could be better but again no visible issues for what I have been playing so far with such dense display.
giaf - Saturday, February 14, 2015 - link
Very interesting and detailed article, thank you.I have been working with ARMv7A cores, and I am interested in the floating-point capabilities of new 64-bit ARM processors. What is the throughput of the main floating-point instructions (add, mul, MAC) for Cortex A53 and A57? Something similar to the test done in http://www.anandtech.com/show/6971/exploring-the-f...
thegeneral2010 - Wednesday, February 18, 2015 - link
i just dont get it wat do u mean by "however it remains unclear whether we'll see this on the Note 4. My personal opinion remains that we won't be seeing this overhaul in Samsung's 5.0 Lollipop update." does this mean that exynos 5433 could be upgraded to 64bit on android 5.1 or later updates??Andrei Frumusanu - Friday, February 20, 2015 - link
At the time of the writing the Lolipop update was not yet released. Now it's out and it's not 64bit as I suspected. If they didn't update it now they won't ever update it and it will stay on AArch32.thegeneral2010 - Sunday, February 22, 2015 - link
so wat about that official patches in upstream linux?