The Google Nexus 9 Review
by Joshua Ho & Ryan Smith on February 4, 2015 8:00 AM EST- Posted in
- Tablets
- HTC
- Project Denver
- Android
- Mobile
- NVIDIA
- Nexus 9
- Lollipop
- Android 5.0
The Secret of Denver: Binary Translation & Code Optimization
As we alluded to earlier, NVIDIA’s decision to forgo a traditional out-of-order design for Denver means that much of Denver’s potential is contained in its software rather than its hardware. The underlying chip itself, though by no means simple, is at its core a very large in-order processor. So it falls to the software stack to make Denver sing.
Accomplishing this task is NVIDIA’s dynamic code optimizer (DCO). The purpose of the DCO is to accomplish two tasks: to translate ARM code to Denver’s native format, and to optimize this code to make it run better on Denver. With no out-of-order hardware on Denver, it is the DCO’s task to find instruction level parallelism within a thread to fill Denver’s many execution units, and to reorder instructions around potential stalls, something that is no simple task.
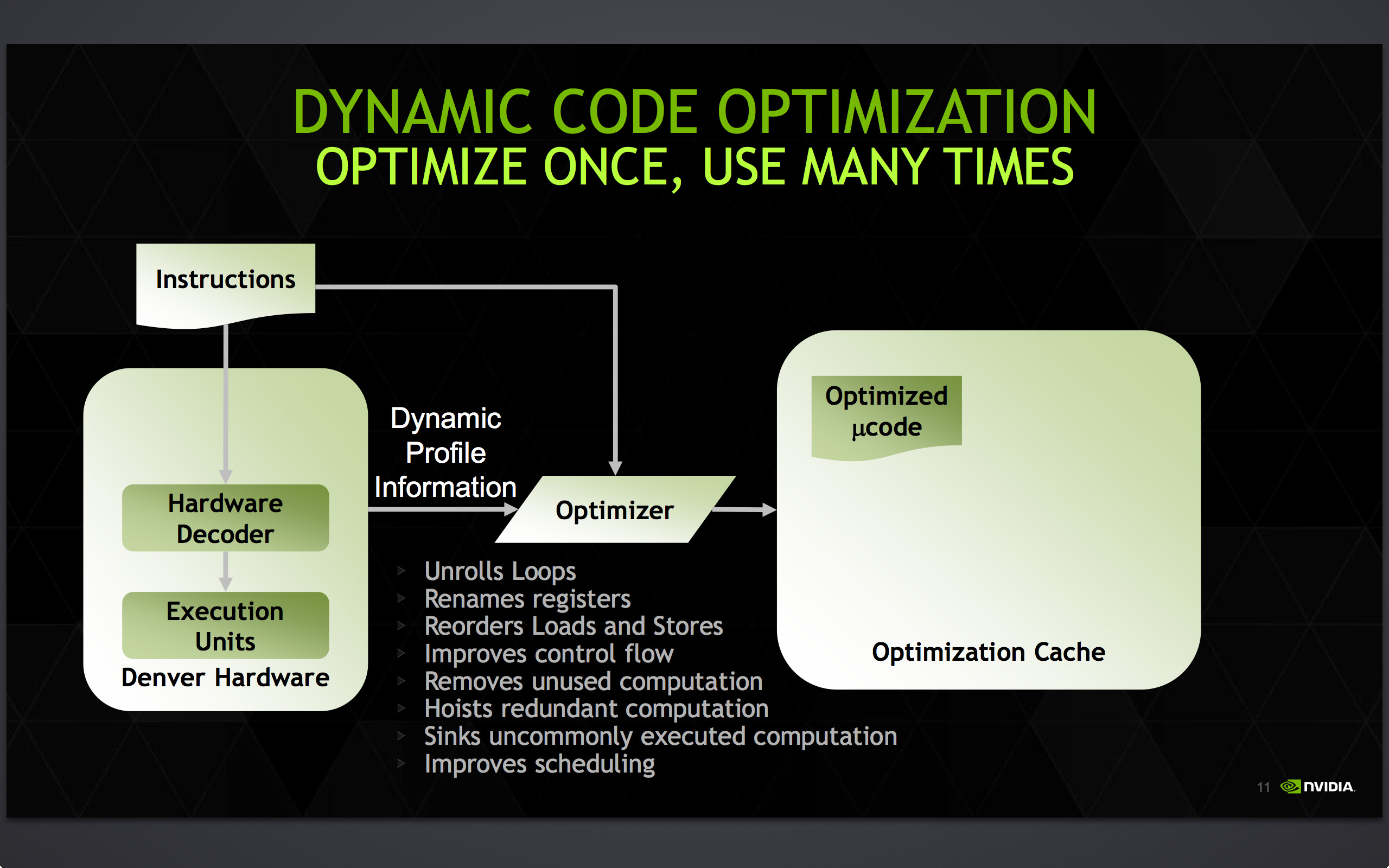
Starting first with the binary translation aspects of DCO, the binary translator is not used for all code. All code goes through the ARM decoder units at least once before, and only after Denver realizes it has run the same code segments enough times does that code get kicked to the translator. Running code translation and optimization is itself a software task, and as a result this task requires a certain amount of real time, CPU time, and power. This means that it only makes sense to send code out for translation and optimization if it’s recurring, even if taking the ARM decoder path fails to exploit much in the way of Denver’s capabilities.
This sets up some very clear best and worst case scenarios for Denver. In the best case scenario Denver is entirely running code that has already been through the DCO, meaning it’s being fed the best code possible and isn’t having to run suboptimal code from the ARM decoder or spending resources invoking the optimizer. On the other hand then, the worst case scenario for Denver is whenever code doesn’t recur. Non-recurring code means that the optimizer is never getting used because that code is never seen again, and invoking the DCO would be pointless as the benefits of optimizing the code are outweighed by the costs of that optimization.
Assuming that a code segment recurs enough to justify translation, it is then kicked over to the DCO to receive translation and optimization. Because this itself is a software process, the DCO is a critical component due to both the code it generates and the code it itself is built from. The DCO needs to be highly tuned so that Denver isn’t spending more resources than it needs to in order to run the DCO, and it needs to produce highly optimal code for Denver to ensure the chip achieves maximum performance. This becomes a very interesting balancing act for NVIDIA, as a longer examination of code segments could potentially produce even better code, but it would increase the costs of running the DCO.
In the optimization step NVIDIA undertakes a number of actions to improve code performance. This includes out-of-order optimizations such as instruction and load/store reordering, along register renaming. However the DCO also behaves as a traditional compiler would, undertaking actions such as unrolling loops and eliminating redundant/dead code that never gets executed. For NVIDIA this optimization step is the most critical aspect of Denver, as its performance will live and die by the DCO.
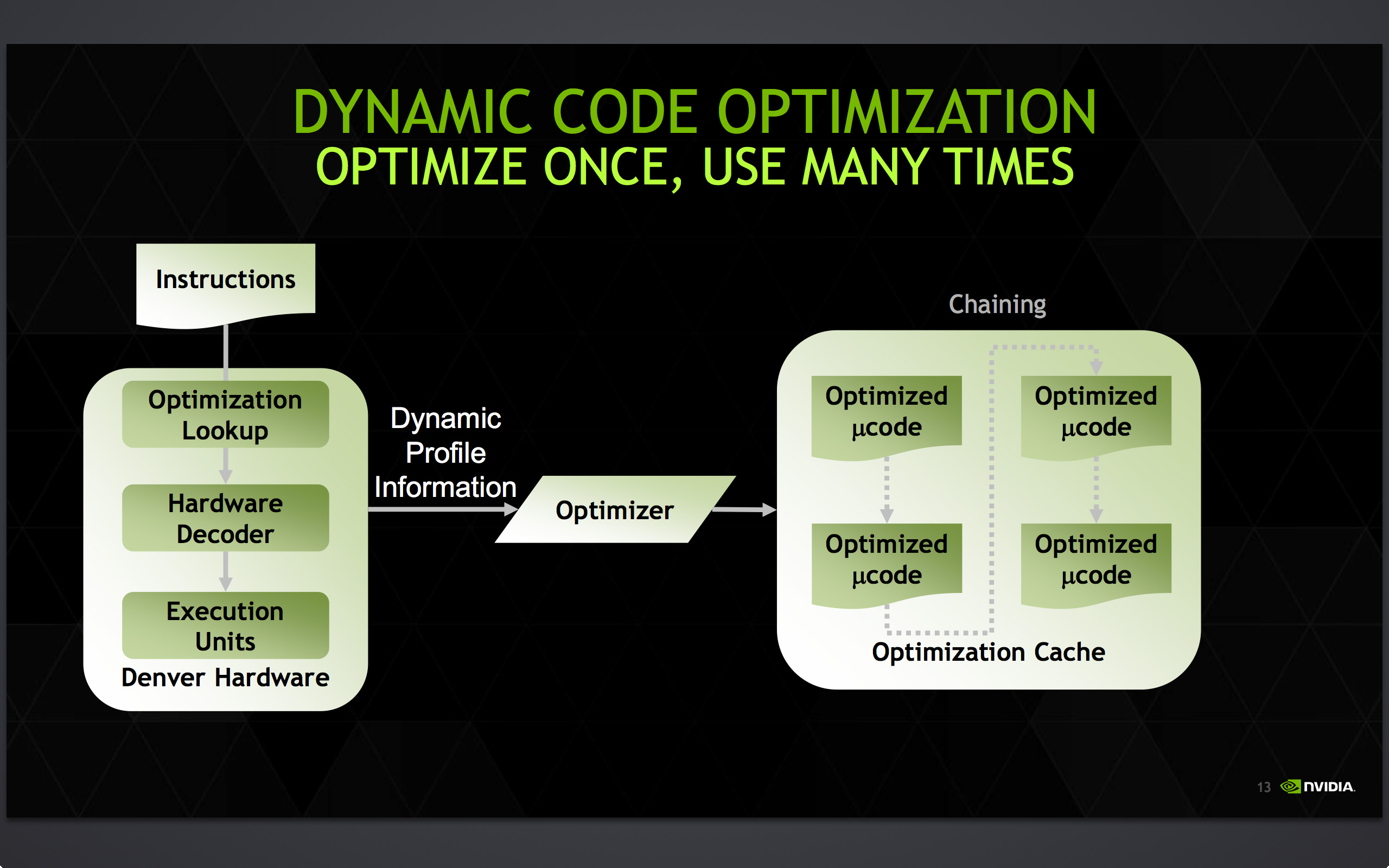
Denver's optimization cache: optimized code can call other optimized code for even better performance
Once code leaves the DCO, it is then stored for future use in an area NVIDIA calls the optimization cache. The cache is a 128MB segment of main memory reserved to hold these translated and optimized code segments for future reuse, with Denver banking on its ability to reuse code to achieve its peak performance. The presence of the optimization cache does mean that Denver suffers a slight memory capacity penalty compared to other SoCs, which in the case of the N9 means that 1/16th (6%) of the N9’s memory is reserved for the cache. Meanwhile, also resident here is the DCO code itself, which is shipped and stored as already-optimized code so that it can achieve its full performance right off the bat.
Overall the DCO ends up being interesting for a number of reasons, not the least of which are the tradeoffs are made by its inclusion. The DCO instruction window is larger than any comparable OoOE engine, meaning NVIDIA can look at larger code blocks than hardware OoOE reorder engines and potentially extract even better ILP and other optimizations from the code. On the other hand the DCO can only work on code in advance, denying it the ability to see and work on code in real-time as it’s executing like a hardware out-of-order implementation. In such cases, even with a smaller window to work with a hardware OoOE implementation could produce better results, particularly in avoiding memory stalls.
As Denver lives and dies by its optimizer, it puts NVIDIA in an interesting position once again owing to their GPU heritage. Much of the above is true for GPUs as well as it is Denver, and while it’s by no means a perfect overlap it does mean that NVIDIA comes into this with a great deal of experience in optimizing code for an in-order processor. NVIDIA faces a major uphill battle here – hardware OoOE has proven itself reliable time and time again, especially compared to projects banking on superior compilers – so having that compiler background is incredibly important for NVIDIA.
In the meantime because NVIDIA relies on a software optimizer, Denver’s code optimization routine itself has one last advantage over hardware: upgradability. NVIDIA retains the ability to upgrade the DCO itself, potentially deploying new versions of the DCO farther down the line if improvements are made. In principle a DCO upgrade not a feature you want to find yourself needing to use – ideally Denver’s optimizer would be perfect from the start – but it’s none the less a good feature to have for the imperfect real world.
Case in point, we have encountered a floating point bug in Denver that has been traced back to the DCO, which under exceptional workloads causes Denver to overflow an internal register and trigger an SoC reset. Though this bug doesn’t lead to reliability problems in real world usage, it’s exactly the kind of issue that makes DCO updates valuable for NVIDIA as it gives them an opportunity to fix the bug. However at the same time NVIDIA has yet to take advantage of this opportunity, and as of the latest version of Android for the Nexus 9 it seems that this issue still occurs. So it remains to be seen if BSP updates will include DCO updates to improve performance and remove such bugs.








169 Comments
View All Comments
seanleeforever - Wednesday, February 4, 2015 - link
2nd that.I am not here to read about how fast the tablet is or how nice it looks. i am here for in depth content about the chip. would it be nice that this content was available since the release of the product? absolutely, but given the resource it would either be a brief review that is going to be the same as review you can find from hundred of other websites, or late but in depth.
honestly i think anand should be targeting at more tech oriented contents that's few but in depth, and leave the quick/dirty review for other websites.
superb job.
WaitingForNehalem - Wednesday, February 4, 2015 - link
Yeah but who cares about tablets??!! I don't come to Anandtech to read about budget tablets, or SFF PCs, or more smartphones. The Denver coverage was not even that in depth TBH, just commentary on the NVidia slides. I have a EE degree and some of the previous write ups were so in depth they could be class material. This one isn't which is fine but I don't think it excuses how late it came out. The enthusiast market is growing and you should be targeting that demographic as you previously have, not catering to the mainstream like hundreds of sites already do.retrospooty - Wednesday, February 4, 2015 - link
The enthusiast market is growing ? What with CPU's not really getting, or needing to be any faster for several years now, and a standard mid range quad core i5 (non-overclocked) being WAY more than powerful enough to run 99.9% of anything out there, how is the enthusiast market is growing? Most enthusiasts I know don't even bother any more... There just isnt a need. Any basic PC is great these days.WaitingForNehalem - Wednesday, February 4, 2015 - link
I totally agree with you. That doesn't change the fact that the market is growing as more users are adopting gaming PCs. Enthusiasts now actually command a sizable portion of desktops sold. Intel's Devil's Canyon was in response to that.retrospooty - Thursday, February 5, 2015 - link
OK, I get what you mean.I guess I am still in a mind set where a PC "enthusiast" is your overclocker, tweaker, buying the latest and fastest of everything to eek out that extra few frames per second.
Today, a mid range quad core i5 from 3 years ago and a decent mid-high range card runs any game quite nicely.
FunBunny2 - Thursday, February 5, 2015 - link
There was a time, readers may be too young to have been there, when there was a Wintel monopoly: M$ needed faster chips to run ever more bloated Windoze and Intel needed a cycle-sink to soak up the increase in cycles that evolving chips provided. Now, we're near (or at?) the limits of single-threaded performance, and still haven't found a way to use multi-processor/core chips in individual applications. There just aren't a) many embarrassingly parallel problems and b) algorithms to turn single-threaded problems into parallel code. I mean, the big deal these days is 4K displays? It looks prettier, to some eyes, but doesn't change the functionality of an application (medical and such excepted, possibly).Does anyone really need an i7 to surf the innterTubes for neater porn?
nico_mach - Friday, February 6, 2015 - link
I think the chip coverage was superb, I don't have an EE degree and I'm pretty sure that's what the website is steered towards. And I still think I got it.It's fascinating the number of layers involved in this Android tablet, and speaks to why Apple can optimize so much better. There's the chip->NVIDIA chip optimizer->executable code->Dalvik compiler/runtime->dalvik code. I mean, when the lags are encountered, that's twice as many suspects to investigate.
I still think that the review is a little harsh on Denver. It's hitting the right performance envelope at the right price. While it's an mildly inefficient design, clearly NVIDIA is pricing it accordingly, and that might be a function of moving some of the optimization work to software. And that's work that Apple and MS do all the time - Apple much more successfully, obviously. There's a real gap in knowledge of how efficient Apple's chips are vs how optimized the software/hardware pairing is.
dakishimesan - Wednesday, February 4, 2015 - link
I have no interest in tablets, but the deep dive on Denver was a fascinating read, and still completely relevant even if the product is a few months old. Thanks for the great review.Sindarin - Wednesday, February 4, 2015 - link
...can I offer you a cup of hot chicken soup laddy? .....maybe some vicks vapor rub? lol! c'mon dude! we're all sick(vaca) in December!hahmed330 - Wednesday, February 4, 2015 - link
Hi, outstanding article with incredible attention to detail... Do you think its possible to run Dynamic Code Optimizer on per say 2 or maybe even 4 small cpu cores dedicated to doing all the software OoOE functions instead of using time slicing? (A53s or just some XYZ narrow cores for a potential 2+2 or 4+4 or maybe even 8+8)Also whats the die size of a denver core in comparison to a enhanced cyclone core?? That is where a lot of gains are possible potentially 30%-50%..